Обратите внимание, что, согласно нашему
Обратите внимание, что, согласно нашему определению исключения как непредвиденной ошибки на этапе выполнения, в языке С «исключений» меньше, чем в таком языке, как Ada. Во-первых, такие ошибки, как выход за границы массива, не определены в языке С; они просто являются ошибками программиста, которые не могут быть «обработаны». Во-вторых, поскольку в С нет гибкого средства обработки исключений, каждая возможность языка, которая запрашивается через подпрограмму, возвращает код, указывающий, был запрос успешным или нет. Таким образом, в языке Ada распределение памяти с помощью new может вызвать исключительную ситуацию, если нет достаточного объема памяти, тогда как в С malloc возвращает код, который должен быть проверен явно. Выводы для стиля программирования следующие: в Ada можно использовать new обычным порядком, а обработку исключений проектировать независимо, в то время как в С полезно написать подпрограм-му-оболочку для malloc так, чтобы реакцию на исключительные ситуации можно было разработать и запрограммировать централизованно, вместо того чтобы разрешать каждому члену группы тестировать (или забывать тестировать) нехватку памяти:
void* get_memory(int n)
|
C |
void* p = malloc(n);
if (p == 0) /* Выделение памяти потерпело неудачу */
/* Сделайте что-нибудь или корректно
завершите работу */
return р;
}
11.2. Исключения в PL/I
PL/1 был первым языком, который содержал средство для обработки исклю-чительных ситуаций в самом языке — блок «при наступлении события» или, |коротко, «при» (on-unit). Он является блоком кода, который выполняется, ког-да возникает исключительная ситуация; после его завершения вычисление продолжается. Проблема в PL/1, связанная с блоком «при», состоит в том, что он влияет на обычные вычисления.
что активизирован блок, Срабатывающий при
Предположим, что активизирован блок, Срабатывающий при потере значимости с плавающей точкой. Тогда потенци-ально возможно воздействие на каждое выражение с плавающей точкой; дру-гими словами, каждое выражение с плавающей точкой содержит неявный вы-|зов блока и возврат из него. Это затрудняет выполнение оптимизации сохра-нения значений в регистрах или вынесения общих подвыражений.
11.3. Исключения в Ada
В языке Ada определен очень простой механизм обработки исключений, ко-
торый послужил моделью для других языков.
В Ada есть четыре предопределенных исключения:
Constraint_Error (ошибка ограничения). Нарушение ограничивающих ус-ловий, например, когда индексация массива выходит за границы или вы- бор вариантного поля не соответствует дискриминанту.
Storage_Error (ошибка памяти). Недостаточно памяти.
Program_Error (программная ошибка). Нарушение правил языка, напри-
мер выход из функции без выполнения оператора return.
Tasking_Error (ошибка задачи). Ошибки, возникающие при взаимодейст- вии задач
(см. гл. 12).
Конечно, Constraint_Error — наиболее часто встречающееся исключение, связанное со строгим контролем соответствия типов в языке Ada. Кроме того,
программист может объявлять исключения, которые обрабатываются точно
так же, как и предопределенные исключения.
Когда исключительная ситуация наступает, в терминологии языка Ada —возбуждается (raised), вызывается блок кода, называемый обработчиком исключения (exeption handler). В отличие от PL/I вызов обработчика завершает включающую процедуру. Так как обработчик не возвращается к нормальному вычислению, нет никаких помех для оптимизации. В отличие от обработчиков глобальных ошибок в С, обработка исключительных ситуаций в Ada чрезвычайно гибкая, потому что обработчики исключений могут быть привязаны к любой подпрограмме:
procedure Main is
procedure Proc is
P: Node_Ptr;
begin
end Proc; begin Proc; Statement_2;
P := new Node; -- Может возбуждаться исключение
Statement_1; -- Пропускается, если возбуждено исключение
exception
when Storage_Error =>
-- Обработчик исключения
end Proc; begin Proc; Statement_2; — Пропускается, если исключение распространилось
из Proc
exception
when Storage_Error =>
-- Обработчик исключения
end Main;
После последнего исполняемого оператора подпрограммы ключевое слово exception вводит последовательность обработчиков исключений — по одному для каждого вида исключений. Когда возбуждается исключение, процедура покидается, и вместо нее выполняется обработчик исключения. Когда обработчик завершает свою работу, выполняется нормальное завершение процедуры. В приведенном примере программа выделения памяти может породить исключительную ситуацию Storage_Error, в этом случае Statement_1 пропускается, и выполняется обработчик исключения. После завершения обработчика и нормального завершения процедуры главная программа продолжается с оператора Statement_2.
Семантика обработки исключений предоставляет программисту большую гибкость в управлении обработкой исключительных ситуаций:
• Если исключительная ситуация не обработана внутри процедуры, попытка ее выполнения оставляется, и исключительная ситуация возбуждается снова в точке вызова. При отсутствии обработчика в Proc исключение повторно было бы возбуждено в Main, оператор Statement_2 был бы пропущен и выполнен обработчик в Main.
• Если исключительная ситуация возбуждается во время выполнения обработчика, обработчик оставляется, и исключение возбуждается снова в точке вызова.
• У программиста есть выбор: возбудить то же самое или другое исключение в точке вызова. Например, мы могли бы перевести предопределенное исключение типа Storage_Error в исключение, определенное в прикладной программе. Это делается с помощью оператора rais в обработчике:
Обработчик для others может использоваться,
exception
when Storage_Error =>
… -- Обрабатывается исключение, затем
raise Overflow; --Возбуждается исключение Overflow в точке вызова
Обработчик для others может использоваться, чтобы обработать все исключения, которые не упомянуты в предыдущих обработчиках.
Если даже в главной программе нет обработчика для исключения, оно обрабатывается системой поддержки выполнения, которая обычно прерывает выполнение программы и выдает сообщение. Хорошим стилем программирования можно считать такой, при котором все исключения гарантированно обрабатываются хотя бы на уровне главной программы.
Определение исключений в языке Ada 83 не позволяло обработчику иметь доступ к информации о ситуации. Если более одной исключительной ситуации обрабатываются одинаково, никаким способом нельзя было узнать, что же именно произошло:
exception
when Ех_1 | Ех_2 | Ех_3 =>
--Какое именно исключение произошло?
Язык Ada 95 позволяет обработчику исключительной ситуации иметь параметр:
exception
when Ex: others =>
Всякий раз при возбуждении исключения параметр Ех будет содержать информацию, идентифицирующую исключение, а предопределенные процедуры позволят программисту отыскать информацию относительно исключения. Эта информация также может быть определена программистом (см. справочное руководство по языку, раздел 11.4.1).
Реализация
Реализуются обработчики исключений очень эффективно. Процедура, которая содержит обработчики исключений, имеет дополнительное поле в записи активации с указателем на обработчики (см. рис. 11.1). Требуется только одна команда при вызове процедуры, чтобы установить это поле, вот и все издержки при отсутствии исключений.

Если исключение возбуждается, то, чтобы найти обработчик, может потребоваться большой объем вычислений для поиска по динамической цепочке, но, поскольку исключения происходят редко, это не представляет проблемы.
Вспомните наш совет не использовать
Вспомните наш совет не использовать обработчик исключений как замену для гораздо более эффективного условного оператора.
11.4. Исключения в C++
Обработка исключений в C++ во многом сходна с той, которая применяется в языке Ada, а именно, исключение можно явно возбудить, обработать соответствующим обработчиком (если он есть), после чего блок (подпрограмма) окажется завершенным. Отличия в следующем:
• Вместо приписывания обработчика исключения к подпрограмме используется специальный синтаксис для указания группы операторов, к которым применяется обработчик.
• Исключения идентифицируются типом параметра, а не именем. Имеется специальный эквивалент синтаксиса others для обработки исключений, не упомянутых явно.
• Можно создавать семейства исключений, используя наследование (см. гл. 14).
• Если в языке Ada для исключения в программе не предусмотрен обработчик, то вызывается системный обработчик. В C++ программист может определить функцию terminate(), которая вызывается, когда исключение не обработано.
В следующем примере блок try идентифицирует область действия последовательности операторов, для которых обработчики исключений (обозначенные как catch-блоки) являются активными. Throw-оператор приводит к возбуждению исключений; в этом случае оно будет обработано вторым catch-блоком, так как строковый параметр throw-оператора соответствует параметру char* второго catch-блока:
void proc()
{
… // Исключения здесь не обрабатываются
try {
…
throw "Invalid data"; // Возбудить исключение
}
catch (int i) {
… // Обработчик исключения
}
catch (char *s) {
… // Обработчик исключения
}
catch (...) { // Прочие исключения
которое он не может видеть,
…. // Обработчик исключений
}
}
Как в Ada, так и в C++ допускается, чтобы обработчик вызывался для исключения, которое он не может видеть, потому что оно объявлено в теле пакета (Ada), или тип объявлен как private в классе (C++). Если исключение не обработано и в others (или ...), то оно будет неоднократно повторно возбуждаться до тех пор, пока, наконец, с ним не обойдутся как с необработанным исключением. В C++ есть способ предотвратить такую неопределенность поведения с помощью точного объявления в подпрограмме, какие исключительные ситуации она готова обрабатывать:
void proc() throw (t1 , t2, t3);
Такая спецификация исключений (exception specifications) означает, что отсутствующие в списке исключения, которые, возможно, будут возбуждаться, но не будут обрабатываться в ргос (или любой подпрограмме, вызванной из ргос), немедленно вызывут глобально определенную функцию unex-pectedQ вместо того, чтобы продолжать поиск обработчика. В больших системах эта конструкция полезна для документирования полного интерфейса подпрограмм, включая исключения, которые будут распространяться.
11.5. Обработка ошибок в языке Eiffei
Утверждения
В языке Eiffei подход к обработке исключений основан на концепции, что, прежде всего, ошибок быть не должно. Конечно, все программисты борются за это, и особенность языка Eiffei состоит в том, что в него включена поддержка определения правильности программы. Она основана на понятии утверждений (assertions), которые являются логическими формулами и обычно используются для формализации программы, но не являются непосредственно частью ее (см. раздел 2.2). Каждая подпрограмма, называемая рутиной (routine) в Eiffei, может иметь связанные с ней утверждения. Например, подпрограмма для вычисления результата (result) и остатка (remainder) целочисленного деления делимого (dividend) на делитель (divisor) была бы написана следующим образом:
какие выходные данные подпрограмма считает
integer_division(dividend, divisor, result, remainder: INTEGER) is
require
divisor > 0
do
from
result = 0; remainder = dividend;
invariant
dividend = result*divisor + remainder
variant
remainder
until
remainder < divisor
loop
remainder := remainder - divisor;
result := result + 1 ;
end
ensure
dividend = result*divisor + remainder;
remainder < divisor
end
Конструкция require (требуется) называется предусловием и специфицирует, какие выходные данные подпрограмма считает правильными. Конструкция do (выполнить) содержит выполняемые операторы, собственно и составляющие программу. Конструкция ensure (гарантируется) называется постусловием и содержит. условия, истинность которых подпрограмма обещает обеспечить, если будет выполнена конструкция do над данными, удовлетворяющими предусловию. В данном случае справедливость постусловия является достаточно тривиальным следствием инварианта (см. 6.6) и условия until.
На большем масштабе вы можете присоединить инвариант к классу (см. раздел 15.4). Например, класс, реализующий стек с помощью массива, включал бы инвариант такого вида:
invariant
top >= 0;
top < max;
Все подпрограммы класса должны гарантировать, что инвариант истинен, когда объект класса создан, и что каждая подпрограмма сохраняет истиность инварианта. Например, подпрограмма pop имела бы предусловие top> 0, в противном случае выполнение оператора:
top := top - 1
могло бы нарушить инвариант.
Типы перечисления
Инварианты применяются также, чтобы гарантировать безопасность типа, которая достигается в других языках использованием типов перечисления. Следующие объявления в языке Ada:
|
Ada |
Dial: Heat;
были бы записаны на языке Eiffel как обычные целые переменные с именованными константами:
Инвариант гарантирует, что бессмысленные присваивания
Dial: Integer;
Off: Integer is 0;
Low: Integer is 1;
Medium: Integer is 2;
High: Integer is 3;
Инвариант гарантирует, что бессмысленные присваивания не выполнятся:
invariant
Off <= Dial <= High
Последняя версия языка Eiffel включает уникальные константы (unigue constants), похожие на имена перечисления в том отношении, что их фактические значения присваиваются компилятором. Однако они по-прежнему остаются целыми числами, поэтому безопасность типа должна по-прежнему обеспечиваться с помощью утверждений: постусловие должно присоединяться к любой подпрограмме, которая изменяет переменные, чьи значения должны быть ограничены этими константами.
Проектирование по контракту
Утверждения — базовая компонента того, что язык Eiffel называет проектированием по контракту, в том смысле, что проектировщик подпрограммы заключает неявный контракт с пользователем подпрограммы: если вы обеспечите состояние, которое удовлетворяет предусловию, то я обещаю преобразовать состояние так, чтобы оно удовлетворяло постусловию. Точно так же класс поддерживает истинность своих инвариантов. Если контракты используются в системе повсеместно, то ничто никогда не может идти неправильно.
На практике, конечно, разработчик может потерпеть неудачу, пытаясь создать соответствующую контракту подпрограмму (либо потому, что операторы не удовлетворяют утверждениям, либо потому, что были выбраны неправильные утверждения). Для отладки и тестирования в реализации языка Eiffel для пользователя предусмотрена возможность запросить проверку утверждений при входе в подпрограмму и выходе из нее так, чтобы можно было остановить выполнение, если утверждение неверно.
Исключения
Подпрограммы Eiffel могут содержать обработчики исключений:
proc is
do
Когда возбуждается исключение, считается, что
… -- Может возбуждаться исключение
rescue
… -- Обработчик исключения
end;
Когда возбуждается исключение, считается, что подпрограмма потерпела неудачу, и выполняются операторы после rescue. В отличие от языка Ada, после завершения обработчика исключение порождается снова в вызывающей программе. Это эквивалентно завершению в Ada обработчика исключения raise-оператором, который повторно порождает в вызывающей подпрограмме то же самое исключение, которое заставило вызвать обработчик.
Мотивировка такого решения в предположении, что постусловие подпрограммы (и/или инвариант класса) удовлетворяются.
Если это не так, то вам, возможно, захочется получить уведомление, но уж наверняка вы не можете удовлетворить постусловие, т. е. потерпели неудачу при выполнении работы, которую заказала вам вызывающая подпрограмма. Другими словами, если.вам известно, как справиться с проблемой и удовлетворить постусловие, то предусмотрите это в подпрограмме. Это аналогично нашему совету не пользоваться исключениями вместо операторов if.
Обработчик исключения для помощи в решении возникших проблем может вносить некоторые изменения и запрашивать повторное выполнение подпрограммы с самого начала, если в него включено ключевое слово retry в качестве последнего оператора. Новая попытка может привести или не привести к успеху. Принципиально здесь то, что успешное выполнение — это нормальное завершение подпрограммы с выполненным постусловием. В противном случае ее выполнение терпит неудачу.
Обработчик исключений в языке Ada можно смоделировать в Eiffel следующим образом, хотя это идет вразрез с философией языка:
proc is
local
tried: Boolean; -- Инициализировано как false;
do
if not tried then
-- Обычная обработка
-- Порождает исключения
Чтобы не было двойного повтора
else
-- «Обработчик исключения»
end
rescue
if not tried then
tried := true; -- Чтобы не было двойного повтора
retry
end
end;
11.6. Упражнения
1. Пакет языка Ada. Исключения в Ada 95 определяют типы и подпрограммы для сопоставления информации с исключениями. Сравните эти конструкции с конструкциями throw и catch в C++.
2. Покажите, что исключение в языке Ada может быть порождено вне области действия исключения. (Подсказка: см. гл. 13.) Как можно обработать исключение, объявление которого не находится в области действия?
3. Покажите, как описание исключений на языке C++: void proc() throw(t1, t2, t3); может быть смоделировано с помощью многократных catch-блоков.
4. Изучите класс EXCEPTION в языке Eiffel и сравните его с обработчиком исключения в языке Ada.
Глава 12
Параллелизм
12.1. Что такое параллелизм?
Компьютеры с несколькими центральными процессорами (ЦП) могут выполнять несколько программ или компонентов одной программы параллельно. Вычисление, таким образом, может завершиться за меньшее время счета (количество часов), чем на компьютере с одним ЦП, с учетом затрат дополнительного времени ЦП на синхронизацию и связь. Несколько программ могут также совместно использовать компьютер с одним ЦП, так быстро переключая ЦП с одной программы на другую, что возникает впечатление, будто они выполняются одновременно. Несмотря на то, что переключение ЦП не реализует настоящую параллельность, удобно разрабатывать программное обеспечение для этих систем так, как если бы выполнение программ действительно происходило параллельно. Параллелизм — это термин, используемый для обозначения одновременного выполнения нескольких программ без уточнения, является вычисление параллельным на самом деле или только таким кажется.
Прямой параллелизм знаком большинству программистов
Прямой параллелизм знаком большинству программистов в следующих формах:
• Мультипрограммные (multi-programming) операционные системы дают возможность одновременно использовать компьютер нескольким пользователям. Системы разделения времени, реализованные на обычных больших машинах и миникомпьютерах, в течение многих лет были единственным способом сделать доступными вычислительные средства для таких больших коллективов, как университеты.
• Многозадачные (multi-tasking) операционные системы дают возможность одновременно выполнять несколько компонентов одной программы (или программ одного пользователя). С появлением персональных компьютеров мультипрограммные компьютеры стали менее распространенными, но даже одному человеку часто необходим многозадачный режим для одновременного выполнения разных задач, как, например, фоновая печать при диалоговом режиме работы с документом.
• Встроенные системы (embedded systems) на заводах, транспортных системах и в медицинской аппаратуре управляют наборами датчиков и приводов в «реальном масштабе времени». Для этих систем характерно требование, чтобы они выполняли относительно небольшие по объему вычисления через очень короткие промежутки времени: каждый датчик должен быть считан и проинтерпретирован, затем программа должна выбрать соответствующее действие, и, наконец, данные в определенном формате должны быть переданы к приводам. Для реализации встроенных систем используются многозадачные операционные системы, позволяющие координировать десятки обособленных вычислений.
Проектирование и программирование параллельных систем являются чрезвычайно сложным делом, и целые учебники посвящены различным аспектам этой проблемы: архитектуре систем, диспетчеризации задач, аппаратным интерфейсам и т. д. Цель этого раздела состоит в том, чтобы дать краткий обзор языковой поддержки параллелизма, который традиционно обеспечивался функциями операционной системы и аппаратурой.
concurent program) состоит из одного
Параллельная программа ( concurent program) состоит из одного или нескольких программных компонентов (процессов), которые могут выполняться параллельно. Параллельные программы сталкиваются с двумя проблемами:
Синхронизация. Даже если процессы выполняются одновременно, иногда один процесс должен будет синхронизировать свое выполнение с другими процессами. Наиболее важная форма синхронизации — взаимное исключение: два процесса не должны обращаться к одному и тому же ресурсу (такому, как диск или общая таблица) одновременно.
Взаимодействие. Процессы не являются полностью независимыми; они должны обмениваться данными. Например, в программе управления полетом процесс, считывающий показания датчика высоты, должен передать результат процессу, который делает расчеты для автопилота.
12.2. Общая память
Самая простая модель параллельного программирования — это модель с общей памятью (см. рис. 12.1). Два или несколько процессов могут обращаться к одной и той же области памяти, хотя они также могут иметь свою собственную частную, или приватную, (private) память. Предположим, что у нас есть два процесса, которые пытаются изменить одну и ту же переменную в общей памяти:
procedure Main is
N: Integer := 0;
task T1;
task T2;

task body T1 is
begin
for I in 1 ..100 loop N := N+1; end loop;
end T1;
task body T2 is
begin
for I in 1 ..100 loop N := N+1; end loop;
end T2;
begin
null;
end Main;
Рассмотрим теперь реализацию оператора присваивания:
load R1,N Загрузить из памяти
add R1,#1 Увеличить содержимое регистра
store R1,N Сохранить в памяти
Если каждое выполнение тела цикла в Т1 завершается до того, как Т2 выполняет свое тело цикла, N будет увеличено 200 раз. Однако каждая задача может быть выполнена на отдельном компьютере со своим набором регистров.
В этом случае может иметь
В этом случае может иметь место следующая последовательность событий:
• Т1 загружает N в свой регистр R1 (значение равно и).
• Т2 загружает N в свой регистр R1 (значение равно «).
• Т1 увеличивает R1 (значение равно п + 1).
• Т2 увеличивает R1 (значение равно и + 1).
• Т1 сохраняет содержимое своего регистра R1 в N (значение равно п + 1).
• Т2 сохраняет содержимое своего регистра R1 в N (значение равно п + 1).
Результат выполнения каждого из двух тел циклов состоит только в том, что N увеличится на единицу. Результирующее значение N может лежать между 100 и 200 в зависимости от относительной скорости каждого из двух процессоров.
Важно понять, что это может произойти даже на компьютере, который реализует многозадачный режим путем использования единственного ЦП. Когда ЦП переключается с одного процесса на другой, регистры, которые используются заблокированным процессом, сохраняются, а затем восстанавливаются, когда этот процесс продолжается.
В теории параллелизма выполнение параллельной программы определяется как любое чередование атомарных команд задач. Атомарная команда — это всего лишь команда, которую нельзя выполнить «частично» или прервать, чтобы продолжить выполнение другой задачи. В модели параллелизма с общей памятью команды загрузки и сохранения являются атомарными.
Если говорить о чередующихся вычислениях, то языки и системы, которые поддерживают параллелизм, различаются уровнем определенных в них атомарных команд. Реализация команды должна гарантировать, что она выполняется атомарно. В случае команд загрузки и сохранения это обеспечивается аппаратным интерфейсом памяти. Атомарность команд высокого уровня реализуется с помощью базисной системы поддержки времени выполнения и поддерживается специальными командами ЦП.
12.3. Проблема взаимных исключений
Проблема взаимных исключений (mutual exclusion problem) для параллельных программ является обобщением приведенного выше примера.
из параллельно выполняемых) вычисление делится
Предполагается, что в каждой задаче ( из параллельно выполняемых) вычисление делится на критическую (critical) и некритическую (non-critical) секцию (section), которые неоднократно выполняются:
task body T_i is
begin
loop
Prologue;
Critical_Section;
Epilogue;
Non_Critical_Section;
end loop;
end T_i:
Для решения проблемы взаимных исключений мы должны найти такие последовательности кода, называемые прологом (prologue) и эпилогом (epilogue), чтобы программа удовлетворяла следующим требованиям, которые должны выполняться для всех чередований последовательностей команд из набора задач:
Взаимное исключение. В любой момент времени только одна задача выполняет свою критическую секцию.
Отсутствие взаимоблокировки (no deadlock). Всегда есть, по крайней мере, одна задача, которая в состоянии продолжить выполнение.
Жизнеспособность. Если задаче необходимо выполнить критическую секцию, в конце концов она это сделает.
Справедливость. Доступ к критическому участку предоставляется «по справедливости».
Существуют варианты решения проблемы взаимных исключений, использующие в качестве атомарных команд только load (загрузить) и store (сохранить), но эти решения трудны для понимания и выходят за рамки данной книги, поэтому мы отсылаем читателя к учебникам по параллельному программированию.
Э. Дейкстра (E.W. Dijkstra) определил абстракцию синхронизации высокого уровня, называемую семафором, которая тривиально решает эту проблему. Семафор S является переменной, которая имеет целочисленное значение; для семафоров определены две атомарные команды:
Wait(S): when S > 0 do S := S -1;
Signal(S): S:=S+1;
Процесс, выполняющий команду Wait(S), блокируется на время, пока значение S неположительно. Обратите внимание, что, поскольку команда является атомарной, то, как только процесс удостоверится, что S положительно, он сразу уменьшит S (до того, как любой другой процесс выполнит команду!).
выполняется атомарно без возможности прерывания
Точно так же Signal(S) выполняется атомарно без возможности прерывания другим процессом между загрузкой и сохранением S. Проблема взаимных исключений решается следующим образом:
|
Ada |
S: Semaphore := 1 ;
task T_i; -- Одна из многих
task body T_i is
begin
loop
Wait(S);
Critical_Section;
Signal(S);
Non_Critical_Section;
end loop;
end T_i;
begin
null;
end Main;
Мы предлагаем читателю самостоятельно убедиться в том, что это решение является правильным.
Конечно, самое простое — это переложить бремя решения проблемы на разработчика системы поддержки этапа выполнения.
12.4. Мониторы и защищенные переменные
Проблема, связанная с семафорами и аналогичными средствами, обеспечиваемыми операционной системой, состоит в том, что они не структурны. Если нарушено соответствие между Wait и Signal, программа может утратить синхронизацию или блокировку. Для решения проблемы структурности была разработана концепция так называемых мониторов (monitors), и они реализованы в нескольких языках. Монитор — это совокупность данных и подпрограмм, которые обладают следующими свойствами:
• Данные доступны только подпрограммам монитора.
• В любой момент времени может выполняться не более одной подпрограммы монитора. Попытка процесса вызвать процедуру монитора в то время, как другой процесс уже выполняется в мониторе, приведет к приостановке нового процесса.
Поскольку вся синхронизация и связь выполняются в мониторе, потенциальные ошибки параллелизма определяются непосредственно программированием самого монитора; а процессы пользователя привести к дополнительным ошибкам не могут. Интерфейс монитора аналогичен интерфейсу операционной системы, в которой процесс вызывает монитор, чтобы запросить и получить обслуживание.
Синхронизация процессов обеспечивается автоматически. Недостаток
Синхронизация процессов обеспечивается автоматически. Недостаток монитора в том, что он является централизованным средством.
Первоначально модель параллелизма в языке Ada (описанная ниже в разделе 12.7) была чрезвычайно сложной и требовала слишком больших затрат для решения простых проблем взаимных исключений. Чтобы это исправить, в Ada 95 были введены средства, аналогичные мониторам, которые называются защищенными переменными (protected variables). Например, семафор можно смоделировать как защищенную переменную. Этот интерфейс определяет две операции, но целочисленное значение семафора рассматривает как приватное (private), что означает, что оно недоступно для пользователей семафора:
protected type Semaphore is
entry Wait;
procedure Signal;
private
Value: Integer := 1;
end Semaphore;
Реализация семафора выглядит следующим образом:
protected body Semaphore is
entry Wait when Value > 0 is
begin
|
Ada |
end Wait;
procedure Signal is
begin
Value := Value + 1 ;
end Signal;
end Semaphore;
Выполнение entry и procedure взаимно исключено: в любой момент времени только одна задача будет выполнять операцию с защищенной переменной. К тому же entry имеет барьер (barrier), который является булевым выражением. Задача, пытающаяся выполнить entry, будет заблокирована, если выражение имеет значение «ложь». Всякий раз при завершении защищенной операции все барьеры будут перевычисляться, и будет разрешено выполнение той задачи, барьер которой имеет значение «истина». В приведенном примере, когда Signal увеличит Value, барьер в Wait будет иметь значение «истина», и заблокированная задача сможет выполнить тело entry.
12.5. Передача сообщений
По мере того как компьютерные аппаратные средства дешевеют, распределенное программирование приобретает все большее значение.
биваются на параллельные компоненты, которые
Программы раз биваются на параллельные компоненты, которые выполняются на разных компьютерах. Модель с разделяемой памятью уже не годится; проблема синхронизации и связи переносится на синхронную передачу сообщений (synchronous message passing), изображенную на рис. 12.2. В этой модели канал связи с может существовать между любыми двумя процессами. Когда один процесс посылает сообщение m в канал, он приостанавливается до тех пор, пока другой процесс не будет готов его получить. Симметрично, процесс, который ожидает получения сообщения, приостанавливается, пока посылающий процесс не готов послать. Эта приостановка используется для синхронизации процессов.
Синхронная модель параллелизма может быть реализована в самом языке программирования или в виде услуги операционной системы: потоки (pipes),

гнезда (sockets) и т.д. Модели отличаются способами, которыми процессы адресуют друг друга, и способом передачи сообщений. Далее мы опишем три языка, в которых методы реализации синхронного параллелизма существенно различны.
12.6. Язык параллельного программирования оссаm
Модель синхронных сообщений была первоначально разработана Хоаром (С. A. R. Ноаге) в формализме, называющемся CSP (Communicating Sequential Processes — Взаимодействующие последовательные процессы). На практике он реализован в языке оссат, который был разработан для программирования транспьютеров — аппаратной многопроцессорной архитектуры для распределенной обработки данных.
В языке оссаm адресация фиксирована, и передача сообщений односторонняя, как показано на рисунке 12.2. Канал имеет имя и может использоваться только для отправки сообщения из одного процесса и получения его в другом:
CHAN OF INT с :
PAR
INT m:
SEQ
-- Создается целочисленное значение m
с! m
INT v:
SEQ
c? v
-- Используется целочисленное значение в v
с объявлено как канал, который
с объявлено как канал, который может передавать целые числа. Канал должен использоваться именно в двух процессах: один процесс содержит команды вывода (с!), а другой — команды ввода (с?).
Интересен синтаксис языка оссаm. В других языках режим выполнения «по умолчанию» — это последовательное выполнение группы операторов, а для задания параллелизма требуются специальные указания. В языке оссаm параллельные и последовательные вычисления считаются в равной степени важными, поэтому вы должны явно указать, используя PAR и SEQ, как именно должна выполняться каждая группа (выровненных отступами) операторов.
Хотя каждый канал связывает ровно два процесса, язык оссаm допускает, чтобы процесс одновременно ждал передачи данных по любому из нескольких каналов:
[10]CHAN OF INT с : -- Массив каналов
ALT i = O FOR 10
c[i] ? v
-- Используется целочисленное значение в v
Этот процесс ждет передачи данных по любому из десяти каналов, а обработка полученного значения может зависеть от индекса канала.
Преимущество коммуникации точка-точка состоит в ее чрезвычайной эффективности, потому что вся адресная информация «скомпилирована». Не требуется никаких других средств поддержки во время выполнения кроме синхронизации процессов и передачи данных; в транспьютерных системах это делается аппаратными средствами. Конечно, эта эффективность достигается за счет уменьшения гибкости.
12.7. Рандеву в языке Ada
Задачи в языке Ada взаимодействуют друг с другом во время рандеву (rendezvous). Говорят, что одна задача Т1 вызывает вход (entry) e в другой задаче Т2 (см. рис. 12.3). Вызываемая задача должна выполнить accept-оператор для этого входа:
accept Е(Р1: in Integer; P2: out Integer) do
…
end E;
Когда задача выполняет вызов входа, и есть другая задача, которая уже выполнила accept для этого входа, имеет место рандеву.
Вызывающая задача передает входные параметры
• Вызывающая задача передает входные параметры принимающей задаче и затем блокируется.
• Принимающая задача выполняет операторы в теле accept.
• Принимающая задача возвращает выходные параметры вызывающей задаче.
• Вызывающая задача разблокируется.
Определение рандеву симметрично в том смысле, что, если задача выполняет accept-оператор, но ожидаемого вызова входа еще не произошло, она

будет заблокирована, пока некоторая задача не вызывет вход для этого accept-оператора*.
Подчеркнем, что адресация осуществляется только в одном направлении: вызывающая задача должна знать имя принимающей задачи, но принимающая задача не знает имени вызывающей задачи. Возможность создания серверов (servers), т. е. процессов, предоставляющих определенные услуги любому другому процессу, послужила мотивом для выбора такого проектного решения. Задача-клиент (client) должка, конечно, знать название сервиса, который она запрашивает, в то время как задача-сервер предоставит сервис любой задаче, и ей не нужно ничего знать о клиенте.
Одно рандеву может включать передачу сообщений в двух направлениях, потому что типичный сервис может быть запросом элемента из структуры данных. Издержки на дополнительное взаимодействие, чтобы возвратить результат, были бы сверхмерными.
Механизм рандеву чрезвычайно сложен: задача может одновременно ждать вызова различных точек входа, используя select-оператор:
select
accept El do ... end El;
or
accept E2 do . . . end E2;
or
accept E3 do . . . end E3;
end select;
Альтернативы выбора в select могут содержать булевы выражения, называемые охраной (guards), которые дают возможность задаче контролировать, какие вызовы она хочет принимать. Можно задавать таймауты (предельные времена ожидания рандеву) и осуществлять опросы (для немедленной реакции в критических случаях). В отличие от конструкции ALT в языке оссаm, select-оператор языка Ada не может одновременно ожидать произвольного числа входов.
Обратите внимание на основное различие
Обратите внимание на основное различие между защищенными переменными и рандеву:
• Защищенная переменная — это пассивный механизм, а его операции выполняются другими задачами.
• accept-оператор выполняется задачей, в которой он появляется, то есть он выполняет вычисление от имени других задач.
Рандеву можно использовать для программирования сервера и в том случае, если сервер делает значимую обработку помимо связи с клиентом:
task Server is
begin
loop
select
accept Put(l: in Item) do
-- Отправить I в структуру данных
end Put;
or
accept Get(l: out Item) do
-- Достать I из структуры данных
end Get;
end select;
-- Обслуживание структуры данных
end loop;
end Server;
Сервер отправляет элементы в структуру данных и достает их из нее, а после каждой операции он выполняет дополнительную обработку структуры данных, например регистрирует изменения. Нет необходимости блокировать другие задачи во время выполнения этой обработки, отнимающей много времени.
В языке Ada чрезвычайно гибкий механизм параллелизма, но эта гибкость достигается ценой менее эффективной связи, чем коммуникации точка-точка в языке оссаm. С другой стороны, в языке оссаm фактически невозможно реализовать гибкий серверный процесс, так как каждый дополнительный клиентский процесс нуждается в отдельном именованном канале, а это требует изменения программы сервера.
12.8. Linda
Linda — это не язык программирования как таковой, а модель параллелизма, которая может быть добавлена к существующему языку программирования. В отличие от однонаправленной (Ada) или двунаправленной адресации (occam), Linda вообще не использует никакой адресации между параллельными процессами! Вместо этого процесс может по выбору отправить сообщение в глобальную кортежную область (Tuple Space). Она названа так потому, что каждое сообщение представляет собой кортеж, т.
ность из одного или нескольких
е. последователь ность из одного или нескольких значений, возможно, разных типов.
Например:
(True, 5.6, 'С', False)

— это четверной кортеж, состоящий из булева с плавающей точкой, символьного и снова булева значений.
Существуют три операции, которые обращаются к кортежной области:
out — поместить кортеж в кортежную область;
in — блокировка, пока не существует соответствующего кортежа, затем его удаление
(см. рис. 12.4);
read — блокировка, пока не существует соответствующего кортежа (но без удаления его).
Синхронизация достигается благодаря тому, что команды in и read должны определять сигнатуру кортежа: число элементов и их типы. Только если кортеж существует с соответствующей сигнатурой, может быть выполнена операция получения, иначе процесс будет приостановлен. Кроме того, один или несколько элементов кортежа могут быть заданы явно. Если значение задано в сигнатуре, оно должно соответствовать значению в той же самой позиции кортежа; если задан тип, он может соответствовать любому значению этого типа в данной позиции. Например, все последующие операторы удалят первый кортеж в кортежной области на рис. 12.4:
in(True, 5.6, 'С', False)
in(B: Boolean, 5.6, 'С', False)
in(True, F: Float, 'С', Ё2: Boolean)
Второй оператор in возвратит значение True в формальном параметре В; третий оператор in возвратит значения 5.6 в F и False — в В2.
Кортежная область может использоваться для диспетчеризации вычислительных работ для процессов, которые могут находиться на разных компьютерах. Кортеж ("job", J, С) укажет, что работу J следует назначить компьютеру С. Каждый компьютер может быть заблокирован в ожидании работы:
in("job", J: Jobs, 4); -- Компьютер 4 ждет работу
Задача диспетчеризации может «бросать» работы в кортежную область.
мощью формального параметра оператора out
С по мощью формального параметра оператора out можно указать, что безразлично, какой именно компьютер делает данную работу:
out("job", 6, С: Computers); -- Работа 6 для любого компьютера
Преимущество модели Linda в чрезвычайной гибкости. Обратите внимание, что процесс может поместить кортеж в кортежную область и завершиться;
только позднее другой процесс найдет этот кортеж. Таким образом, Linda-программа распределена как во времени, так и в пространстве (среди процес-сов, которые могут быть на отдельных ЦП). Сравните это с языками Ada и oссаm, которые требуют, чтобы процессы непосредственно связывались друг с другом. Недостаток модели Linda состоит в дополнительных затратах на поддержку кортежной области, которая требует потенциально неограниченной глобальной памяти. Хотя кортежная область и является глобальной, бы-ли разработаны сложные алгоритмы для ее распределения среди многих процессоров.
12.9. Упражнения
1. Изучите следующую попытку решать проблему взаимного исключения в рамках модели с разделяемой памятью, где В1 и В2 — глобальные булевы переменные с начальным значением «ложь»:
task body T1 is
|
Ada |
loop
B1 :=True;
loop
exit when not B2;
B1 := False;
B1 :=True;
end loop;
Critical_Section;
B1 := False;
Non_Critical_Section;
end loop;
end T1;
task body T2 is
begin
loop
B2 := True;
loop
exit when not B1;
B2 := False;
B2 := True;
end loop;
Critical_Section;
B2 := False:
Non_Critical_Section;
end loop;
end T2;
Каков смысл переменных В1 и В2? Могут ли обе задачи находиться в своих критических областях в какой-нибудь момент времени? Может ли программа блокироваться? Достигнута ли жизнеспособность?
Проверьте решение проблемы взаимного исключения
2. Проверьте решение проблемы взаимного исключения с помощью семафора. Покажите, что во всех чередованиях команд в любой момент времени в критической области может находиться не более одной задачи. Что можно сказать относительно взаимоблокировки, жизнеспособности и справедливости?
3. Что произойдет с решением проблемы взаимного исключения, если семафору задать начальное значение больше 1?
4. Попробуйте точно определить справедливость. Какая связь между справедливостью и приоритетом?
5. Как бы вы реализовали семафор?
6. Как диспетчер работ Linda обеспечивает, чтобы конкретная работа попадала на конкретный компьютер?
7. Напишите Linda-программу для умножения матриц. Получение каждого векторного произведения считайте отдельной «работой»; начальный процесс диспетчеризации заполняет кортежную область «работами»; рабочие процессы удаляют «работы» и возвращают результаты; заключительный процесс сбора удаляет и выводит результаты.
8. Переведите Linda-программу умножения матриц на язык Ada. Решите проблему дважды: один раз с отдельными задачами для диспетчера и сборщика и один раз в рамках единой задачи, которая выполняет обе функции в одном select-операторе.
4Программирование
больших
систем
Глава 13
Декомпозиция программ
И начинающие программисты, и руководители проектов, экстраполируя ту простоту и легкость, с какой один человек может написать отдельную программу, часто полагают, что разработать программную систему также просто. Нужно только подобрать группу программистов и поручить им работу. Однако существует глубокая пропасть между написанием (небольших) программ и созданием (больших) программных систем, и многие системы поставляются с опозданием, с большим количеством ошибок и обходятся в несколько раз дороже, чем по первоначальной оценке.
и инструментальными средствами, которые поддерживают
Разработка программного обеспечения (software engineering) имеет дело с методами организации и управления группами разработчиков, с системой обозначений и инструментальными средствами, которые поддерживают этапы процесса разработки помимо программирования. Они включают этапы технического задания, проектирования и тестирования программного обеспечения.
В этой и двух последующих главах мы изучим конструкции языков программирования, которые разработаны для того, чтобы поддерживать создание больших программных систем. Не вызывает сомнений компромисс: чем меньшую поддержку предлагает язык для разработки больших систем, тем больше потребность в методах, соглашениях и системах обозначений, которые являются внешними по отношению к самому языку. Так как язык программирования, несомненно, необходим, кажется разумным включить поддержку больших систем в состав самого языка и ожидать, что компилятор по возможности автоматизирует максимальную часть процесса разработки. Мы, разработчики программного обеспечения, всегда хотим автоматизировать чью-нибудь чужую работу, но часто приходим в состояние неуверенности перед тем, как включить автоматизацию в языки программирования.
Главная проблема состоит в том, как разложить большую программную систему на легко управляемые компоненты, которые можно разработать отдельно и собрать в систему, где все компоненты взаимодействовали бы друг с другом, как запланировано. Начнем обсуждение с элементарных «механических» методов декомпозиции программы и перейдем к таким современным понятиям, как абстрактные типы данных и объектно-ориентированное программирование, которые направляют проектировщика системы на создание семантически значимых компонентов.
Перед тем как начать обсуждение, сделаем замечание для читателей, которые только начинают изучать программирование. Понятия будут продемонстрированы на небольших примерах, которые может вместить учебник, и вам может показаться, что это всего лишь излишняя «бюрократия».
что поколениями программистов был пройден
Будьте уверены, что поколениями программистов был пройден тяжелый путь, доказывающий, что такая бюрократия необходима; разница только в одном, либо она определена и реализована внутри стандарта языка, либо изобретается и внедряется администрацией для каждого нового проекта.
13.1. Раздельная компиляция
Первоначально декомпозиция программ делалась исключительно для того, чтобы дать возможность программисту раздельно компилировать компоненты программы. Благодаря мощности современных компьютеров и эффективности компиляторов эта причина теперь не столь существенна, как раньше, но важно изучить раздельную компиляцию, потому что для ее поддержки часто используются те же самые возможности, что и для декомпозиции программы на логические компоненты. Даже в очень больших системах, которые нельзя создать без раздельной компиляции, декомпозиция на компоненты делается при проектировании программы и не имеет отношения к этапу компиляции. Поскольку программные компоненты обычно относительно невелики, лимитирующим фактором при внесении изменений в программы обычно оказывается время компоновки, а не компиляции.
Раздельная компиляция в языке Fortran
Когда был разработан Fortran, программы вводились в компьютер с помощью перфокарт, и не было никаких дисков или библиотек программ, которые известны сегодня.
Компилируемый модуль в языке Fortran идентичен выполняемому модулю, а именно подпрограмме, называемой сабрутиной (subroutine). Каждая сабрутина компилируется не только раздельно, но и независимо, и в результате одной компиляции не сохраняется никакой информации, которую можно использовать при последующих компиляциях.
Это означает, что не делается абсолютно никакой проверки на соответствие формальных и фактических параметров. Вы можете задать значение с плавающей точкой для целочисленного параметра. Более того, массив передается как указатель на первый элемент, и вызванная подпрограмма никак не может узнать размер массива или даже тип элементов.
к несуществующему фактическому параметру. Другими
Подпрограмма может даже попытаться обратиться к несуществующему фактическому параметру. Другими словами, согласование формальных и фактических параметров — задача программиста; именно он должен обеспечить, правильные объявления типов и размеров параметров, как в вызывающих, так и вызываемых подпрограммах.
Поскольку каждая подпрограмма компилируется независимо, нельзя совместно использовать глобальные объявления данных. Вместо этого определены общие (common) блоки:
subroutine S1
common /block1/distance(100), speed(100), time(100)
real distance, speed, time
…
end
Это объявление требует выделить 300 ячеек памяти для значений с плавающей точкой. Все другие объявления для этого же блока распределяются в те же самые ячейки памяти, поэтому, если другая подпрограмма объявляет:
subroutine S2
common /block1/speed(200), time(200), distance(200)
integer speed, time, distance
….
End
то две подпрограммы будут использовать различные имена и различные типы для доступа к одной и той же памяти! Отображение common-блоков друг на друга делается по их расположению в памяти, а не по именам переменных. Если для переменной типа real выделяется столько памяти, сколько для двух переменных типа integer, speed(8O) в подпрограмме S2 размещается в той же самой памяти, что и половина переменной distance(40) в S1. Эффект подобен неаккуратному использованию типов union в языке С или вариантных записей в языке Pascal.
Независимая компиляция и общие блоки вряд ли создадут проблемы для отдельного программиста, который пишет небольшую программу, но с большой вероятностью вызовут проблемы в группе из десяти человек; придется организовывать встречи или контроль, чтобы гарантировать, что интерфейсы реализованы правильно. Частичное решение состоит в том, чтобы использовать включаемые (include) файлы, особенно для общих блоков, но вам все равно придется проверять, что вы используете последнюю версию включаемого файла, и удостовериться, что какой-нибудь умный программист не игнорирует объявления в файле.
С отличается от других языков
Раздельная компиляция в языке С
Язык С отличается от других языков программирования тем, что понятие файла с исходным кодом появляется в определении языка и, что существенно, в терминах области действия и видимости идентификаторов. Язык С поощряет раздельную компиляцию до такой степени, что по умолчанию к каждой подпрограмме и каждой глобальной переменной можно обращаться отовсюду в программе.
Вначале немного терминологии: объявление вводит имя в программу:
void proc(void);
Имя может иметь много (идентичных) объявлений, но только одно из них будет также и определением, которое создает объект этого имени: отводит память для переменных или задает реализацию подпрограммы.
Следующий файл содержит главную программу main, а также определение глобальной переменной и объявление функции, имена которых по умолчанию подлежат внешнему связыванию:
/* File main.c */
int global; /* Внешняя по умолчанию */
int func(int); /* Внешняя по умолчанию */
int main(void)
{
global = 4;
return func(global);
}
В отдельном файле дается определение (реализация) функции; переменная global объявляется снова, чтобы функция имела возможность к ней обратиться:
/* File func.c */
extern int global; /* Внешняя, только объявление */
int func(int parm)
{
return parm + global:
}
Обратите внимание, что еще одно объявление func не нужно, потому что определение функции в этом файле служит также и объявлением, и по умолчанию она внешняя. Однако для того чтобы func имела доступ к глобальной переменной, объявление переменной дать необходимо, и должен использоваться спецификатор extern. Если extern не используется, объявление переменной global будет восприниматься как второе определение переменной. Произойдет ошибка компоновки, так как в программе запрещено иметь два определения для одной и той же глобальной переменной.
в том смысле, что результат
Компиляция в языке С независима в том смысле, что результат одной компиляции не сохраняется для использования в другой. Если кто-то из вашей группы случайно напишет:
/* File func.c */
extern float global; /* Внешняя, только объявление */
int func(int parm) /* Внешняя по умолчанию */
{
return parm + global;
}
программа все еще может быть откомпилирована и скомпонована, а ошибка произойдет только во время выполнения. На моем компьютере целочисленное значение 4, присвоенное переменной global в main, воспринимается в файле func.c как очень малое число с плавающей точкой; после обратного преобразования к целому числу оно становится нулем, и функция возвращает 4, а не 8.
Как и в языке Fortran, проблему можно частично решить, используя включаемые файлы так, чтобы одни и те же объявления использовались во всех файлах. И объявление extern для функции или переменной, и определение могут появиться в одном и том же вычислении. Поэтому мы помещаем все внешние объявления в один или несколько включаемых файлов, в то время как единственное определение для каждой функции или переменной будет содержаться не более чем в одном файле «.с»:
/* File main.h */
extern int global; /* Только объявление */
/* File func.h */
extern int func(int parm); /* Только объявление */
/* File main.c */
#include "main.h"
#include "func.h"
int global; /* Определение */
int main(void)
{
return func(global) + 7;
}
/* File func.c */
#include "main.h"
#include "func.h"
int func(int parm) /* Определение */
{
return parm + global;
}
Спецификатор static
Забегая вперед, мы теперь покажем, как в языке С можно использовать свойства декомпозиции для имитации конструкции модуля других языков.
обычно только некоторые из них
В файле, содержащем десятки глобальных переменных и определений подпрограмм, обычно только некоторые из них должны быть доступны вне файла. Каждому определению, которое не используется внешним образом, должен предшествовать спецификатор static (статический), который указывает компилятору, что объявленная переменная или подпрограмма известна только внутри файла:
static int g 1; /* Глобальная переменная только в этом файле */
int g2; /* Глобальная переменная для всех файлов */
static int f1 (int i) {...}; /* Глобальная функция только в этом файле */
intf2(int i) {...}; /* Глобальная функция для всех файлов */
Здесь уместно говорить об области действия файла (file scope), которая выступает в роли области действия модуля (module scope), используемой в других языках. Было бы, конечно, лучше, если бы по умолчанию принимался спецификатор static, а не extern; однако нетрудно привыкнуть приписывать к каждому глобальному объявлению static.
Источником недоразумений в языке С является тот факт, что static имеет другое значение, а именно он определяет, что время жизни переменной является всем временем выполнения программы. Как мы обсуждали в разделе 7.4, локальные переменные внутри процедуры имеют время жизни, ограниченное одним вызовом процедуры. Глобальные переменные, однако, имеют статическое время жизни, то есть они распределяются, когда программа начинается, и не освобождаются, пока программа не завершится. Статическое время жизни — нормальный режим для глобальных переменных; на самом деле, глобальные переменные, объявленные с extern, также имеют статическое время жизни!
Спецификатор static также можно использовать для локальных переменных, чтобы задать статическое время жизни:
void proc(void)
{
static bool first_time = true;
if (first_time) {
/* Операторы, выполняемые при первом вызове proc */
Подведем итог: все глобальные переменные
first_time = false;
}
….
}
Подведем итог: все глобальные переменные и подпрограммы в файле должны быть объявлены как static, если явно не требуется, чтобы они были доступны вне файла. В противном случае они должны быть определены в одном файле без какого-либо спецификатора и экспортироваться через объявление их во включаемом файле со спецификатором extern.
13.2. Почему необходимы модули?
В предыдущем разделе мы рассматривали декомпозицию программ с чисто механической точки зрения, исходя из желания раздельно редактировать и компилировать части программы в разных файлах. Начиная с этого раздела мы обсудим декомпозицию программы на компоненты, возникающие в соответствии со смысловой структурой проекта и, может быть, кроме того допускающие раздельную компиляцию. Но сначала давайте спросим, почему декомпозиция так необходима?
Вам, возможно, объясняли, что человеческий мозг в любой момент времени способен иметь дело только с небольшим объемом материала. В терминах программирования это обычно выражается в виде требования, чтобы отдельная подпрограмма была не больше одной «страницы». Считается, что подпрограмма является концептуальной единицей: последовательностью операторов, выполняющих некоторую функцию. Если подпрограмма достаточно мала, скажем от 25 до 100 строк, можно легко понять все связи между составляющими ее операторами.
Но, чтобы понять всю программу, мы должны понять связи между подпрограммами, которые ее составляют. По аналогии должны быть понятны программы, содержащие от 25 до 100 подпрограмм, что составляет от 625 до 10000 строк. Такой размер программ относительно невелик по сравнению с промышленными и коммерческими программными системами, содержащими 100000, если не миллион, строк. Опыт показывает, что 10000 строк, возможно, является верхним пределом для размера монолитной программы и что необходим новый механизм структурирования, чтобы создавать и поддерживать большие программные системы.
Стандартным термином для механизма структурирования
Стандартным термином для механизма структурирования больших программ является модуль (module), хотя два языка, на которых мы сосредоточили внимание, используют другие термины: пакеты (packages) в языке Ada и классы (classes) в языке C++. В стандарте языка Pascal не определено никакого метода раздельной компиляции или декомпозиции программ. Например, первый Pascal-компилятор был единой программой, содержащей свыше 8000 строк кода на языке Pascal. Вместо того чтобы изменять Pascal, Вирт разработал новый (хотя и похожий) язык, названный Modula, так как центральным понятием в нем является модуль. К сожалению, многие поставщики расширили язык Pascal несовместимыми модульными конструкциями, поэтому Pascal не годится для написания переносимого программного обеспечения. Поскольку модули очень важны для разработки программного обеспечения, мы сосредоточим обсуждение на языке Ada, в котором разработана изящная модульная конструкция — так называемые пакеты.
13.3. Пакеты в языке Ada
Основной идеей, лежащей в основе модулей вообще и пакетов Ada в частности, является то, что такие вычислительные ресурсы, как данные и подпрограммы, должны быть инкапсулированы в некий единый модуль. Доступ к компонентам модуля разрешается только в соответствии с явно специфицированным интерфейсом. На рисунке 13.1 показана графическая запись (называемая диаграммой Буча — Бухера), применяемая в разработках на языке Ada.
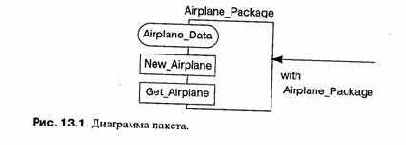
Большой прямоугольник обозначает пакет Airplane_Package, содержащий скрытые вычислительные ресурсы, а малые прямоугольники — окна, которые дают пользователю пакета доступ к скрытым ресурсам, овал обозначает, что экспортируется тип; а два прямоугольника — что экспортируются подпрограммы. Из каждого модуля, использующего ресурсы пакета, выходит стрелка, которая указывает на пакет.
Объявление пакета
Пакет состоит из двух частей: спецификации и тела. Тело инкапсулирует вычислительные ресурсы, а спецификация определяет интерфейс для этих ресурсов.
Пакет из следующего примера предназначается
Пакет из следующего примера предназначается для представления компонента системы управления воздушным движением, который хранит описание всех самолетов в контролируемом воздушном пространстве. Спецификация пакета объявляет тип и две подпрограммы интерфейса:
package Airplane_Package is
type Airplane_Data is
record
ID:String(1 ..80);
Speed: Integer range 0.. 1000;
Altitude: Integer range 0..100;
end record;
procedure New_Airplane(Data: in Airplane_Data; I: out Integer);
procedure Get_Airplane(l: in Integer; Data: out Airplane_Data);
end Airplane_Package;
Спецификация пакета содержит не тела, а только объявления процедур, заканчивающиеся точкой с запятой и вводимые зарезервированным словом is. Объявление служит только в качестве спецификации вычислительного ресурса, который предоставляет пакет.
В теле пакета должны быть обеспечены все ресурсы, которые были заявлены. В частности, для каждого объявления подпрограммы должно существовать тело подпрограммы с точно тем же самым объявлением:
package body Airplane_Package is
Airplanes: array(1..1000) of Airplane_Data;
Current_Airplanes: Integer range O..Airplanes'Last;
function Find_Empty_Entry return Integer is
begin
…
end Find_Empty_Entry;
procedure New_Airplane(Data: in Airplane_Data; I: out Integer) is
Index: Integer := Find_Empty_Entry;
begin
Airplanes(lndex) := Data;
I := Index;
end New_Airplane;
procedure Get_Airplane(l: in Integer; Data: out Airplane_Data) is
begin
Data := Airplanes(l);
end Get_Airplane;
end Airplane_Package;
Чего мы добились? Структура, применяемая для хранения данных о самолетах (здесь это массив фиксированного размера), инкапсулирована в тело пакета.
в теле пакета не требует
Правило языка Ada состоит в том, что изменение в теле пакета не требует изменений ни спецификации пакета, ни любого другого компонента программы, использующего пакет. Более того, не нужно даже их перекомпилировать. Например, если впоследствии вы должны заменить массив связанным списком, не нужно изменять никаких других компонентов системы при условии, что интерфейс, описанный в спецификации пакета, не изменился:
package body Airplane_Package is
type Node;
type Ptr is access Node;
type Node is
record
Info: Airplane_Data;
Next: Ptr;
end record;
Head: Ptr; . -- Начало связанного списка
procedure New_Airplane(Data: in Airplane_Data; I: out Integer) is
begin
… -- Новая реализация
end New_Airplane;
procedure Get_Airplane(l: in Integer; Data: out Airplane_Data) is
begin
… -- Новая реализация
end Get_Airplane;
end Airplane_Package;
Инкапсуляция делается не только для удобства, но и для надежности. Пользователям пакета не разрешен непосредственный доступ к данным или внутренним подпрограммам (таким, как Find_Empty_Entry) тела пакета. Таким образом, никакой другой программист из группы не может случайно (или преднамеренно) изменить структуру данных способом, который не был предусмотрен. Ошибка в реализации пакета обязательно локализована внутри кода тела пакета и не является результатом некоторого кода, написанного членом группы, не ответственным за пакет.
Спецификация и тело пакета — это разные модули, и их можно компилировать раздельно. Однако в терминах объявлений они рассматриваются как одна область действия, например, тип Airplain_Data известен внутри тела пакета. Это означает, конечно, что спецификация должна компилироваться перед телом. В отличие от языка С, здесь нет никакого понятия «файла», и объявления в языке Ada существуют только внутри такой единицы, как подпрограмма или пакет.
Несколько компилируемых модулей могут находиться
Несколько компилируемых модулей могут находиться в одном файле, хотя обычно удобнее хранить каждый модуль в отдельном файле.
Соглашение для написания программ на языке С, предложенное в предыдущем разделе, пытается имитировать инкапсуляцию, которая предоставляется пакетами в языке Ada. Включаемые файлы, содержащие внешние объявления, соответствуют спецификациям пакета и с помощью записи static для всех глобальных переменных и подпрограмм в файле достигается эффект тела пакета. Конечно, это всего лишь «бюрократический» прием, и его легко обой-ти, но это хороший способ структурирования программ в языке С.
Использование пакета
Программа на языке Ada (или другой пакет) может получить доступ к вычис- лительным ресурсам пакета, задав контекст (context clause) перед первой строкой программы:
with Airplane_Package;
procedure Air_Traffic_Control is
A: Airplane_Package.Airplane_Data;
Index: Integer;
begin
while... loop
A :=...; -- Создать запись
Airplane_Package. New_Airplane(A, Index):
-- Сохранить в структуре данных
end loop;
end Air_Traffic_Control;
With-конструкция сообщает компилятору, что эта программа должна компилироваться в среде, которая включает все объявления пакета Airplain_Package. Синтаксис для именования компонентов пакета аналогичен синтаксису для выбора компонентов записи. Поскольку каждый пакет должен иметь уникальное имя, компоненты в разных пакетах могут иметь одинаковые имена, и никакого конфликта не возникнет. Это означает, что управление пространством имен, т. е. набором имен, в программном проекте упрощено, и необходимо осуществлять контроль только на уровне имен пакетов. Сравните это с языком С, где идентификатор, который экспортируется из файла, видим во всех других файлах, потому недостаточно только обеспечить различие имен файлов.
и разрешить прямое именование компонентов,
With-конструкция добавляет составные имена к пространству имен компиляции; также можно включить use-конструкцию, чтобы открыть пространство имен и разрешить прямое именование компонентов, встречающихся в спецификации:
with Airplane_Package;
use Airplane_Package;
procedure Air_Traffic_Control is
A: Airplane_Data; -- Непосредственно видима
Index: Integer; begin
New_Airplane(A, Index): -- Непосредственно видима
end Air-Traffic-Control;
Одна трудность, связанная с use-конструкциями, состоит в том, что вы можете столкнуться с неоднозначностью, если use-конструкции для двух пакетов открывают одно и то же имя или если существует локальное объявление с тем же самым именем, что и в пакете. Правила языка определяют, каким в случае неоднозначности должен быть ответ компилятора.
Важнее, однако, то, что модуль, в котором with- и use-конструкции связаны с множеством пакетов, может стать практически нечитаемым. Такое имя, как Put_Element, могло бы исходить почти из любого пакета, в то время как местоположение Airplane_Package.Put_Element вполне очевидно. Ситуация аналогична программе, написанной на языке С, в которой много включаемых файлов: у вас просто нет удобного способа отыскивать объявления, и единственное решение — использовать внешний программный инструмент или соглашения о наименованиях.
Программистам, пишущим на языке Ada, следует использовать преимущества самодокументирования модулей за счет with, a use-конструкции применять только в небольших сегментах программы, где все вполне очевидно, а полная запись была бы чересчур утомительна. К счастью, можно поместить use-конструкции внутри локальной процедуры:
procedure Check_for_Collision is
use Airplane_Package;
A1: Airplane-Data;
begin
Get_Airplane(1, A1);
end Check_for_Collision;
В большинстве языков программирования импортирующий модуль автоматически получает все общие (public) ресурсы импортированного модуля.
торых языках, подобных языку Modula,
В неко торых языках, подобных языку Modula, импортирующему модулю разрешается точно определять, какие ресурсы ему требуются. Этот метод позволяет избежать перегрузки пространства имен, вызванной включающим характером use-конструкции в языке Ada.
Порядок компиляции
with-конструкции определяют естественный порядок компиляции: спецификация пакета должна компилироваться перед телом и перед любым модулем, который связан с ней через with. Однако упорядочение является частичным, т. е. порядок компиляции тела пакета и единиц, которые используют пакет, может быть любым. Вы можете исправить ошибку в теле пакета или в использующей его единице, перекомпилировав только то, что изменилось, но изменение спецификации пакета требует перекомпиляции как тела, так и всех использующих его единиц. В очень большом проекте следует избегать изменений спецификации пакетов, потому что они могут вызвать лавину перекомпиляций: Р1 используется в Р2, который используется в РЗ, и т. д.
Тот факт, что компиляция одной единицы требует результатов компиляции других единиц, означает, что в языке Ada компилятор должен содержать библиотеку для хранения результатов компиляции. Библиотека может быть просто каталогом, содержащим порожденные файлы, или сложной базой данных. При использовании любого метода библиотечный администратор является центральным компонентом реализации языка Ada, а не просто необязательным программным инструментом. Библиотечный администратор языка Ada проводит в жизнь правило, согласно которому при изменении спецификации пакета необходимо перекомпилировать тело и использующие его единицы. Таким образом, компилятор языка Ada уже включает инструмент сборки программы (make) с перекомпиляцией измененных модулей, который в других средах программирования является необязательной утилитой, а не частью языковых средств.
13.4. Абстрактные типы данных в языке Ada
Airplane_Package — это абстрактный объект данных. Он является абстрактным, потому что пользователь пакета не знает, реализована ли база данных самолетов как массив, список или как дерево.
в спецификации пакета интерфейсные процедуры,
Доступ к базе данных осуществляется только через объявленные в спецификации пакета интерфейсные процедуры, которые позволяют пользователю абстрактно создавать и отыскивать значение типа Airplane_Data, не зная, в каком виде оно хранится.
Пакет является объектом данных, потому что он действительно содержит данные: массив и любые другие переменные, объявленные в теле пакета. Правильно рассматривать Airplane_Package как особую* переменную: для нее должна быть выделена память и есть некоторые операции, которые могут изменить ее значение. Это объект не первого класса", потому что он не имеет всех преимуществ обычных переменных: нельзя делать присваивание пакету или передавать пакет как параметр.
Предположим теперь, что мы нуждаемся в двух таких базах данных: одна для смоделированного пульта управления воздушным движением и одна для администратора сценария моделирования, который вводит и инициализирует новые самолеты. Можно было бы написать два пакета с незначительно отличающимися именами или написать родовой пакет и дважды его конкретизировать, но это очень ограниченные решения. Что мы действительно хотели бы сделать, так это объявить столько таких объектов, сколько нам нужно, так же как мы объявляем целые числа. Другими словами, мы хотим иметь возможность конструировать абстрактный тип данных (Abstract Data Type — ADT), который является точно таким же, как и абстрактный объект данных, за исключением того что он не содержит никаких «переменных». Вместо этого, подобно другим типам, ADT определяет набор значений и набор операций на этих значениях, а фактическое объявление переменных этого типа может быть сделано в других компонентах программы.
ADT в языке Ada — это пакет, который содержит только объявления констант, типов и подпрограмм. Спецификация пакета включает объявление типа так, что другие единицы могут объявлять один или несколько объектов типа Airplains (самолеты):
package Airplane_Package is
in out Airplanes; Data: in
type Airplane_Data is ... end record;
type Airplanes is
record
Database: array( 1.. 1000) of Airplane_Data;
Current_Airplanes: Integer O..Database'Last;
end record;
procedure New_Airplane(
A: in out Airplanes; Data: in Airplane_Data: I: out Integer);
procedure Get_Airplane(
A: in out Airplanes; I: in Integer; Data: out Airplane_Data);
end Airplane_Package;
Тело пакета такое же, как и раньше, за исключением того что в нем нет никаких глобальных переменных:
package body Airplane_Package is
function Find_Empty_Entry... ;
procedure New_Airplane...;
procedure Get_Airplane...;
end Airplane_Package;
Программа, которая использует пакет, может теперь объявить одну или несколько переменных типа, поставляемого пакетом. Фактически тип является обычным типом и может использоваться в последующих определениях типов и как тип параметра:
with Airplane_Package;
procedure Air_Traffic_Control is
Airplane: Airplane_Package.Airplanes;
-- Переменная ADT
type Ptr is access Airplane_Package.Airplanes;
-- Тип с компонентом ADT
procedure Display(Parm: in Airplane_Package.Airplanes);
-- Параметр ADT
A: Airplane_Package.Airplane_Data;
Index: Integer;
begin
A .:=... ;
Airplane_Package.New_Airplane(Airplane, A, Index);
Display(Airplane);
end Air_Traffic_Control;
За использование ADT вместо абстрактных объектов данных придется заплатить определенную цену: так как в теле пакета больше нет ни одного неявного объекта, каждая интерфейсная процедура должна содержать дополнительный параметр, который явно сообщает подпрограмме, какой именно объект нужно обработать.
Вы можете спросить: а как насчет «абстракции»? Поскольку тип Airplaines теперь объявлен в спецификации пакета, мы потеряли все абстракции; больше нельзя изменить структуру данных, не повлияв на другие единицы, использующие пакет.
нибудь из группы программистов может
Кроме того, кто- нибудь из группы программистов может скрытно проигнорировать процедуры интерфейса и написать «улучшенный» интерфейс. Мы должны найти решение, в котором имя типа находится в спецификации так, чтобы его можно было использовать, а детали реализации инкапсулированы — что-нибудь вроде следующего:
package Airplane_Package is
type Airplane_Data is ... end record;
type Airplanes; -- Неполное объявление типа
end Airplane_Package;
package body Airplane_Package is
type Airplanes is -- Полное объявление типа
record
Database: array(1..1000) of Airplane_Data;
Current_Airplanes: Integer 0...Database'Last;
end record;
…
end Airplane_Package;
Потратьте несколько минут, чтобы проанализировать этот вариант самостоятельно перед тем, как идти дальше.
Что касается пакета, то с этими объявлениями нет никаких проблем, потому что спецификация и тело формируют одну область объявлений. Проблемы начинаются, когда мы пробуем использовать пакет:
with Airplane_Package;
procedure Air_Traffic_Control is
Airplane_1: Airplane_Package.Airplanes;
Airplane_2: Airplane_Package.Airplanes;
…
end Air_Traffic_Control;
Язык Ada задуман так, что компиляции спецификации пакета достаточно, чтобы сделать возможной компиляцию любой единицы, использующей пакет. Фактически, не нужно даже, чтобы существовало тело пакета, когда компилируется использующая единица. Но чтобы откомпилировать приведенную выше программу, компилятор должен знать, сколько памяти нужно выделить для Airplane_1 и Airplane_2; аналогично, если эта переменная используется в выражении или передается как параметр, компилятор должен знать размер переменной. Таким образом, если представление ADT инкапсулировано в тело пакета, откомпилировать программу будет невозможно.
с реальными языками программирования, которые
Приватные (private) типы
Поскольку мы имеем дело с реальными языками программирования, которые должны компилироваться, не остается ничего другого, кроме как вернуть полную спецификацию типа в спецификацию пакета. Чтобы достичь абстракции, используется комбинация самообмана и правил языка:
package Airplane_Package is
type Airplane_Data is ... end record;
type Airplanes is private;
-- Детали будут заданы позже
procedure New_Airplane(Data: in Airplane_Data; I: out Integer);
procedure Get_Airplane(I: in Integer; Data: out Airplane_Data);
private
type Airplanes is -- Полное объявление типа
record
Database: array(1 ..1000) of Airplane_Data;
Current_Airplanes: Integer 0.. Database'Last;
end record;
end Airplane_Package;
Сам тип первоначально объявлен как приватный (private), в то время как полное объявление типа записано в специальном разделе спецификации пакета, который вводится ключевым словом private. Тип данных абстрактный, потому что компилятор предписывает правило, по которому единицам, обращающимся к пакету через with, не разрешается иметь доступ к информации, записанной в закрытой (private) части. Им разрешается обращаться к приватному типу данных только через подпрограммы интерфейса в открытой (public) части спецификации; эти подпрограммы реализованы в теле, которое может иметь доступ к закрытой части. Так как исходный код использующих единиц не зависит от закрытой части, можно изменить объявления в закрытой части, не нарушая правильности исходных текстов использующих единиц; но, конечно, нужно будет сделать перекомпиляцию, потому что изменение в закрытой части могло привести к изменению выделяемого объема памяти.
Поскольку вы не можете явно использовать информацию из закрытой части, вы должны «сделать вид», что не можете ее даже видеть.
нет смысла прикладывать особые усилия
Например, нет смысла прикладывать особые усилия в написании чрезвычайно эффективных алгоритмов, зная, что приватный тип реализован как массив, а не как список, потому что руководитель проекта может, в конечном счете, изменить реализацию.
Ограниченные типы
Достаточно объявить объект (переменную или константу) приватного типа, и над ним можно будет выполнять операции присваивания и проверки на равенство, так как эти операции выполняются поразрядно независимо от внутренней структуры. Существует, однако, концептуальная проблема, связанная с разрешением присваивания и проверки равенства. Предположим, что в реализации массив заменен на указатель:
package Airplane_Package is
type Airplanes is private;
…
private
type Airplanes_jnfo is
record
Database: array(1..1000) of Airplane_Data;
Current_Airplanes: Integer O..Database'Last;
end record;
type Airplanes is access Airplanes_info;
end Airplane_Package;
Мы обещали, что при изменении закрытой части не потребуется менять использующие единицы, но здесь это не так, потому что присваивание делается для указателей, а не для указуемых объектов:
with Airplane_Package;
procedure Air_Traffic_ControI is
Airplane_1: Airplane_Package.Airplanes;
Airplane_2: Airplane_Package.Airplanes;
begin
Airplane_1 := Airplane_2; -- Присваивание указателей
end Air_Traffic_Control;
Если присваивание и проверка равенства не имеют смысла (например, при сравнении двух массивов, которые реализуют базы данных), язык Ada позволяет вам объявить приватный тип как ограниченный (limited). Объекты ограниченных типов нельзя присваивать или сравнивать, но вы можете явно написать свои собственные версии для этих операций. Это решит только что описанную проблему; при преобразовании между двумя реализациями можно изменить в теле пакета явный код для присваивания и равенства, чтобы гарантировать, что эти операции по-прежнему имеют смысл.
Неограниченными приватными типами следует оставить
Неограниченными приватными типами следует оставить лишь «небольшие» объекты, которые, вероятно, не подвергнутся другим изменениям, кроме добавления или изменения поля в записи.
Обратите внимание, что если приватный тип реализован с помощью указателя, то в предположении, что все указатели представлены одинаково, уже не важно, каков тип указуемого объекта. В языке Ada такое предположение фактически делается и, таким образом, указуемый тип может быть определен в теле пакета. Теперь изменение структуры данных благодаря косвенности доступа не требует даже перекомпиляции единиц с конструкцией with:
package Airplane_Package is
type Airplanes is private;
…
private
type Airplanes_info; -- Незавершенное объявление типа
type Airplanes is access Airplanes_info;
end Airplane_Package;
package body Airplane_Package is
type Airplanes_info is -- Завершение в теле
record
Database: array(1..1000) of Airplane_Data;
Current_Airplanes: Integer O..Database'Last;
end record;
end Airplane_Package;
ADT является мощным средством структурирования программ благодаря четкому отделению спецификации от реализации:
• Используя ADT, можно делать серьезные изменения в отдельных компонентах программы надежно, не вызывая ошибок в других частях программы.
• ADT может использоваться как инструмент управления разработкой: архитектор проекта разрабатывает интерфейсы, а каждый член группы программистов реализует один или несколько ADT.
• Можно выполнить тестирование и частичную интеграцию, применяя вырожденные реализации отсутствующих тел пакетов.
В главе 14 мы подробнее поговорим о роли ADT как основы объектно-ориентированного программирования.
13.5. Как писать модули на языке C++
Язык C++ — это расширение языка С, и поэтому здесь тоже существует понятие файла как единицы структурирования программ.
в отличие от языка Ada,
Наиболее важным расширением является введение классов (classes), которые непосредственно реализуют абстрактные типы данных, в отличие от языка Ada, который использует комбинацию из двух понятий: пакета и приватного типа данных. В следующей главе мы обсудим объектно-ориентированное программирование, которое основано на классах; а в этом разделе объясним основные понятия клас-
сов и покажем, как они могут использоваться для определения модулей.
Класс аналогичен спецификации пакета, которая объявляет один или не-
сколько приватных типов:
class Airplanes {
public:
struct Airplane_Data {
char id[80];
int speed;
int altitude;
};
void new_airplane(const Airplane_Data & a, int & i);
void get_airplane(int i, Airplane_Data & a) const;
private:
Airplane_Data database[1000];
int current_airplanes;
int find_empty_entry();
};
Обратите внимание, что имя класса, которое является именем типа, также служит в качестве имени инкапсулирующей единицы; никакого самостоятельного имени модуля не существует. Класс имеет общую и закрытую части. По умолчанию компоненты класса являются приватными, поэтому перед общей частью необходим спецификатор public. Фактически, при помощи спецификаторов public и private можно задать несколько открытых и закрытых частей вперемежку, в отличие от языка Ada, который требует, чтобы для каждой части был только один список объявлений:
class С {
public:
…
private:
…
public:
….
private:
…..
};
Объявления в общей части доступны любым модулям, использующим этот класс, в то время как объявления в закрытой части доступны только внутри класса. Спецификатор const в get_airplane — это следующее средство управления, он означает, что подпрограмма не изменяет никакие данные внутри объекта класса. Такие подпрограммы называются инспекторами (inspectors).
Поскольку класс является типом, могут быть объявлены объекты (константы и переменные) этого класса, так называемые экземпляры класса:
и тип параметра. Для каждого
Airplanes Airplane; // Экземпляр класса Airplanes
int index;
Airplanes::Airplane_Data a;
Airplane.new_airplane(a, index); // Вызов подпрограммы для экземпляра
Классом может быть и тип параметра. Для каждого экземпляра будет выделена память всем переменным, объявленным в классе, точно так же, как для переменной типа запись выделяется память всем полям.
Синтаксис вызова подпрограммы отличается от синтаксиса, принятого в языке Ada, из-за различий в исходных концепциях. Вызов в языке Ada:
Airplane_Package.New_Airplane(Airplane, A, Index);
рассматривает пакет как применение ресурса — процедуры New_Airplane, которой должен быть задан конкретный объект Airplane. Язык C++ полагает, что объект Airplane — это экземпляр класса Airplanes, и, если вы посылаете объекту сообщение (message) new_airplane, для этого объекта будет выполнена соответствующая процедура.
Обратите внимание, что даже такие подпрограммы, как find_empty_entry, которые используются только внутри класса, объявлены в определении класса. Язык C++ не имеет ничего похожего на тело пакета, представляющее собой единицу, которая инкапсулирует реализацию интерфейса и других подпрограмм. Конечно, внутренняя подпрограмма недоступна другим модулям, потому что она объявлена внутри закрытой части. В языке C++ проблема состоит в том, что, если необходимо изменить объявление find_empty_entry или добавить другую приватную подпрограмму, придется перекомпилировать все модули программы, которые используют этот класс; в языке Ada изменение тела пакета не воздействует на остальную часть программы. Чтобы достичь на языке C++ реального разделения интерфейса и реализации, следует объявить интерфейс как абстрактный класс, а затем получить конкретный производный класс, который содержит реализацию
(см. раздел 15.1).
Где находятся подпрограммы реализованного класса? Ответ состоит в том, что они могут быть реализованы где угодно, в частности в отдельном файле, который обращается к определению класса через включаемый файл.
идентифицирует каждую подпрограмму как принадлежащую
Операция разрешения контекста «::» идентифицирует каждую подпрограмму как принадлежащую конкретному классу:
// Некоторый файл
#include "Airplanes.h" // Содержит объявление класса
void Airplanes::new_airplane(const Airplane_Data & a, int & i)
{
…
}
void Airplanes::get_airplane(int i, Airplane_Data & a) const
{
….
}
int Airplanes::find_empty_entry()
{
…
}
Обратите внимание, что внутренняя подпрограмма find_empty_entry должна быть объявлена внутри (в закрытой части) класса так, чтобы она могла обращаться к приватным данным.
Пространство имен
Одним из последних добавлений к определению языка C++ была конструкция namespace (пространство имен), которая дает возможность программисту ограничить область действия других глобальных объектов так же, как это делается с помощью пакета в языке Ada. Конструкция, аналогичная use-предложению в Ada, открывает пространство имен:
namespace N1 {
void proc(); //Процедура в пространстве имен
};
namespace N2 {
void proc(); // Другая процедура
};
N1:: proc(), //Операция разрешения контекста для доступа
using namespace N1 ;
proc(); // Правильно
using namespace N2;
proc(); //Теперь неоднозначно
К сожалению, в языке C++ не определен библиотечный механизм: объявления класса могут использоваться совместно только через включаемые файлы. Группа разработчиков должна организовать процедуры для обновления включаемых файлов, отдавая предпочтение программным инструментальным средствам, чтобы оповещать членов группы о том, что две компиляции не используют одну и ту же версию включаемого файла.
13.6.
Напишите главную программу на языке
Упражнения
1. Напишите главную программу на языке С, которая вызывает внешнюю функцию f с целочисленным параметром; в другом файле напишите функцию f с параметром с плавающей точкой, который она печатает. Откомпилируйте, скомпонуйте и выполните программу. Что она печатает? Попытайтесь откомпилировать, скомпоновать и выполнить ту же самую программу на языке C++ .
2. Напишите программу, реализующую абстрактный тип данных для очереди, и главную программу, которая объявляет и использует несколько очередей. Очередь должна быть реализована как массив, который объявлен в закрытой части пакета языка Ada или класса C++. Затем измените реализацию на связанный список; главная программа должна выполняться без изменений.
3. Что происходит, если вы пытаетесь присвоить одну очередь другой? Решите проблему, используя ограниченный приватный тип в языке Ada или конструктор копий (copy-constructor) в C++.
4. В языках С и C++ в объявлении подпрограммы имена параметров не обязательны:
|
C |
Почему это так? Будут ли так или иначе использоваться имена параметров? Почему в языке Ada требуется, чтобы в спецификации пакета присутствовали имена параметров?
5. В языке Ada есть конструкция для раздельной компиляции, которая не зависит от конструкции пакета:
|
Ada |
Global: Integer;
procedure R is separate; -- Раздельно компилируемая процедура
end Main;
separate(Main) --Другой файл
procedure R is
begin
Global := 4; -- Обычные правила области действия
end R:
Факт раздельной компиляции локального пакета или тела процедуры не влияет на область действия и видимость. Как это может быть реализовано? Требуют ли изменения в раздельно компилируемой единице перекомпиляции родительской единицы? Почему? Обратный вопрос: как изменения в родителе воздействуют на раздельно компилируемую единицу?
Раздельно компилируемая единица может содержать
6. Раздельно компилируемая единица может содержать конструкцию, задающую контекст:
with Text_IO;
|
Ada |
procedure R is
…
end R;
Как это можно использовать?
7. Следующая программа на языке Ada не компилируется; почему?
package P is
type T is (А, В, С, D);
end Р;
|
Ada |
procedure Main is
X: Р.Т;
begin
if X = P. A then ...end if;
end Main;
Существуют четыре способа решить проблему; каковы преимущества и недостатки каждого из них: а) use-конструкция, б) префиксная запись, в) renames (переименование), г) конструкция use type в языке Ada 95?
Глава 14
Объектно-ориентированное программирование
14.1. Объектно-ориентированное проектирование
В предыдущей главе обсуждалась языковая поддержка структурирования программ, но мы не пытались ответить на вопрос: как следует разбивать программы на модули? Обычно этот предмет изучается в курсе по разработке программного обеспечения, но один метод декомпозиции программ, называемый объектно-ориентированным программированием (ООП), настолько важен, что современные языки программирования непосредственно поддерживают этот метод. Следующие две главы будут посвящены теме языковой поддержки ООП.
При проектировании программы естественный подход должен состоять в том, чтобы исследовать требования в терминах функций или операций, то есть задать вопрос: что должна делать программа? Например, программное обеспечение для предварительной продажи билетов в авиакомпании должно выполнять такие функции:
1. Принять от кассира место назначения заказчика и дату отправления.
2. Отобразить на терминале кассира список доступных рейсов.
3. Принять от кассира предварительный заказ на конкретный рейс.
4. Подтвердить предварительный заказ и напечатать билет.
Эти требования, естественно, находят отражение в проекте, показанном на рис. 14.1, с модулем для каждой функции и «главным» модулем, который вызывает другие.
К сожалению, этот проект не
К сожалению, этот проект не будет надежным в эксплуатации; даже для небольших изменений в требованиях могут понадобиться значительные изменения программного обеспечения. Для примера предположим, что авиакомпания улучшает условия труда, заменяя устаревшие дисплейные терминалы. Вполне правдоподобно, что для новых терминалов потребуется изменить все четыре модуля; точно так же придется вносить много исправлений, если изменятся соглашения о форматах информации, используемой совместно с другими компаниями.
Но все мы знаем, что изменение программного обеспечения чревато внесением ошибок; не устойчивый к ошибкам проект приведет к тому, что поставленная программная система будет ненадежной и неустойчивой. Вы могли бы возразить, что персонал должен воздержаться от изменения программного обеспечения, но весь смысл программного обеспечения состоит в том, что это именно программное обеспечение, а значит, его можно перепрограммировать, изменить; иначе все прикладные программы было бы эффективнее «зашить» подобно программе карманного калькулятора.

Программное обеспечение можно сделать намного устойчивее к ошибкам и надежнее, если изменить основные критерии, которыми мы руководствуемся при проектировании. Правильнее задать вопрос: над чем работает программное обеспечение? Акцент делается не на функциональных возможностях, а на внешних устройствах, внутренних структурах данных и моделях реального мира, т. е. на том, что принято называть объектами (objects). Модуль должен быть создан для каждого «объекта» и содержать все данные и операции, необходимые для реализации объекта. В нашем примере мы можем выделить несколько объектов, как показано на рис. 14.2.
Такие внешние устройства, как дисплейный терминал и принтер, идентифицированы как объекты, так же как и базы данных с информацией о рейсах и предварительных заказах. Кроме того, мы выделили объект Заказчик, назначение которого — моделировать воображаемую форму, в которую кассир вводит данные до того, как подтвержден рейс и выдан билет.
которые вносят для того, чтобы
Этот проект устойчив к ошибкам при внесении изменений:

• Изменения, которые вносят для того, чтобы использовать разные терминалы, могут быть ограничены объектом Терминал. Программы этого объекта отображают данные заказчика на реальный дисплей и команды клавиатуры, так что объект Заказчик не должен изменяться, а только отображаться на новые аппаратные средства.
• Перераспределение кодов авиакомпаний может, конечно, потребовать общей реорганизации базы данных, но что касается остальных частей программы, то для них один двухсимвольный код авиакомпании ничем не отличается от другого.
Объектно-ориентированное проектирование можно использовать не только для моделирования реальных объектов, но и для создания многократно используемых программных компонентов. Это непосредственно связано с одной из концепций языков программирования, которую мы подчеркивали, — абстрагированием. Модули, реализующие структуры данных, могут быть разработаны и запрограммированы как объекты, которые являются экземплярами абстрактного типа данных вместе с операциями для обработки данных. Абстрагирование достигается за счет того, что представление типа данных скрывается внутри объекта.
Фактически, основное различие между объектно-ориентированным и «обычным» программированием состоит в том, что в обычном программировании мы ограничены встроенными абстракциями, в то время как в объектно-ориентированном мы можем определять свои собственные абстракции. Например, числа с плавающей точкой (см. гл. 9) — это ничто иное, как удобная абстракция сложной обработки данных на компьютере. Хорошо было бы, если бы все языки программирования содержали встроенные абстракции для каждого объекта, который нам когда-нибудь понадобится (комплексные числа, рациональные числа, векторы, матрицы и т. д. и т. п.), но полезным абстракциям нет предела. В конечном счете, язык программирования нужно чем-то ограничить и оставить работу для программиста.
Как программист может создавать новые
Как программист может создавать новые абстракции? Один из способов состоит в том, чтобы использовать соглашения кодирования и документирование («первый элемент массива — вещественная часть, а второй — мнимая часть»). С другой стороны, язык может обеспечивать такую конструкцию, как приватные типы в языке Ada, которая дает возможность программисту явно определить новые абстракции; эти абстракции будут компилироваться и проверяться точно так же, как и встроенные абстракции. ООП можно (и полезно) применять и в рамках обычных языков, но, аналогично другим идеям в про- граммировании, оно работает лучше всего, когда используются языки, которые непосредственно поддерживают это понятие. Основная конструкция для поддержки ООП — абстрактный тип данных, который обсуждался в предыдущей главе, но важно понять, что объектно-ориентированное проектирование является более общим и простирается до абстрагирования внешних устройств, моделей реального мира и т. д.
Объектно-ориентированное проектирование — дело чрезвычайно слож-ное. Нужны большой опыт и здравый смысл, чтобы решить, что же заслуживает того, чтобы стать объектом. Новички в объектно-ориентированном проектировании склонны впадать в излишний энтузиазм и делать объектами буквально все; а это приводит к таким перегруженным и длинным утомительным программам, что теряются все преимущества метода. Наилучшее интуитивное правило, на которое стоит опираться, — это правило упрятывания информации:
В каждом объекте должно скрываться одно важное проектное решение.
Очень полезно бывает задать себе вопрос: «возможно ли, что это решение изменится за время жизни программы?»
Конкретные дисплейные терминалы и принтеры, выбранные для системы предварительных заказов, явно подлежат обновлению. Точно так же решения по организации базы данных, вероятно, будут изменяться, чтобы улучшить эффективность, поскольку система растет. С другой стороны, можно было бы привести доводы, что изменение формы данных заказчика маловероятно и что отдельный объект здесь не нужен.