Реализация MapReduce в Greenplum Database
Для иллюстрации общей организации Greenplum Database воспользуемся рис. 1, позаимствованным из .
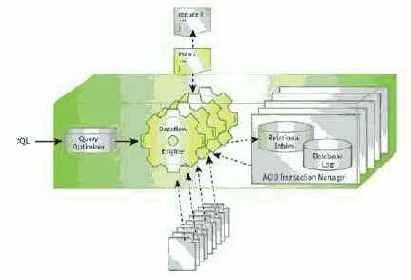
Рис. 1. Общая организация Greenplum Database
Как показывает этот рисунок, ядром системы является процессор потоков данных (Dataflow Engine). С его разработки началась реализация Greenplum Database, причем основные цели состояли в том, чтобы (a) заменить соответствующий компонент ядра PostgreSQL, чтобы обеспечить массивно-параллельное выполнение запросов и (b) обеспечить базовые функциональные возможности, требуемые для поддержки модели MapReduce. В результате SQL-ориентированная СУБД и MapReduce работают с общим ядром, поддерживающим массивно-параллельную обработку данных, и механизмы SQL и MapReduce обладают интероперабельностью.
Как отмечалось выше, функции Map и Reduce в среде Greenplum Database можно программировать на популярных скриптовых языках Python и Perl. В результате оказывается возможным использовать развитые программные средства с открытыми кодами, содержащиеся в репозиториях Python Package Index (PyPi) и Comprehensive Perl Archive Network (CPAN) . В составе этих репозиториев находятся средства анализа неструктурированного текста, статистические инструментальные средства, анализаторы форматов HTML и XML и многие другие программные средства, потенциально полезные аналитикам.
В среде Greenplum Database приложениям MapReduce обеспечивается доступ к данным, хранящимся в файлах, предоставляемым Web-сайтами и даже генерируемым командами операционной системы. Доступ к таким данным не влечет накладных расходов, ассоциируемых с использованием СУБД: блокировок, журнализации, фиксации транзакций и т.д. С другой стороны, эффективный доступ к данным, хранимым в базе данных, поддерживается за счет выполнения MR-программ в ядре Greenplum Database. Это позволяет избежать расходов на пересылку данных.
Архитектура Greenplum Database с равноправной поддержкой SQL и MapReduce позволяет смешивать стили программирования, делать MR-программы видимыми для SQL-запросов и наоборот. Например, можно выполнять MR-программы над таблицами базы данных. Для этого всего лишь требуется указать MapReduce, что входные данные программы должны браться из таблицы. Поскольку таблицы баз данных Greenplum Database хранятся разделенными между несколькими узлами кластера, первая фаза MAP выполняется внутри ядра СУБД прямо над этими разделами.
Как и в автономных реализациях MapReduce, результаты выполнения MR-программ могут сохраняться в файловой системе. Но настолько же просто сохранить результирующие данные в базе данных с обеспечением транзакционной долговечности хранения этих данных (см. компонент ACID Transaction Manager на рис. 1). В дальнейшем эти данные могут анализироваться, например, с применением SQL-запросов. Запись результирующих данных в таблицы происходит параллельным образом и не вызывает лишних накладных расходов.
Поскольку источником входных данных для MR-программы может служить любая таблица базы данных Greenplum, в частности, в качестве такой таблицы можно использовать представление базы данных, определенное средствами SQL. И наоборот, MR-программу можно зарегистрировать в базе данных как представление, к которому можно адресовать SQL-запросы. В этом случае MR-задание выполняется "на лету" во время обработки SQL-запроса, и результрующие данные в конвейерном режиме передаются прямо в план выполнения запроса.