Параллельные системы баз данных
В середине 1980-х гг. в проектах Teradata и Gamma были заложены основы парадигмы параллельных систем баз данных, которые базировались на кластерах недорогих компьютеров, называемых "узлами без общих ресурсов" ("shared-nothing nodes") (с собственными центральными процессорами, основной памятью и дисками). Эти узлы связываются высокоскоростным внутренним соединением . Во всех более поздних параллельных системах баз данных использовались, по существу, те же методы, что были впервые разработаны в этих двух проектах: горизонтальное распределение реляционных таблиц и разделяемое выполнение SQL-запросов.
Идея горизонтального разделения состоит в том, чтобы распределять строки реляционной таблицы по узлам кластера, чтобы их можно было обрабатывать параллельно. Например, при разделении таблицы с 10 миллионами строк в кластере из 50 узлов, в каждом из которых имеется четыре диска, на каждом из 200 дисков будет размещено 50000 строк. В большинстве параллельных систем баз данных поддерживаются разные стратегии разделения, включая хэш-разделение (hash-partitioning), разделение по диапазонам значений ключа (range-partitioning) и циклическое разделение (round-robin partitioning) . При применении хэш-разделения при загрузке каждой строки к значениям ее одного или нескольких атрибутов применяется хэш-функция, значение которой определяет целевой узел и диск, на котором должна быть сохранена эта строка.
Использование горизонтального разделения таблиц между узлами кластера является критическим для получения масштабируемой производительности SQL-запросов и естественным образом приводит к идее разделяемого выполнения операций SQL: селекции (selection), агрегации (aggregation), соединения (join), проекции (projection) и обновления (update). В качестве примера того, как разделение данных используется в параллельной СУБД, рассмотрим следующий SQL-запрос:
SELECT custId, amount FROM Sales WHERE date BETWEEN "12/1/2009" AND "12/25/2009";
Если строки таблицы Sales горизонтально разделены между узлами кластера, этот запрос можно тривиальным образом выполнить параллельно путем выполнения операции SELECT над записями Sales с применением заданного предиката в каждом узле кластера. Полученные в каждом узле промежуточные результаты затем посылаются в некоторый единственный узел, где выполняется операция MERGE, вырабатывающая окончательный результат, который возвращается в приложение, обратившееся с данным запросом.
Предположим, что нам требуется узнать общий объем продаж каждому покупателю (идентифицируемому своим custId) за установленный промежуток времени. Для этого можно использовать следующий запрос:
SELECT custId, SUM(amount) FROM Sales WHERE date BETWEEN "12/1/2009" AND "12/25/2009" GROUP BY custId;
Если таблица Sales циклически разделена между узлами кластера, то строки, соответствующие одному покупателю, будут разнесены по нескольким узлам. СУБД откомпилирует этот запрос в конвейер из трех операций, показанный на рис. 1(a), а затем параллельно выполнит этот план запроса во всех узлах кластера. Каждая операция SELECT сканирует фрагмент таблицы Sales, хранимый в данном узле. Все строки, удовлетворяющие предикату над датой, передаются операции SHUFFLE, которая динамически переразделяет строки. Это обычно делается путем применения некоторой хэш-функции к значению атрибута custId каждой строки для ее отображения на некоторый узел. Поскольку в операции SHUFFLE во всех узлах используется одна и та же хэш-функция, строки одного покупателя направляются в некоторый единственный узел, где они агрегируются для получения общего объема продаж данному покупателю.
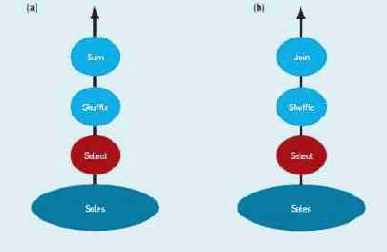
Рис. 1. Параллельные планы выполнения запросов к базе данных. (a) Примерный конвейер операций для вычисления агрегата на одной таблице. (b) Примерный конвейер операций для выполнения соединения двух разделенных таблиц.
В качестве последнего примера параллелизации SQL с использованием разделения данных рассмотрим запрос, который выдает имена и электронные адреса заказчиков, купивших товары на сумму больше $1000 в период рождественских каникул:
SELECT C.name, C.email FROM Customers C, Sales S WHERE C.custId = S.custId AND S.amount > 1000 AND S.date BETWEEN "12/1/2009" AND "12/25/2009";
Снова предположим, что таблица Sales разделена циклически, но пусть таблица Customers> хэш-разделена по атрибуту Customer.custId. СУБД откомпилирует этот запрос в конвейер операций, показанный на рис. 1(b), который выполняется параллельно во всех узлах кластера. Каждая операция SELECT сканирует соответствующий фрагмент таблицы Sales, отбирая строки, удовлетворяющие предикату
S.amount > 1000 AND S.date BETWEEN "12/1/2009" AND "12/25/2009".
Отобранные строки в конвейерном режиме отправляются операции SHUFFLE, которая переразделяет поступающие ей строки, хэшируя их по атрибуту Sales.custId. За счет использования той же хэш-функции, которая использовалась при загрузке строк таблицы Customers> (хэш-разделенной по атрибуту Customer.custId), операции SHUFFLE направляют каждую отобранную строку таблицы Sales в узел, где хранится соответствующая ей строка таблицы Customers>. Это позволяет параллельно во всех узлах выполнить операцию соединения (C.custId = S.custId).
Еще одно важное преимущество параллельных СУБД состоит в том, что система автоматически управляет различными альтернативными стратегиями разделения таблиц, над которыми выполняется запрос. Например, если обе таблицы Sales и Customers> были бы хэш-разделены по своим атрибутам custId, то оптимизатор запросов обнаружил бы, что обе таблицы хэш-разделены по атрибутам соединения, и не включил бы в план запроса операцию SHUFFLE. Аналогично, если бы обе таблицы были разделены циклически, то оптимизатор вставил бы в план операции SHUFFLE для обеих таблиц, чтобы соединяемые кортежи оказались в одном и том же узле. Все это делается прозрачным образом для пользователя и прикладных программ.
Доступно много коммерческих реализаций, включая Teradata, Netezza, DataAllegro (Microsoft), ParAccel, Greenplum, Aster, Vertica и DB2. Все они работают на кластерах, у узлов которых отсутствуют общие ресурсы; таблицы горизонтально разделяются между узлами.