Если вы хотите связать его
Если вы хотите связать его с внешним if-оператором, нужно использовать скобки:
if(x1>y1){
if (x2 > у2)
statement_1; }
else
statement_2;
Вложенные if-операторы могут определять полное двоичное дерево выборов (рис. 6.2а) или любое произвольное поддерево. Во многих случаях тем не менее необходимо выбрать одну из последовательностей выходов (рис. 6.26).

Если выбор делается на основе выражения, можно воспользоваться switch-оператором. Однако, если выбор делается на основе последовательности выражений отношения, понадобится последовательность вложенных if-onepa-торов. В этом случае принято отступов не делать:
|
C |
…
} else if (x > z) {
} else if(y < z) {
} else {
...
}
Явный end if
Синтаксис if-оператора в языке С (и Pascal) требует, чтобы каждый вариант выбора был одиночным оператором. Если вариант состоит из нескольких операторов, они должны быть объединены в отдельный составной (compound) оператор с помощью скобок ({,} в языке С и begin, end в Pascal). Проблема такого синтаксиса состоит в том, что если закрывающая скобка пропущена, то компиляция будет продолжена без извещения об ошибке в том месте, где она сделана. В лучшем случае отсутствие скобки будет отмечено в конце компиляции; а в худшем — количество скобок сбалансируется пропуском какой-либо открывающей скобки и ошибка станет скрытой ошибкой этапа выполнения.
Эту проблему можно облегчить, явно завершая if-оператор. Пропуск закрывающей скобки будет отмечен сразу же, как только другая конструкция (цикл или процедура) окажется завершенной другой скобкой. Синтаксис if-оператора языка Ada таков:
if expression then
statement_list_1;
|
Ada |
statement_list_2;
end if;
Недостаток этой конструкции в том, что в случае последовательности условий (рис. 6.26) получается запутанная последовательность из end if. Чтобы этого избежать, используется специальная конструкция elsif, которая представляет другое условие и оператор, но не другой if-оператор, так что не требуется никакого дополнительного завершения:
Обратите внимание, что вариант False
if x > у then
….
|
Ada |
….
elsif у > z then
…
else
…
end if;
Реализация
Реализация if-оператора проста:

Обратите внимание, что вариант False немного эффективнее, чем вариант True, так как последний выполняет лишнюю команду перехода. На первый взгляд может показаться, что условие вида:
|
C |
потребует дополнительную команду для отрицания значения. Однако компиляторы достаточно интеллектуальны для того, чтобы заменить изначальную команду jump_false на jump_true.
Укороченное и полное вычисления
Предположим, что в условном операторе не простое выражение отношения, а составное:
|
Ada |
Есть два способа реализации этого оператора. Первый, называемый полным вычислением, вычисляет каждый из компонентов, затем берет булево произведение компонентов и делает переход согласно полученному результату. Вторая реализация, называемая укороченным вычислением (short-circuit)*, вычисляет компоненты один за другим: как только попадется компонент со значением False, делается переход к False-варианту, так как все выражение, очевидно, имеет значение False. Аналогичная ситуация происходит, если составное выражение является or-выражением: если какой-либо компонент имеет значение True, то, очевидно, значение всего выражения будет True.
Выбор между двумя реализациями обычно может быть предоставлен компилятору. В целом укороченное вычисление требует выполнения меньшего числа команд. Однако эти команды включают много переходов, и, возможно, на компьютере с большим кэшем команд (см. раздел 1.7) эффективнее вычислить все компоненты, а переход делать только после полного вычисления.
В языке Pascal оговорено полное вычисление, потому что первоначально он предназначался для компьютера с большим кэшем. Другие языки имеют два набора операций: один для полного вычисления булевых значений и другой — для укороченного.
в Ada and используется для
Например, в Ada and используется для полностью вычисляемых булевых операций на булевых и модульных типах, в то время как and then определяет укороченное вычисление:
|
Ada |
Точно так же or else — эквивалент укороченного вычисления для or.
Язык С содержит три логических оператора: «!» (не), « &&» (и), и «||» (или). Поскольку в С нет настоящего типа Boolean, эти операторы работают с целочисленными операндами и результат определяется в соответствии с интерпретацией, описанной в разделе 4.4. Например, а && b равно единице, если оба операнда не нулевые. Как «&&», так и «||» используют укороченное вычисление. Убедитесь, что вы не спутали эти операции с поразрядными операциями (раздел 5.8).
Относительно стиля программирования можно сказать, что в языке Ada программисты должны выбрать один стиль (либо полное вычисление, либо укороченное) для всей программы, используя другой стиль только в крайнем случае; в языке С вычисления всегда укороченные.
Укороченность вычисления существенна тогда, когда сама возможность вычислить отношение в составном выражении зависит от предыдущего отношения:
|
Ada |
Такая ситуация часто встречается при использовании указателей (гл. 8):
|
Ada |
6.3. Операторы цикла
Операторы цикла наиболее трудны для программирования: в них легко сделать ошибку, особенно на границах цикла, то есть при первом и последнем выполнении тела цикла. Кроме того, неэффективная программа чаще всего расходует большую часть времени в циклах, поэтому так важно понимать их реализацию. Структура цикла показана на рис. 6.3. Оператор цикла имеет точку входа, последовательность операторов, которые составляют цикл, и одну

или несколько точек выхода. Так как мы (обычно) хотим, чтобы наши циклы завершались, с точкой выхода бывает связано соответствующее условие, которое определяет, следует сделать выход или продолжить выполнение цикла.
и расположением условий выхода. Мы
Циклы различаются числом, типом и расположением условий выхода. Мы начнем с обсуждения циклов с произвольными условиями выхода, называемыми циклами while, а в следующем разделе обсудим частный случай — циклы for.
Наиболее общий тип цикла имеет единственный выход в начале цикла, т.е. в точке входа. Он называется циклом while:
|
C |
Цикл while прост и надежен. Поскольку условие проверяется в начале цикла, мы знаем, что тело цикла будет полностью выполнено столько раз, сколько потребуется по условию. Если условие выхода сначала имеет значение False,то тело цикла не будет выполнено, и это упрощает программирование граничных условий:
|
C |
Если в массиве нет данных, выход из цикла произойдет немедленно.
Во многих случаях, однако, выход естественно писать в конце цикла. Так обычно делают, когда нужно инициализировать переменную перед каждым выполнением. В языке Pascal есть оператор повторения repeat:
|
Pascal |
read(v);
put_in_table(v);
until v = end_value;
В языке Pascal repeat заканчивается, когда условие выхода принимает значение True. He путайте его с циклом do в языке С, который заканчивается, когда условие выхода принимает значение False:
|
C |
v = get();
put_in_table(v);
} while (v != end_value);
Принципы безупречного структурного программирования требуют, чтобы все выходы из цикла находились только в начале или конце цикла. Это делает программу более легкой для анализа и проверки. Но на практике бывают нужны выходы и из середины цикла, особенно при обнаружении ошибки:
while not found do
|
Pascal |
(* Длинное вычисление *)
(* Обнаружена ошибка, выход *)
(* Длинное вычисление *)
end
Pascal, в котором не предусмотрен выход из середины цикла, использует следующее неудовлетворительное решение: установить условие выхода и использовать if-оператор, чтобы пропустить оставшуюся часть цикла:
В Ada есть обычный цикл
while not found do
|
Pascal |
(* Длинное вычисление *)
if error_detected then found := True
else
begin
(* Длинное вычисление *)
end
end
В языке С можно использовать оператор break:
while (!found) {
|
C |
if (error_detected()) break;
/* Длинное вычисление */
}
В Ada есть обычный цикл while, а также оператор exit, с помощью которого можно выйти из цикла в любом месте; как правило, пара связанных операторов if и exit заменяется удобной конструкцией when:
while not Found loop
|
Ada |
exit when error_detected;
- Длинное вычисление
end loop;
Операционная система или система, работающая в реальном масштабе времени, по замыслу, не должна завершать свою работу, поэтому необходим способ задания бесконечных циклов. В Ada это непосредственно выражается оператором loop без условия выхода:
|
Ada |
…
end loop;
В других языках нужно написать обычный цикл с искусственным условием выхода, которое гарантирует, что цикл не завершится:
while(1==1){
|
C |
}
Реализация
Цикл while:
|
C |
statement;
реализуется так:
L1: compute R1.expr
jump_zero R1,L2 Выйти из цикла, если false
statement Тело цикла
jump L1 Перейти на проверку завершения цикла L2:
Обратите внимание, что в реализации цикла while есть две команды перехода! Интересно, что если выход находится в конце цикла, то нужна только одна команда перехода:
do{
|
C |
} while (expression);
компилируется в
L1: statement
compute expr
jump_nz L1 He ноль — это True
Хотя цикл while очень удобен
Хотя цикл while очень удобен с точки зрения читаемости программы, эффективность кода может быть увеличена путем замены его на цикл do. Для выхода из середины цикла требуются два перехода точно так же, как и для цикла while.
6.4. Цикл for
Очень часто мы знаем количество итераций цикла: это либо константа, известная при написании программы, либо значение, вычисляемое перед началом цикла. Цикл со счетчиком можно запрограммировать следующим образом:
int i; /* Индекс цикла */
|
C |
i = low; /* Инициализация индекса */
while (i <= high) { /* Вычислить условие выхода */
statement;
i++: /* Увеличить индекс */
};
Поскольку это общая парадигма, постольку для упрощения программирования во всех (императивных) языках есть цикл for. Его синтаксис в языке С следующий:
int i; /* Индекс цикла */
int low, high; /* Границы цикла */
|
C |
statement;
}
В Ada синтаксис аналогичный, за исключением того, что объявление и увеличение переменной цикла неявные:
Low, High: Integer;
|
Ada |
statement;
end loop;
Ниже в этом разделе мы обсудим причины этих различий.
Известно, что в циклах for легко сделать ошибки в значениях границ. Цикл выполняется для каждого из значений от low до high; таким образом, общее число итераций равно high - low +1. Однако, если значение low строго больше значения high, цикл будет выполнен ноль раз. Если вы хотите выполнить цикл точно Л/ раз, цикл for будет иметь вид:
|
Ada |
за того, что для массивов
forlinl ..N loop...
и число итераций равно N -1 + 1 = N. В языке С из- за того, что для массивов индексы должны начинаться с нуля, цикл со счетчиком обычно записывается так:
|
C |
Так как запись i < п означает то же самое, что и i <= (п - 1), цикл выполняется (п -1)-0+1 =п раз, как и требуется.
Обобщения в циклах for
Несмотря на то, что все процедурные языки содержат циклы for, они значительно отличаются по предоставляемым дополнительным возможностям. Две крайности — это Ada и С.
В Ada исходным является положение, что цикл for должен использоваться только с фиксированным числом итераций и что это число можно вычислить перед началом цикла. Объясняется это следующим: 1) большинство реальных циклов простые, 2) другие конструкции легко запрограммировать в явном виде, и 3) циклы for и сами по себе достаточно трудны для тестирования и проверки. В языке Ada нет даже классического обобщения: увеличения переменной цикла на значения, отличные от 1 (или -1). Язык Algol позволяет написать итерации для последовательности нечетных чисел:
|
Algol |
в то время как в Ada мы должны явно запрограммировать их вычисление:
for l in 1 .. (N + 1)/2 loop
|
Ada |
…
end loop;
В языке С все три элемента цикла for могут быть произвольными выражениями:
|
C |
В описании С определено, что оператор
|
C |
эквивалентен конструкции
|
C |
while (expression_2) {
statement;
expression_3;
}
В языке Ada также допускается использование выражений для задания границ цикла, но они вычисляются только один раз при входе в цикл. То есть
|
Ada |
Если тело цикла изменяет значение
expression_2 loop
statement;
end loop;
эквивалентно
I = expression_1;
|
Ada |
while (I < Temp) loop
statement;
I: = I + 1;
end loop;
Если тело цикла изменяет значение переменных, используемых при вычислении выражения expression_2, то верхняя граница цикла в Ada изменяться не будет. Сравните это с данным выше описанием цикла for в языке С, который заново вычисляет значение выражения expression_2 на каждой итерации.
Обобщения в языке С — нечто большее, чем просто «синтаксический сахар», поскольку операторы внутри цикла, изменяющие выражения expres-sion_2 и expression_3, могут вызывать побочные эффекты. Побочных эффектов следует избегать по следующим причинам.
• Побочные эффекты затрудняют полную проверку и тестирование цикла.
• Побочные эффекты неблагоприятно воздействуют на читаемость и поддержку программы.
•Побочные эффекты делают цикл гораздо менее эффективным, потому что выражения expression_2 и expression_3 нужно заново вычислять на каждой итерации. Если побочных эффектов нет, оптимизирующий компилятор может вынести эти вычисления за границу цикла.
Реализация
Циклы for — наиболее часто встречающиеся источники неэффективности в программах, потому что небольшие различия в языках или небольшие изменения в использовании оператора могут иметь серьезные последствия. Во многих случаях оптимизатор в состоянии решить эти проблемы, но лучше их понимать и избегать, чем доверяться оптимизатору. В этом разделе мы более подробно опишем реализацию на уровне регистров.
В языке Ada цикл
|
Ada |
statement;
end loop;
компилируется в
compute R1,expr_1
store R1,l Нижняя граница индексации
compute R2,expr_2
store R2,High Верхняя граница индексации
это закрепление регистра за индексной
L1: load R1,l Загрузить индекс
load R2,High Загрузить верхнюю границу
jump_gt R1,R2,L2 Завершить цикл, если больше
statement Тело цикла
load R1,l Увеличить индекс
incr R1
store R1,l
jump L1
L2:
Очевидная оптимизация — это закрепление регистра за индексной переменной I и, если возможно, еще одного регистра за High:
compute R1 ,ехрг_1 Нижняя граница в регистре
compute R2,expr_2 Верхняя граница в регистре
L1: jump_gt R1,R2,L2 Завершить цикл, если больше
statement
incr R1 Увеличить индексный регистр
jump L1
L2:
Рассмотрим теперь простой цикл в языке С:
|
C |
statement;
Это компилируется в
compute R1,expr_1
store R1,i Нижняя граница индексации
L1: compute R2,expr_2 Верхняя граница внутри цикла!
jump_gt R1,R2,L2 Завершить цикл, если больше
statement Тело цикла
load R1,i Увеличить индекс
incr R1
store R1,i
jump L1
L2:
Обратите внимание, что выражение expression_2, которое может быть очень сложным, теперь вычисляется внутри цикла. Кроме того, выражение expres-sion_2 обязательно использует значение индексной переменной i, которая изменяется при каждой итерации. Таким образом, оптимизатор должен уметь выделить неизменяющуюся часть вычисления выражения expression_2, чтобы вынести ее из цикла.
Можно ли хранить индексную переменную
Можно ли хранить индексную переменную только в регистре для увеличения эффективности? Ответ зависит от двух свойств цикла. В Ada индексная переменная считается константой и не может изменяться программистом. В языке С индексная переменная — это обычная переменная; она может храниться в регистре только в том случае, когда абсолютно исключено изменение ее текущего значения где-либо вне цикла. Никогда не используйте глобальную переменную в качестве индексной переменной, потому что другая процедура может прочитать или изменить ее значение:
|
C |
void p2(void) {
i = i + 5;
}
void p1(void) {
for (i=0; i<100; i++) /* Глобальная индексная переменная */
p2(); /* Побочный эффект изменит индекс*/
}
Второе свойство, от которого зависит оптимизация цикла, — потенциальная возможность использования индексной переменной за пределами цикла. В Ada индексная переменная неявно объявляется for-оператором и недоступна за пределами цикла. Таким образом, независимо от того, как осуществляется выход из цикла, мы не должны сохранять значение регистра. Рассмотрим следующий цикл поиска значения key в массиве а:
|
C |
int i, key;
key = get_key();
for(i = 0;i< 100; i++)
if (a[i] == key) break;
process(i);
Переменная i должна содержать правильное значение независимо от способа, которым был сделан выход из цикла. Это может вызывать затруднения при попытке оптимизировать код. Обратите внимание, что в Ada требуется явное кодирование для достижения того же самого результата, потому что индексная переменная не существует вне области цикла:
|
Ada |
for I in 1 ..100 loop
if A(l) = Key then
Found = I;
exit;
end if;
end loop;
Определение области действия индексов цикла в языке C++ с годами менялось, но конечное определение такое же, как в Ada: индекс не существует вне области цикла:
Индексная переменная является локальной для
for(int i=0;i<100;i++){
|
C++ |
}
На самом деле в любом управляемом условием операторе (включая, if- и switch-операторы) можно задать в условии несколько объявлений; область их действия будет ограничена управляющим оператором. Это свойство может способствовать читаемости и надежности программы, предотвращая непреднамеренное использование временного имени.
6.5. «Часовые»
Следующий раздел не касается языков программирования как таковых; скорее, он предназначен для того, чтобы показать, что программу можно улучшить за счет более совершенных алгоритмов и методов программирования, не прибегая к «игре» на языковых частностях. Этот раздел включен в книгу, потому что тема выхода из цикла при последовательном переборе является предметом интенсивных дебатов, однако существует и другой алгоритм, который является одновременно ясным, надежным и эффективным.
В последнем примере предыдущего раздела (поиск в массиве) есть три команды перехода в каждой итерации цикла: условный переход цикла for, условный переход if-оператора и переход от конца цикла обратно к началу. Проблема поиска в данном случае состоит в том, что мы проверяем сразу два условия: найдено ли значение key и достигнут ли конец массива? Используя «часового» (sentinel) *, мы можем два условия заменить одним. Идея состоит в том, чтобы ввести в начале массива дополнительно еще один элемент («часового») и хранить в нем эталонное значение key, которое нужно найти в массиве (рис. 6.4).

Поскольку мы обязательно найдем key либо как элемент массива, либо как искусственно введенный элемент, постольку достаточно проверять только одно условие внутри цикла:
|
Ada |
-- Дополнительное место в нулевой позиции для «часового»
Если при возврате управления из
function Find_Key(A: A_Type; Key: Integer)
return Integer is
I: Integer := 100; -- Поиск с конца
begin
A(0) := Key; -- Установить «часового»
while A(l) /= Key loop
I:=I-1;
end loop;
return I;
end Find_Key;
Если при возврате управления из функции значение I равно нулю, то Key в
массиве нет; в противном случае I содержит индекс найденного значения.
Этот код более эффективен, цикл чрезвычайно прост и может быть легко про-
верен.
6.6. Инварианты
Формальное определение семантики операторов цикла базируется на концепции инварианта: формулы, которая остается истинной после каждого выполнения тела цикла. Рассмотрим предельно упрощенную программу для вы- числения целочисленного деления а на b с тем, чтобы получить результат у:
у = 0;
|
C |
while (х >- b) { /* Пока b «входит» в х, */
х -= b; /* вычитание b означает, что */
у++; /* результат должен быть увеличен */
}
и рассмотрим формулу:
a = yb +х
где курсивом обозначено значение соответствующей программной переменной. После операторов инициализации она, конечно, будет правильной, поскольку у = 0 и х = а. Кроме того, в конце программы формула определяет, что у есть результат целочисленного деления а/b при условии, что остаток х меньше делителя b.
Не столь очевидно то, что формула остается правильной после каждого выполнения тела цикла. В такой тривиальной программе этот факт легко увидеть с помощью простой арифметики, изменив значения х и у в теле цикла:
(у + \)b + (х-b)=уb+b+х-b=уb+х=а
Таким образом, выполнение тела цикла переводит программу из состояния, которое удовлетворяет инварианту, в другое состояние, которое по-прежнему удовлетворяет инварианту.
Теперь заметим: для того чтобы
Теперь заметим: для того чтобы завершить цикл, булево условие в цикле while должно иметь значение False, то есть вычисление должно быть в таком состоянии, при котором --(х > b), что эквивалентно х < b. Объединив эту формулу с инвариантом, мы показали, что программа действительно выполняет целочисленное деление.
Точнее, если программа завершается, то результат является правильным. Это называется частичной правильностью. Чтобы доказать полную правильность, мы должны также показать, что цикл завершается.
Это делается следующим образом. Так как во время выполнения программы b является константой (и предполагается положительной!), нам нужно показать, что неоднократное уменьшение х на b должно, в конечном счете, привести к состоянию, в котором 0 < х < b. Но 1) поскольку х уменьшается неоднократно, его значение не может бесконечно оставаться больше значения b; 2) из условия завершения цикла и из вычисления в теле цикла следует, что х никогда не станет отрицательным. Эти два факта доказывают, что цикл должен завершиться.
Инварианты цикла в языке Eiffel
Язык Eiffel имеет в себе средства для задания контрольных утверждений вообще (см. раздел 11.5) и инвариантов циклов в частности:
from
у = 0; х = а;
invariant
|
Eiffel |
variant
х
until
x< b
loop
x :=x-b;
у:=у+1;
end
Конструкция from устанавливает начальные условия, конструкция until задает условие для завершения цикла, а операторы между loop и end образуют тело цикла. Конструкция invariant определяет инвариант цикла, а конструкция variant определяет выражение, которое будет уменьшаться (но останется неотрицательным) с каждой итерацией цикла. Правильность инварианта проверяется после каждого выполнения тела цикла.
6.7.
В первоначальном описании языка Fortran
Операторы goto
В первоначальном описании языка Fortran был только один структурированный управляющий оператор: оператор do, аналогичный циклу for. Все остальные передачи управления делались с помощью условных или безусловных переходов на метки, т. е. с помощью операторов, которые называются goto:
if(a.eq.b)goto12
…
goto 5
|
Fortan |
…
12 …
…
5 …
if (x .gt. y) goto 4
В 1968 г. Э. Дейкстра написал знаменитое письмо, озаглавленное «оператор goto следует считать вредным», с которого началась дискуссия о структурном программировании. Основной аргумент против goto состоит в том, чтс произвольные переходы не структуированы и создают «программу-спагетти», в которой возможные пути выполнения так переплетаются, что ее невозможно понять и протестировать. Аргументом в пользу goto является то что в реальных программах часто требуются более общие управляющие структуры, чем те, которые предлагают структурированные операторы, и чтс принуждение программистов использовать их приводит к искусственному и сложному коду.
Оглядываясь назад, можно сказать, что эти дебаты были чересчур эмоциональны и затянуты, потому что основные принципы совсем просты и не требуют долгого обсуждения. Более того, в современные диалекты языка Fortrar добавлены более совершенные операторы управления с тем, чтобы оператор goto больше не доминировал.
Можно доказать математически, что достаточно if- и while-операторов чтобы записать любую необходимую управляющую структуру. Кроме того эти операторы легко понять и использовать. Различные синтаксические расширения типа циклов for вполне ясны и при правильном использовании не представляют никаких трудностей для понимания или сопровождения программы.
Так почему же языки программирования
Так почему же языки программирования (включая Ada, при разработке которого исходили из соображений надежности) сохраняют goto?
Причина в том, что есть несколько вполне определенных ситуаций, где лучше использовать goto. Во-первых, многие циклы не могут завершаться в точке входа, как того требует цикл while. Попытка превратить все циклы в циклы while может затемнить суть дела. В современных языках гибкости привносимой операторами exit и break, достаточно и оператор goto для этой цели обычно не нужен. Однако goto все еще существует и иногда может быть полезным. Обратите внимание, что как язык С, так и Ada, ограничивают применение goto требованием, чтобы метка находилась в той же самой процедуре.
Вторая ситуация, которую легко запрограммировать с помощью goto, — выход из глубоко вложенного вычисления. Предположим, что глубоко внутри ряда вызовов процедур обнаружена ошибка, что делает неверным все вычисление. В этой ситуации естественно было бы запрограммировать выдачу сообщения об ошибке и завершить или возвратить в исходное состояние все вычисление. Однако для этого требуется сделать возврат из многих процедур, которые должны знать, что произошла ошибка. Проще и понятнее выйти в основную программу с помощью goto.
В языке С нет никаких средств для обработки этой ситуации (не подходит даже goto по причине ограниченности рамками отдельной процедуры), поэтому для обработки серьезных ошибок нужно использовать средства операционной системы. В языках Ada, C++ и Eiffel есть специальные языковые конструкции, так называемые исключения (exseptions), см. гл. 11, которые непосредственно решают эту проблему. Таким образом, операторы goto в большинстве случаев были вытеснены по мере совершенствования языков.
Назначаемые goto-операторы
В языке Fortran есть конструкция, которая называется назначаемым (assigned) оператором goto. Можно определить метку-переменную и присваивать ей значение той или иной конкретной метки.
переменной фактической целевой точкой перехода
При переходе по метке- переменной фактической целевой точкой перехода является значение этой переменной:
assign 5 to Label
...
|
Fortan |
5 ...
6 ...
goto Label
Проблема, конечно, в том, что присваивание значения метке-переменной могло быть сделано за миллионы команд до того, как выполняется goto, и программы в таких случаях отлаживать и верифицировать практически невозможно.
Хотя в других языках не существует назначаемого goto, такую конструкцию совсем просто смоделировать, определяя много небольших подпрограмм и манипулируя передачами указателей на эти подпрограммы. Соотносить конкретный вызов с присвоением указателю значения, связывающего его с той или иной подпрограммой, достаточно трудно. Поэтому указатели на подпрограммы следует применять лишь в случаях хорошей структурированности, например в таблицах указателей на функции в интерпретаторах или в механизмах обратного вызова.
6.8. Упражнения
1. Реализует ваш компилятор все case-/switch-операторы одинаково, или он пытается выбирать оптимальную реализацию для каждого оператора?
2. Смоделируйте оператор repeat языка Pascal в Ada и С.
3. Первоначально в языке Fortran было определено, что цикл выполняется, по крайней мере, один раз, даже если значение low больше, чем значение high! Чем могло быть мотивировано такое решение?
4. Последовательный поиск в языке С:
|
C |
i++;
можно записать как
|
C |
; /* Пустой оператор */
В чем различие между двумя вариантами вычислений?
5. Предположим, что в языке Ada переменная индекса может существовать за рамками цикла. Покажите, как бы это воздействовало на оптимизацию цикла.
Сравните сгенерированный для поиска код,
6. Сравните сгенерированный для поиска код, реализованный с помощью операторов break или exit, с кодом, сгенерированным для поиска с «часовым».
7. Напишите программу поиска с «часовым», используя do-while вместо while. Будет ли это эффективнее?
8. Почему мы помещали «часового» в начало массива, а не в конец?
9. (Шолтен) В игре Го используют камни двух цветов, черные и белые. Предположим, что у вас в коробке неизвестная смесь камней, и вы выполняете следующий алгоритм:
while Stones_Left_in_Can loop -- пока есть камни в коробке
|
Ada |
if Color(S1 )=Color(S2) then
Add_Black_Stone; --добавить черный камень
else
Add_White_Stone; -- добавить белый камень
end if;
end loop;
Найдите переменную, значение которой уменьшается, оставаясь неотрицательным, и тем самым покажите, что цикл заканчивается. Можете ли вы что-нибудь сказать относительно цвета последнего камня? (Подсказка: напишите инвариант цикла для числа белых камней).
Глава 7
Подпрограммы
7.1. Подпрограммы: процедуры и функции
Подпрограмма — это сегмент программы, к которому можно обратиться из любого места внутри программы. Подпрограммы используются по разным причинам:
• Сегмент программы, который должен выполняться на разных стадиях вычисления, может быть написан один раз в виде подпрограммы, а затем многократно выполняться. Это экономит память и позволяет избежать ошибок, возможных при копировании кода с одного места на другое.
это логическая единица декомпозиции программы.
• Подпрограмма — это логическая единица декомпозиции программы. Даже если сегмент выполняется только один раз, полезно оформить его в виде подпрограммы с целью тестирования, документирования и улучшения читаемости программы.
• Подпрограмму также можно использовать как физическую единицу декомпозиции программы, т. е. как единицу компиляции. В языке Fortran подпрограмма (subroutine) — это единственная единица и декомпозиции, и компиляции. В современных языках физической единицей декомпозиции является модуль, представляющий собой группу объявлений и подпрограмм (см. гл. 13).
Подпрограмма состоит из:
• объявления, которое задает интерфейс с подпрограммой; это объявление включает имя подпрограммы, список параметров (если есть) и тип возвращаемого значения (если есть);
• локальных объявлений, которые действуют только внутри тела подпрограммы;
• последовательности выполняемых операторов.
Локальные объявления и выполняемые операторы образуют тело подпрограммы.
Подпрограммы, которые возвращают значение, называются функциями (functions), а те, что не возвращают, — процедурами (procedures). Язык С не имеет отдельного синтаксиса для процедур; вместо этого следует написать функцию, которая возвращает тип void, т.е. тип без значения:
|
C |
Такая функция имеет те же свойства, что и процедура в других языках, поэтому мы используем термин «процедура» и при обсуждении языка С.
Обращение к процедуре задается оператором вызова процедуры call. В языке Fortran он имеет специальный синтаксис:
|
C |
тогда как в других языках просто пишется имя процедуры с фактическими параметрами:
|
C |
Семантика вызова процедуры следующая: приостанавливается текущая последовательность команд; выполняется последовательность команд внутри тела процедуры; после завершения тела процедуры выполнение продолжается с первой команды, следующей за вызовом процедуры.
и их области действия, что
Это описание игнорирует передачу параметров и их области действия, что будет объектом детального рассмотрения в следующих разделах.
Так как функция возвращает значение, объявление функции должно определять тип возвращаемого значения. В языке С тип функции задается в объявлении функции перед ее именем:
|
C |
тогда как в языке Ada используется другой синтаксис:
|
Ada |
Вызов функции является не оператором, а элементом выражения:
|
C |
Тип результата функции не должен противоречить типу, ожидаемому в выражении. Обратите внимание, что в языке С во многих случаях делаются неявные преобразования типов, тогда как в Ada тип результата должен точно соответствовать контексту. По смыслу вызов функции аналогичен вызову процедуры: приостанавливается вычисление выражения; выполняются команды тела функции; затем возвращенное значение используется для продолжения вычисления выражения.
Термин «функция» фактически совершенно не соответствует тому контексту, в котором он употребляется в обычных языках программирования. В математике функция — всего лишь отображение одного набора значений на другой. Если использовать техническую терминологию, то математическая функция не имеет побочного эффекта, потому что ее «вычисление» прозрачно в точке, в которой делается «вызов». Если есть значение 3.6, и вы запрашиваете значение sin(3.6), то вы будете получать один и тот же результат всякий раз, когда в уравнении встретится эта функция. В программировании функция может выполнять произвольное вычисление, включая ввод-вывод или изменение глобальных структур данных:
int x,y,z;
|
C |
{
у = get(); /* Изменяет глобальную переменную */
return x*y; /* Значение зависит от глобальной переменной */
Если оптимизатор изменил порядок вычисления
z = х + func(void) + у;
Если оптимизатор изменил порядок вычисления так, что х + у вычисляется перед вызовом функции, то получится другой результат, потому что функция изменяет значение у.
Поскольку все подпрограммы в С — функции, в программировании на языке С широко используются возвращаемые значения и в «невычислительных» случаях, например в подпрограммах ввода-вывода. Это допустимо при условии, что понятны возможные трудности, связанные с зависимостью от порядка и оптимизацией. Исследование языков программирования привело к разработке интереснейших языков, которые основаны на математически правильном понятии функции (см. гл. 16).
7.2. Параметры
В предыдущем разделе мы определили подпрограммы как сегменты кода, которые можно неоднократно вызывать. Практически всегда при вызове требуется выполнять код тела подпрограммы для новых данных. Способ повлиять на выполнение тела подпрограммы состоит в том, чтобы «передать» ей необходимые данные. Данные передаются подпрограмме в виде последовательности значений, называемых параметрами. Это понятие взято из математики, где для функции задается последовательность аргументов: sin (2piК). Есть два понятия, которые следует четко различать:
• Формальный параметр — это объявление, которое находится в объявлении подпрограммы. Вычисление в теле подпрограммы пишется в.терми-нах формальных параметров.
• Фактический параметр — это значение, которое вызывающая программа передает подпрограмме.
В следующем примере:
int i,,j;
char а;
void p(int a, char b)
|
C |
i = a + (int) b;
}
P(i,a);
P(i+j, 'x');
формальными параметрами подпрограммы р являются а и b, в то время как фактические параметры при первом вызове — это i и а, а при втором вызове — i + j и 'х'.
На этом примере можно отметить несколько важных моментов. Во-первых, так как фактические параметры являются значениями, то они могут быть константами или выражениями, а не только переменными.
менная используется как параметр, на
Даже когда пере менная используется как параметр, на самом деле подразумевается «текущее значение, хранящееся в переменной». Во-вторых, пространство имен у разных подпрограмм разное. Тот факт, что первый формальный параметр называется а, не имеет отношения к остальной части программы, и этот параметр может быть переименован, при условии, конечно, что будут переименованы все вхождения формального параметра в теле подпрограммы. Переменная а, объявленная вне подпрограммы, полностью независима от переменной с таким же именем, объявленной внутри подпрограммы. В разделе 7.7 мы более подробно рассмотрим связь между переменными, объявленными в разных подпрограммах.
Установление соответствия параметров
Обычно фактические параметры при вызове подпрограммы только перечисляются, а соответствие их формальным параметрам определяется по позиции параметра:
|
Ada |
Proc(24, 'X');
Однако в языке Ada при вызове возможно использовать установление соответствия по имени, когда каждому фактическому параметру предшествует имя формального параметра. Следовать порядку объявления параметров при этом не обязательно:
|
Ada |
Обычно этот вариант используется вместе с параметрами по умолчанию, причем параметры, которые не написаны явно, получают значения по умолчанию, заданные в объявлении подпрограммы:
|
Ada |
Proc(Second => 'X');
Соответствие по имени и параметры по умолчанию обычно используются в командных языках операционных систем, где каждая команда может иметь множество параметров и обычно необходимо явно изменить только некоторые из них. Однако этот стиль программирования таит в себе ряд опасностей. Использование параметров по умолчанию может сделать программу трудной для чтения, потому что синтаксически отличающиеся обращения фактически вызывают одну и ту же подпрограмму.
ся проблематичным, потому что при
Соответствие по имени являет ся проблематичным, потому что при этом зависимость объявления подпрограммы и вызовов оказывается более сильной, чем это обычно требуется. Если при вызовах библиотечных подпрограмм вы пользуетесь только позиционными параметрами, то вы могли бы купить библиотеку у конкурирующей фирмы и просто перекомпилировать или перекомпоновать программу:
|
Ada |
Однако если вы используете именованные параметры, то, возможно, вам придется сильно изменить свою программу, чтобы установить соответствие новым именам параметров:
|
Ada |
7.3. Передача параметров подпрограмме
Описание механизма передачи параметров — один из наиболее тонких и важных аспектов спецификации языка программирования. Неверная передача параметров — главный источник серьезных ошибок, поэтому мы подробно рассмотрим этот вопрос.
Давайте начнем с данного выше определения: значение фактического параметра передается формальному параметру. Формальный параметр — это просто переменная, которая объявлена внутри подпрограммы, поэтому, очевидно, нужно копировать значение фактического параметра в то место памяти, которое выделено для формального параметра. Этот механизм называется

«семантикой copy-in» («копирование в») или «вызовом по значению» (call-by-value). На рисунке 7.1 показана семантика copy-in для процедуры:
procedure Proc(F: in Integer) is
begin
|
Ada |
end Proc;
и вызова:
|
Ada |
Преимущества семантики copy-in:
• Copy-in является самым надежным механизмом передачи параметров. Поскольку передается только копия фактического параметра, подпрограмма никак не может испортить фактический параметр, который, несомненно, «принадлежит» вызывающей программе. Если подпрограмма изменяет формальный параметр, изменяется только копия, а не оригинал.
Фактические параметры могут быть константами,
• Фактические параметры могут быть константами, переменными или выражениями.
• Механизм copy-in может быть очень эффективным, потому что начальные затраты на копирование делаются один раз, а все остальные обращения к формальному параметру на самом деле являются обращениями к локальной копии. Как мы увидим в разделе 7.7, обращение к локальным переменным чрезвычайно эффективно.
Если семантика copy-in настолько хороша, то почему существуют другие механизмы? дело в том, что часто мы хотим изменить фактический параметр, несмотря на тот факт, что такое изменение «небезопасно»:
• Функция возвращает только один результат, но, если результат вычисления достаточно сложен, может возникнуть желание вернуть несколько значений. Чтобы сделать это, необходимо задать в процедуре несколько фактических параметров, которым могут быть присвоены результаты вычисления. Обратите внимание, что этого часто можно избежать, определив функцию, которая возвращает в качестве результата запись.
• Кроме того, цель выполнения подпрограммы может состоять в модификации данных, которые ей передаются, а не в их вычислении. Обычно это происходит, когда подпрограмма обрабатывает структуру данных. Например, подпрограмма, сортирующая массив, не вычисляет значение; ее цель состоит только в том, чтобы изменить фактический параметр. Нет никакого смысла сортировать копию массива!
• Параметр может быть настолько большим, что копировать его неэффективно. Если copy-in используется для массива из 50000 целых чисел, может просто не хватить памяти, чтобы сделать копию, или затраты на копирование будут чересчур большими.
Первые две ситуации легко разрешить с помощью семантики copy-out («копирование из»). Фактический параметр должен быть переменной, а подпрограмме передается адрес фактического параметра, который она сохраняет. Для формального параметра используется временная локальная переменная, и значение должно быть присвоено формальному параметру, по крайней мере, один раз во время выполнения подпрограммы.
зывает сохраненный адрес. На рисунке
Когда выполнение подпрограммы завершено, значение копируется в переменную, на которою ука зывает сохраненный адрес. На рисунке 7.2 показана семантика copy-out для следующей подпрограммы:
procedure Proc(F: out Integer) is
begin
|
Ada |
end Proc;
A: Integer;
Proc(A); -- Вызов процедуры с переменной
Когда нужно модифицировать фактический параметр, как, например, в sort, можно использовать семантику copy-in/out фактический параметр копирует-

ся в подпрограмму, когда она вызывается, а результирующее значение копируется обратно после ее завершения.
Однако механизмы передачи параметров на основе копирования не могут решить проблему эффективности, связанную с «большими» параметрами. Решение, которое известно как «вызов по ссылке» (call-by-reference) или «семантика ссылки» (reference cemantics), состоит в том, чтобы передать адрес фактического параметра и обращаться к параметру косвенно (см. рис. 7.3). Вызов подпрограммы эффективен, потому что для каждого параметра передается только указатель небольшого, фиксированного размера; однако обращение к параметру может оказаться неэффективным из-за косвенности.
Чтобы получить доступ к фактическому параметру, нужно загрузить его адрес, а затем выполнить дополнительную команду для загрузки значения. Обратите внимание, что при использовании семантики ссылки (или copy-out), фактический параметр должен быть переменной, а не выражением, так как ему будет присвоено значение.
Другая проблема, связанная с вызовом по ссылке, состоит в том, что может возникнуть совмещение имен (aliasing), т. е. может возникнуть ситуация, в которой одна и та же переменная известна под несколькими именами.

В следующем примере внутри функции f переменная global получает алиас (т. е. альтернативное имя) *parm:
|
C |
inta[10];
В этом примере, если выражение
int f(int *parm)
{
*parm = 5: /* Та же переменная, что и "global" */
return 6;
}
х = a[global] + f(&global);
В этом примере, если выражение вычисляется в том порядке, в котором оно записано, его значение равно а[4] + 6, но из-за совмещения имен значение выражения может быть 6 + а[5], если компилятор при вычислении выражения выберет порядок, при котором вызов функции предшествует индексации массива. Совмещение имен часто приводит к непереносимости программ.
Реальный недостаток «вызова по ссылке» состоит в том, что этот механизм по сути своей ненадежен. Предположим, что по некоторым причинам подпрограмма считает, что фактический параметр — массив, тогда как реально это всего лишь одно целое число. Это может привести к тому, что будет затерта некоторая произвольная область памяти, так как подпрограмма работает с фактическим параметром, а не просто с локальной копией. Этот тип ошибки встречается очень часто, потому что подпрограмма обычно пишется не тем программистом, который разрабатывает вызывающую программу, и всегда возможно некоторое недопонимание.
Безопасность передачи параметров можно повысить с помощью строгого контроля соответствия типов, который гарантирует, что типы формальных и фактических параметров совместимы. Однако все еще остается возможность недопонимания между тем программистом, кто написал подпрограмму, и тем, чьи данные модифицируются. Таким образом, мы имеем превосходный механизм передачи параметров, который не всегда достаточно эффективен (семантика copy-in), а также необходимые, но ненадежные механизмы (семантика copy-out и семантика ссылки). Выбор усложняется ограничениями, которые накладывают на программиста различные языки программирования. Теперь мы подробно опишем механизмы передачи параметров для нескольких языков.
Параметры в языках С и C++
В языке С есть только один механизм передачи параметров — copy-in:
Чтобы получить функциональные возможности семантики
int i = 4; /* Глобальная переменная */
|
C |
{
i=i+(int) f; /* Локальная переменная "i" */
}
proc(j, 45.0); /* Вызов функции */
В ргос изменяемая переменная i является локальной копией, а не глобальной переменной i.
Чтобы получить функциональные возможности семантики ссылки или copy-out, пишущий на С программист должен прибегать к явному использованию указателей:
int i = 4; /* Глобальная переменная */ [с]
void proc(int *i, float f)
{
*i = *i+ (int) f; /* Косвенный доступ */
}
proc(&i, 45.0); /* Понадобилась операция получения адреса */
После выполнения ргос значение глобальной переменной i изменится. Необходимость пользоваться указателями для реализации ссылочной семантики следует отнести к неудачным решениям в языке С, потому что начинающим программистам приходится изучать это относительно сложное понятие в начале курса.
В языке C++ этот недостаток устранен, поскольку в нем есть возможность задавать параметры специального ссылочного типа (reference parameters):
int i = 4; // Глобальная переменная
|
C++ |
{
i = i + (int) f; // Доступ по ссылке
}
proc(i, 45.0); // He нужна операция получения адреса
Обратите внимание на естественность стиля программирования, при котором нет неестественного использования указателей. Это усовершенствование механизма передачи параметров настолько важно, что оправдывает использование C++ в качестве замены С.
Вам часто придется применять указатели в С или ссылки в C++ для передачи больших структур данных. Конечно, в отличие от копирования параметров (copy-in), существует опасность случайного изменения фактического параметра.
Можно задать для параметра доступ
Можно задать для параметра доступ только для чтения, объявив его константой:
void proc(const Car_Data & d)
{
d.fuel = 25; // Ошибка, нельзя изменять константу
}
Объявления const следует использовать возможно шире, как для того, чтобы сделать смысл параметров более прозрачным для читателей программы, так и для того, чтобы отлавливать возможные ошибки.
Другая проблема, связанная с параметрами в языке С, состоит в том, что массивы не могут быть параметрами. Если нужно передать массив, передается адрес первого элемента массива, а процедура отвечает за правильный доступ к массиву. Для удобства имя массива в качестве параметра автоматически рассматривается как указатель на первый элемент:
intb[50]; /* Переменная типа массив */
|
C |
{
а[100] = а[200]; /* Сколько элементов? */
}
proc(&b[0]); /* Адрес первого элемента */
proc(b); /* Адрес первого элемента */
Программисты, пишущие на С, быстро к этому привыкают, но, все равно, это является источником недоразумений и ошибок. Проблема состоит в том, что, поскольку параметр — это, фактически, указатель на отдельный элемент, то допустим любой указатель на переменную того же типа:
int i;
void proc(int a[ ]); /* "Параметр-массив" */
proc(&i); /* Допустим любой указатель на целое число!! */
Наконец, в языке С контроль соответствия типов никак не действует между файлами, поэтому можно в одном файле поместить
|
C |
а в другом файле —
|
C |
требует выполнения контроля соответствия типов
а затем месяцами искать ошибку.
Язык C++ требует выполнения контроля соответствия типов для параметров. Однако он не требует, чтобы реализации включали библиотечные средства, как в Ada (см. раздел 13.3), которые могут гарантировать контроль соответствия типов для независимо компилируемых файлов. Компиляторы C++ выполняют контроль соответствия типов вместе с компоновщиком: типы параметров шифруются во внешнем имени подпрограммы (процесс называется name mangling), а компоновщик следит за тем, чтобы связывание вызовов с программами делалось только в случае корректной сигнатуры параметров. К сожалению, этот метод не может охватывать все возможные случаи несоответствия типов.
Параметры в языке Pascal
В языке Pascal параметры передаются по значению, если явно не задана передача по ссылке:
|
Pascal |
Ключевое слово var указывает, что параметр вызывается по ссылке, в противном случае используется вызов по значению, даже если параметр очень большой. Параметры могут быть любого типа, включая массивы, записи или другие сложные структуры данных. Единственное ограничение состоит в том, что тип результата функции должен быть скалярным. Типы фактических параметров проверяются на соответствие типам формальных параметров.
Как мы обсуждали в разделе 5.3, в языке Pascal есть серьезная проблема, связанная с тем, что границы массива рассматриваются как часть типа. Для решенения этой проблемы стандарт Pascal определяет совместимые параметры массива (conformant array parameters).
Параметры в языке Ada
В языке Ada принят новый подход к передаче параметров. Она определяется в терминах предполагаемого использования, а не в терминах механизма реализации. Для каждого параметра нужно явно выбрать один из трех возможных режимов.
Параметр можно читать, но не
in — Параметр можно читать, но не писать
(значение по умолчанию).
out — Параметр можно писать, но не читать.
in out — Параметр можно как читать, так и писать.
Например:
|
Ada |
procedure Get_Key(Key: out Key_Type);
procedure Sort_Keys(Keys: in out Key_Array);
В первой процедуре параметр Key должен читаться с тем, чтобы его можно было «отправить» (Put) в структуру данных (или на устройство вывода). Во второй значение получено (Get) из структуры данных, а после завершения процедуры значение присваивается параметру. Массив Keys, который нужно отсортировать, должен быть передан как in out, потому что сортировка включает и чтение, и запись данных массива.
Для функций в языке Ada разрешена передача параметров только в режиме in. Это не делает функции Ada функциями без побочных эффектов, потому что нет никаких ограничений на доступ к глобальным переменным; но это может помочь оптимизатору увеличить эффективность вычисления выражения.
Несмотря на то что режимы определены не в терминах механизмов реализации, язык Ада определяет некоторые требования по реализации. Параметры элементарного типа (числа, перечисления и указатели) должны передаваться соответствующим копированием: copy-in для in-параметров, copy-out для out-параметров и copy-in/out для in-out-параметров. Реализация режимов для составных параметров (массивов и записей) не определена, и компилятор может выбрать любой механизм. Это приводит к тому, что правильность программы в Ada может зависеть от выбранного механизма реализации, поэтому такие программы непереносимы.
Между формальными и фактическими параметрами делается строгий контроль соответствия типов. Тип фактического параметра должен быть таким же, как и у формального; неявное преобразование типов никогда не выполняется. Однако, как мы обсуждали в разделе 5.3, подтипы не обязаны быть идентичными, пока они совместимы; это позволяет передавать произвольный массив формальному неограниченному параметру.
Мы вкратце коснемся передачи параметров
Параметры в языке Fortran
Мы вкратце коснемся передачи параметров в языке Fortran, потому что здесь возможны эффектные ошибки. Fortran может передавать только скалярные значения; интерпретация формального параметра, как массива, выполняется вызванной подпрограммой. Для всех параметров используется передача параметра по ссылке. Более того, каждая подпрограмма компилируется независимо, и не делается никакой проверки на совместимость между объявлением подпрограммы и ее вызовом.
В языке определено, что если делается присваивание формальному параметру, то фактический параметр должен быть переменной, но из-за независимой компиляции это правило не может быть проверено компилятором. Рассмотрим следующий пример:
Subroutine Sub(X, Y)
|
Fortran |
X=Y
End
Call Sub(-1.0,4.6)
У подпрограммы два параметра типа Real. Поскольку используется семантика ссылки, Sub получает указатели на два фактических параметра, и присваивание выполняется непосредственно для фактических параметров (см. рис. 7.4). В результате область памяти, где хранится значение -1,0, изменяется! Без преувеличения можно сказать, что выявить и устранить эту ошибку буквально

нет никаких средств, так как отладчики позволяют проверять и отслеживать только переменные, но не константы. Как показывает практика, правильное соответствие фактических и формальных параметров — краеугольный камень надежного программирования.
7.4. Блочная структура
Блок — это объект, состоящий из объявлений и выполняемых операторов. Аналогичное определение было дано для тела подпрограммы, и точнее будет сказать, что тело подпрограммы — это блок. Блоки вообще и процедуры в частности могут быть вложены один в другой. В этом разделе будут обсуждаться взаимосвязи вложенных блоков.
Блочная структура была сначала определена в языке Algol, который включает как процедуры, так и неименованные блоки.
В языке Pascal есть вложенные
В языке Pascal есть вложенные процедуры, но нет неименованных блоков; в С есть неименованные блоки, но нет вложенных процедур; a Ada поддерживает и то, и другое.
Неименованные блоки полезны для ограничения области действия переменных, так как позволяют объявлять их, когда необходимо, а не только в начале подпрограммы. В свете современной тенденции уменьшения размера подпрограмм полезность неименованных блоков падает.
Вложенные процедуры можно использовать для группировки операторов, которые выполняются в нескольких местах внутри подпрограммы, но обращаются к локальным переменным и поэтому не могут быть внешними по отношению к подпрограмме. До того как были введены модули и объектно-ориентированное программирование, для структурирования больших программ использовались вложенные процедуры, но это запутывает программу и поэтому не рекомендуется.
Ниже приведен пример полной Ada-программы:
procedure Mam is
Global: Integer;
procedure Proc(Parm: in Integer) is
|
Ada |
begin
Global := Local + Parm;
end Proc;
begin -- Main
Global := 5;
Proc(7);
Proc(8);
end Main;
Ada-программа — это библиотечная процедура, то есть процедура, которая не включена внутрь никакого другого объекта и, следовательно, может храниться в Ada-библиотеке. Процедура начинается с объявления процедуры Main, которое служит описанием интерфейса процедуры, в данном случае внешним именем программы. Внутри библиотечной процедуры есть два объявления: переменной Global и процедуры Ргос. После объявлений располагается последовательность исполняемых операторов главной процедуры. Другими словами, процедура Main состоит из объявления процедуры и блока. Точно так же локальная процедура Ргос состоит из объявления процедуры (имени процедуры и параметров) и блока, содержащего объявления переменных и исполняемые операторы.
процедура локальная для Main или
Говорят, что Ргос — процедура локальная для Main или вложенная внутри Main.
С каждым объявлением связаны три свойства.
Область действия. Область действия переменной — это сегмент программы, в котором она определена.
Видимость. Переменная видима внутри некоторого подсегмента области действия, если к ней можно непосредственно обращаться по имени.
Время жизни. Время жизни переменной — это период выполнения программы, в течение которого переменной выделена память.
Обратите внимание, что время жизни — динамическая характеристика поведения программы при выполнении, в то время как область действия и видимость касаются исключительно статического текста программы.
Продемонстрируем эти абстрактные определения на приведенном выше примере. Область действия переменной начинается в точке объявления и заканчивается в конце блока, в котором она определена. Область действия переменной Global включает всю программу, тогда как область действия переменной Local ограничена отдельной процедурой. Формальный параметр Раrm рассматривается как локальная переменная, и его область действия также ограничена процедурой.
Видимость каждой переменной в этом примере идентична ее области действия; к каждой переменной можно непосредственно обращаться во всей ее области действия. Поскольку область действия и видимость переменной Local ограничены локальной процедурой, следующая запись недопустима:
|
Ada |
Global := Local + 5; -- Local здесь вне области действия
end Main;
Однако область действия переменной Global включает локальную процедуру, поэтому обращение внутри процедуры корректно:
procedure Proc(Parm: in Integer) is
Local: Integer;
begin
Global := Local + Parm; --Global здесь в области действия
end Proc;
Время жизни переменной — от начала выполнения ее блока до конца выполнения этого блока.
ная Global существует на протяжении
Блок процедуры Main — вся программа, поэтому перемен ная Global существует на протяжении выполнения программы. Такая переменная называется статической: после того как ей отведена память, она существует до конца программы. Локальная переменная имеет два времени жизни, соответствующие двум вызовам локальной процедуры. Так как эти интервалы не перекрываются, переменной каждый раз можно выделять новое место памяти. Локальные переменные называются автоматическими, потому что память для них автоматически выделяется при вызове процедуры (при входе в блок) и освобождается при возврате из процедуры (при выходе из блока).
Скрытые имена
Предположим, что имя переменной, которое используется в главной программе, повторяется в объявлении в локальной процедуре:
procedure Mam is
Global: Integer;
V: Integer; -- Объявление в Main
procedure Proc(Parm: in Integer) is
Local: Integer;
V: Integer; -- Объявление в Proc
begin
Global := Local + Parm + V; -- Какое именно V используется?
end Proc;
begin -- Main
Global := Global + V; -- Какое именно V используется?
end Main;
В этом случае говорят, что локальное объявление скрывает (или перекрывает) глобальное объявление. Внутри процедуры любая ссылка на V является ссылкой на локально объявленную переменную. С технической точки зрения область действия глобальной переменной V простирается от точки объявления до конца Main, но она невидима в локальной процедуре Ргос.
Скрытие имен переменных внутренними объявлениями удобно тем, что программист может многократно использовать естественные имена типа Current_Key и не должен изобретать странно звучащие имена.
Кроме того, всегда можно добавить
Кроме того, всегда можно добавить глобальную переменную, не беспокоясь о том, что ее имя совпадет с именем какой-нибудь локальной переменной, которое используется одним из программистов вашей группы. Недостаток же состоит в том, что имя переменной могло быть случайно перекрыто, особенно если используются большие включаемые файлы для централизации глобальных объявлений, поэтому, вероятно, лучше избегать перекрытия имен переменных. Однако нет никаких возражений против многократного использования имени в разных областях действия, так как нельзя получить доступ к обеим переменным одновременно независимо от того, являются имена одинаковыми или разными:
procedure Main is
|
Ada |
Index: Integer; -- Одна область действия
…
endProc_1;
procedure Proc_2 is
Index: Integer; -- Неперекрывающаяся область действия
…
end Proc_2;
begin – Main
…
end Main;
Глубина вложения
Принципиальных ограничений на глубину вложения нет, но ее может произвольно ограничивать компилятор. Область действия и видимость определяются правилами, данными выше: область действия переменной — от точки ее объявления до конца блока, а видимость — такая же, если только не скрыта внутренним объявлением. Например:
procedure Main is
|
Ada |
procedure Level_1 is
Local: Integer; -- Внешнее объявление Local
procedure Level_2 is
Local: Integer; --Внутреннее объявление Local
begin -- Level_2
Local := Global; -- Внутренняя Local скрывает внешнюю Local
end Level_2;
begin -- Level_1
Local := Global; -- Только внешняя Local в области действия
Область действия переменной Local, определенной
Level_2:
end Level_1;
begin -- Main
Level_1;
Level_2; -- Ошибка, процедура вне области действия
end Main;
Область действия переменной Local, определенной в процедуре Level_1, простирается до конца процедуры, но она скрыта внутри процедуры Level_2 объявлением того же самого имени.
Считается, что сами объявления процедуры имеют область действия и видимость, подобную объявлениям переменных. Таким образом, область действия Level_2 распространяется от ее объявления в Level_1 до конца Level_1. Это означает, что Level_1 может вызывать Level_2, даже если она не может обращаться к переменным внутри Level_2. С другой стороны, Main не может непосредственно вызывать Level_2, так как она не может обращаться к объявлениям, которые являются локальными для Level_1.
Обратите внимание на возможность запутаться из-за того, что обращение к переменной Local в теле процедуры Level_1 отстоит от объявления этой переменной дальше по тексту программы, чем объявление Local, заключенной внутри процедуры Level_2. В случае многочисленных локальных процедур найти правильное объявление бывает трудно. Чтобы избежать путаницы, лучше всего ограничить глубину вложения двумя или тремя уровнями от уровня главной программы.
Преимущества и недостатки блочной структуры
Преимущество блочной структуры в том, что она обеспечивает простой и эффективный метод декомпозиции процедуры. Если вы избегаете чрезмерной вложенности и скрытых переменных, блочную структуру можно использовать для написания надежных программ, так как связанные локальные процедуры можно хранить и обслуживать вместе. Особенно важно блочное структурирование при выполнении сложных вычислений:
procedure Proc(...) is
-- Большое количество объявлений
begin
-- Длинное вычисление 1
|
Ada |
-- Длинное вычисление 2, вариант 1
В этом примере мы хотели
elsif N = 0 then
-- Длинное вычисление 2, вариант 2
else
-- Длинное вычисление 2, вариант 3
end if;
-- Длинное вычисление 3
end Proc;
В этом примере мы хотели бы не записывать три раза Длинное вычисление 2, а оформить его как дополнительную процедуру с одним параметром:
procedure Proc(...) is
-- Большое количество объявлений
procedure Long_2(l: in Integer) is
begin
-- Здесь действуют объявления Proc
|
Ada |
begin
-- Длинное вычисление 1
if N<0thenl_ong_2(1);
elsif N = 0 then Long_2(2);
else Long_2(3);
end if;
-- Длинное вычисление З
end Proc;
Однако было бы чрезвычайно трудно сделать Long_2 независимой процедурой, потому что пришлось бы передавать десятки параметров, чтобы она могла обращаться к локальным переменным. Если Long_2 — вложенная процедура, то нужен только один параметр, а к другим объявлениям можно непосредственно обращаться в соответствии с обычными правилами для области действия и видимости.
Недостатки блочной структуры становятся очевидными, когда вы пытаетесь запрограммировать большую систему на таком языке, как стандарт Pascal, в котором нет других средств декомпозиции программы.
• Небольшие процедуры получают чрезмерную «поддержку». Предположим, что процедура, преобразующая десятичные цифры в шестнадцате-ричные, используется во многих глубоко вложенных процедурах. Такаясервисная процедура должна быть определена в некотором общем предшествующем элементе. На практике в больших программах с блочной структурой проявляется тенденция появления большого числа небольших сервисных процедур, описанных на самом высоком уровне объявлений. Это делает текст программы неудобным для работы, потому что нужную программу бывает просто трудно разыскать.
• Защита данных скомпрометирована. Любая процедура, даже та, объявление которой в структуре глубоко вложено, может иметь доступ к глобальным переменным.
В большой программе, разрабатываемой группой
В большой программе, разрабатываемой группой программистов, это приводит к тому, что ошибки, сделанные младшим членом группы, могут привести к скрытым ошибкам. Эту ситуацию можно сравнить с компанией, где каждый служащий может свободно обследовать сейф в офисе начальника, а начальник не имеет права проверять картотеки младших служащих!
Эти проблемы настолько серьезны, что каждая коммерческая реализация Pascal определяет (нестандартную) структуру модуля, чтобы иметь возможность создавать большие проекты. В главе 13 мы подробно обсудим конструкции, которые применяются для декомпозиции программы в таких современных языках, как Ada и C++. Однако блочная структура остается важным инструментом детализированного программирования отдельных модулей.
Понимать блочную структуру важно также и потому, что языки программирования реализованы с использованием стековой архитектуры, которая непосредственно поддерживает блочную структуру (см. раздел 7.6).
7.5. Рекурсия
Чаще всего (процедурное) программирование использует итерации, то есть циклы; однако рекурсия — описание объекта или вычисления в терминах самого себя — является более простым математическим понятием, а также мощной, но мало используемой техникой программирования. Здесь мы рассмотрим, как программировать рекурсивные подпрограммы.
Наиболее простой пример рекурсии — функция, вычисляющая факториал. Математически она определяется как:
0! = 1
n! = п х (п - 1)!
Это определение сразу же переводится в программу, которая использует рекурсивную функцию:
int factorial(int n)
|
C |
if (n == 0) return 1 ;
else return n * factorial(n - 1);
}
Какие свойства необходимы для поддержки рекурсии?
• Компилятор должен выдавать чистый код. Так как при каждом обращении к функции factorial используется одна и та же последовательность машинных команд, код не должен изменять сам себя.
• Должна существовать возможность выделять во время выполнения произвольное число ячеек памяти для параметров и локальных переменных.
Первое требование выполняется всеми современными
Первое требование выполняется всеми современными компиляторами. Самоизменяющийся код — наследие более старых стилей программирования и используется редко. Обратите внимание, что если программа предназначена для размещения в постоянной памяти (ROM), то она не может изменяться по определению.
Второе требование определяется временем жизни локальных переменных. В примере время жизни формального параметра n — с момента, когда процедура вызвана, до ее завершения. Но до завершения процедуры делается еще один вызов, и этот вызов требует, чтобы была выделена память для нового формального параметра. Чтобы вычислять factorial(4), выделяется память для 4, затем 3 и т. д., всего пять ячеек. Нельзя выделить память перед выполнением, потому что ее количество зависит от параметра функции во время выполнения. В разделе 7.6 показано, как это требование выделения памяти непосредственно поддерживается стековой архитектурой.
Большинство программистов обратит внимание, что функцию, вычисляющую факториал, можно написать так же легко и намного эффективнее с помощью итерации:
int factorial(int n)
{
|
C |
result = 1;
while (i != 0) {
result = result * i;
i--;
}
return result;
}
Так почему же используют рекурсию? Дело в том, что многие алгоритмы можно изящно и надежно написать с помощью рекурсии, в то время как итерационное решение трудно запрограммировать и легко сделать ошибки. Примером служат алгоритм быстрой сортировки и алгоритмы обработки древовидных структур данных. Языковые понятия, рассматриваемые в гл. 16 и 17 (функциональное и логическое программирование), опираются исключительно на рекурсию, а не на итерацию. Даже для обычных языков типа С и Ada рекурсию, вероятно, следует использовать более часто, чем это делается, из-за краткости и ясности программ, которые получаются в результате.
это структура данных, которая принимает
7.6. Стековая архитектура
Стек — это структура данных, которая принимает и выдает данные в порядке LIFO — Last-In, First-Out (последним пришел, первым вышел). Конструкции LIFO существуют в реальном мире, например стопка тарелок в кафетерии или пачка газет в магазине. Стек может быть реализован с помощью массива или списка (см. рис. 7.5). Преимущество списка в том, что он не имеет границ, а его размер ограничен только общим объемом доступной памяти. Массивы же намного эффективнее и неявно используются при реализации языков программирования.
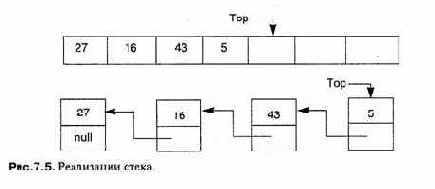
Кроме массива (или списка) в состав стека входит еще один элемент — указатель вершины стека (top-of-stack pointer). Это индекс первой доступной пустой позиции в стеке. Вначале переменная top будет указывать на первую позицию в стеке. На стеке допустимы две операции — push (поместить в стек) и pop (извлечь из стека), push — это процедура, получающая элемент как параметр, который она помещает в вершину стека, увеличивая указатель вершины стека top. pop — это функция, которая возвращает верхний элемент стека, уменьшая top, чтобы указать, что эта позиция стала новой пустой позицией.
Следующая программа на языке С реализует стек целых чисел, используя массив:
|
C |
int stack[Stack_Size];
int top = 0;
void push(int element)
{
if (top == Stack_Size) /* Переполнение стека, предпримите
что-нибудь! * I
else stack[top++] = element;
}
int pop(void)
{
if (top == 0) /* Выход за нижнюю границу стека,
предпримите то-нибудь! */
else return stack[--top];
}
Выход за нижнюю границу стека произойдет, когда мы попытаемся извлечь элемент из пустого стека, а переполнение стека возникнет при попытке поместить элемент в полный стек.
Выход за нижнюю границу стека
Выход за нижнюю границу стека всегда вызывается ошибкой программирования, поскольку вы сохраняете что-нибудь в стеке тогда и только тогда, когда предполагаете извлечь это позднее. Переполнение может происходить даже в правильной программе, если объем памяти недостаточен для вычисления.
Выделение памяти в стеке
Как используется стек при реализации языка программирования? Стек нужен для хранения информации, касающейся вызова процедуры, включая локальные переменные и параметры, для которых память автоматически выделяется после входа в процедуру и освобождается после выхода. Стек является подходящей структурой данных потому, что входы и выходы в процедуры делаются в порядке LIFO, а все нужные данные принадлежат процедуре, которая в цепочке вызовов встречается раньше.
Рассмотрим программу с локальными процедурами:
procedure Main is
G: Integer;
|
Ada |
L1: Integer;
begin ... end Proc_1 ;
procedure Proc_2 is
L2: Integer;
begin... end Proc_2;
begin
Proc_1;
Proc_2;
end Main;

Когда начинает выполняться Main, должна быть выделена память для G. Когда вызывается Ргос_1, должна быть выделена дополнительная память для L1 без освобождения памяти для G (см. рис. 7.6а). Память для L1 освобождается перед выделением памяти для L2, так как Ргос_1 завершается до вызова Ргос_2 (см. рис. 7.66). Вообще, независимо оттого, каким образом процедуры вызывают друг друга, первый элемент памяти, который освобождается, является последним занятым элементом, поэтому память для переменных и параметров может отводиться в стеке.
Рассмотрим теперь вложенные процедуры:
procedure Main is
G: Integer;
|
Ada |
L1: Integer;
procedure Proc_2(P2: Integer) is
L2: Integer;
begin
L2 := L1 + G + P2;
Ргос_2 может вызываться только из
end Proc_2;
begin -- Proc_1
Proc_2(P1);
end Proc_1;
begin -- Main
Proc_1 (G);
end Main;

Ргос_2 может вызываться только из Ргос_1. Это означает, что Ргос_1 еще не завершилась, ее память не освобождена, и место, выделенное для L1, должно все еще оставаться занятым (см. рис. 7.7). Конечно, Ргос_2 завершается раньше Ргос_1, которая в свою очередь завершается раньше Main, поэтому память может быть освобождена с помощью операции pop.
Записи активации
Фактически стек используется для поддержки всего вызова процедуры, а не только для размещения локальных переменных. Сегмент стека, связанный с каждой процедурой, называется записью активации (activation record) для процедуры. Вкратце, вызов процедуры реализуется следующим образом (см. рис. 7.8):

1. В стек помещаются фактические параметры. К ним можно обращаться по смещению от начала записи активации.
2. В стек помещается адрес возврата RA (return address). Адрес возврата — это адрес оператора, следующего за вызовом процедуры.
3. Индекс вершины стека увеличивается на общий объем памяти, требуемой для хранения локальных переменных.
4. Выполняется переход к коду процедуры.
После завершения процедуры перечисленные шаги выполняются в обратном порядке:
1. Индекс вершины стека уменьшается на величину объема памяти, выделенной для локальных переменных.
2. Адрес возврата извлекается из стека и используется для восстановления указателя команд.
3. Индекс вершины стека уменьшается на величину объема памяти, выделенной для фактических параметров.
Хотя этот алгоритм может показаться сложным, на большинстве компьютеров он фактически может быть выполнен очень эффективно. Объем памяти для переменных, параметров и дополнительной информации, необходимой для организации вызова процедуры, известен на этапе компиляции, а описанная технология всего лишь требует изменения индекса стека на константу,
В классическом стеке единственно допустимые
Доступ к значениям в стеке
В классическом стеке единственно допустимые операции — это push и pop. «Рабочий» стек, который мы описали, — более сложная структура, потому что мы хотим иметь эффективный доступ не только к самому последнему значению, помещенному в стек, но и ко всем локальным переменным и ко всем параметрам. В частности, необходимо иметь возможность обращаться к этим данным относительно индекса вершины стека:
|
C |
Однако стек может содержать и другие данные помимо тех, что связаны с вызовом процедуры (например, временные переменные, см. раздел 4.7), поэтому обычно поддерживается еще дополнительный индекс, так называемый указатель дна (bottom pointer), который указывает на начало записи активации (см. раздел 7.7). Даже если индекс вершины стека изменится во время выполнения процедуры, ко всем данным в записи активации можно обращаться по фиксированным смещениям от указателя дна стека.
Параметры
Существуют два способа реализации передачи параметров. Более простым является помещение в стек самих параметров (либо значений, либо ссылок). Этот способ используется в языках Pascal и Ada, потому что в этих языках номер и тип каждого параметра известны на этапе компиляции. По этой информации смещение каждого параметра относительно начала записи активации может быть вычислено во время компиляции, и к каждому параметру можно обращаться по этому фиксированному смещению от указателя дна стека:
load R1 ,bottom_pointer Указатель дна
add R1 ,#offset-of-parameter + смещение
load R2,(R1) Загрузить значение, адрес которого
находится в R1
Если указатель дна сохраняется в регистре, то этот код обычно можно сократить до одной команды.
При выходе из подпрограммы выполняется
При выходе из подпрограммы выполняется очистка стека подпрограммой, которая сбрасывает указатель вершины стека так, чтобы параметры фактически больше не находились в стеке.
При использовании этого метода в языке С возникает проблема, связанная с тем, что С разрешает иметь в процедуре переменное число параметров:
|
C |
Так как количество параметров подпрограмме неизвестно, она не может очистить стек. Ответственность за очистку стека, таким образом, перекладывается на вызыватель, который знает, сколько параметров было передано. Это приводит к некоторому перерасходу памяти, потому что код очистки стека теперь свой при каждом вызове вместо того, чтобы быть общим для всех вызовов.
Когда число параметров неизвестно, возможен альтернативный способ передачи параметров, при котором фактические параметры сохраняются в отдельном блоке памяти, а затем передается адрес этого блока в стек. Для доступа к параметру требуется дополнительная косвенная адресация, поэтому этот метод менее эффективен, чем непосредственное помещение параметров в стек.
Обратите внимание, что иногда нельзя сохранить параметр непосредственно в стеке. Как вы помните, формальный параметр в языке Ada может иметь неограниченный тип массива, границы которого неизвестны во время компиляции:
|
Ada |
Таким образом, фактический параметр не может быть помещен непосредственно в стек. Вместо него в стек помещается дескриптор массива (dope vector) (см. рис. 5.4), который содержит указатель на массив.
Рекурсия
Архитектура стека непосредственно поддерживает рекурсию, поскольку каждый вызов процедуры автоматически размещает новую копию локальных переменных и параметров. Например, при каждом рекурсивном вызове функции факториала требуется одно слово памяти для параметра и одно слово памяти для адреса возврата.
что издержки на рекурсию больше,
То, что издержки на рекурсию больше, чем на итерацию, связано с дополнительными командами, затрачиваемыми на вход в процедуру и выход из нее. Некоторые компиляторы пытаются выполнить оптимизацию, называемую оптимизацией хвостовой рекурсии (tail-recursion) или оптимизацией последнего вызова (last-call). Если единственный рекурсивный вызов в процедуре — последний оператор процедуры, то можно автоматически перевести рекурсию в итерацию.
Размер стека
Если рекурсивных вызовов нет, то теоретически перед выполнением можно просчитать общий размер используемого стека, суммируя размеры записей активации для каждой возможной цепочки вызовов процедур. Даже в сложной программе вряд ли будет трудно сделать приемлемую оценку этого числа. Добавьте несколько тысяч слов про запас, и вы вычислите размер стека, который наверняка не будет переполняться.
Однако при применении рекурсии размер стека во время выполнения теоретически неограничен:
|
C |
j = factorial(i);
В упражнениях приведена функция Акерманна, которая гарантированно переполнит любой стек! Но на практике обычно нетрудно оценить размер стека, даже когда используется рекурсия. Предположим, что размер записи активации приблизительно равен 10, а глубина рекурсии не больше нескольких сотен. Добавления к стеку лишних 10 Кбайт более чем достаточно.
Читатели, которые изучали структуры данных, знают, что рекурсией удобно пользоваться при работе с древовидными структурами в таких алгоритмах, как быстрая сортировка и приоритетные очереди. Глубина рекурсии в алгоритмах обработки древовидных структур данных — приблизительно Iog2 от размера структуры. Для реальных программ глубина рекурсии не превышает 10 или 20, поэтому опасность переполнения стека очень невелика.
Независимо от того, используется рекурсия или нет, сама природа рассматриваемых систем такова, что потенциально возможное переполнение стека должно как-то обрабатываться.
и при критических обстоятельствах разрушаться,
Программа может либо полностью игнорировать эту возможность и при критических обстоятельствах разрушаться, либо проверять размер стека перед каждым вызовом процедуры, что может быть накладно. Компромиссное решение состоит в том, чтобы периодически проверять размер стека и предпринимать некоторые действия, если он стал меньше некоторого предельного значения, скажем 1000 слов.
7.7. Еще о стековой архитектуре
Доступ к переменным на промежуточных уровнях
Мы обсудили, как можно эффективно обращаться к локальным переменным по фиксированным смещениям от указателя дна, указывающего на запись активации. К глобальным данным, т. е. данным, объявленным в главной программе, также можно обращаться эффективно. Это легко увидеть, если рассматривать глобальные данные как локальные для главной процедуры. Память для глобальных данных распределяется при входе в главную процедуру, т. е. в начале программы. Так как их размещение известно на этапе компиляции, точнее, при компоновке, то действительный адрес каждого элемента известен или непосредственно, или как смещение от фиксированной позиции. На практике глобальные данные обычно распределяются независимо (см. раздел 8.3), но в любом случае адреса фиксированы.
Труднее обратиться к переменным на промежуточных уровнях вложения.
procedure Main is
G: Integer,
procedure Proc_1 is
L1: Integer;
|
Ada |
L2: Integer;
begin L2 := L1 + G; end Proc_2;
procedure Proc_3 is
L3: Integer;
begin L3 := L1 + G; Proc_2; end Proc_3;
begin -- Proc_1
Proc_3;
end Proc_1;
begin — Main
Proc_1;
end Main;
Мы видели, что доступ к локальной переменной L3 и глобальной переменной G является простым и эффективным, но как можно обращаться к L1 в Ргос_3? Ответ прост: значение указателя дна сохраняется при входе в процедуру и используется как указатель на запись активации объемлющей процедуры Ргос_1.
и может быть немедленно загружен,
Указатель дна хранится в известном месте и может быть немедленно загружен, поэтому дополнительные затраты потребуются только на косвенную адресацию.

При более глубоком вложении каждая запись активации содержит указатель на предыдущую запись активации. Эти указатели на записи активации образуют динамическую цепочку (см. рис. 7.9). Чтобы обратиться к вышележащей переменной (вложенной менее глубоко), необходимо «подняться» по динамической цепочке. Связанные с этим затраты снижают эффективность работы с переменными промежуточных уровней при большой глубине вложенности. Обращение непосредственно к предыдущему уровню требует только одной косвенной адресации, и эпизодическое глубокое обращение тоже не должно вызывать никаких проблем, но в циклы не следует включать операторы, которые далеко возвращаются по цепочке.
Вызов вышележащих процедур
Доступ к промежуточным переменным фактически еще сложнее, потому что процедуре разрешено вызывать другие процедуры, которые имеют такой же или более низкий уровень вложения. В приведенном примере Ргос_3 вызывает Ргос_2. В записи активации для Ргос_2 хранится указатель дна для процедуры Ргос_3 так, что его можно восстановить, но переменные Ргос_3 недоступны в Ргос_2 в соответствии с правилами области действия.
Так или иначе, программа должна быть в состоянии идентифицировать статическую цепочку, т.е. цепочку записей активации, которая определяет статический контекст процедур согласно правилам области действия, в противоположность динамической цепочке вызовов процедур во время выполнения. В качестве крайнего случая рассмотрим рекурсивную процедуру: в динамической цепочке могут быть десятки записей активации (по одной для каждого рекурсивного вызова), но статическая цепочка будет состоять только из текущей записи и записи для главной процедуры.
Одно из решений состоит в том, чтобы хранить в записи активации статический уровень вложенности каждой процедуры, потому что компилятор знает, какой уровень необходим для каждого доступа.
в примере имеет нулевой уровень,
Если главная программа в примере имеет нулевой уровень, то обе процедуры Ргос_2 и Ргос_3 находятся на уровне 2. При продвижении вверх по динамической цепочке уровень вложенности должен уменьшаться на единицу, чтобы его можно было рассматривать как часть статической цепочки; таким образом, запись для Ргос_3 пропускается, и следующая запись, уже запись для Ргос_1 на уровне 1, используется, чтобы получить индекс дна.

Другое решение состоит в том, чтобы явно включить статическую цепочку в стек. На рисунке 7.10 показана статическая цепочка сразу после вызова Ргос_2 из Ргос_3 . Перед вызовом статическая цепочка точно такая же, как динамическая, а после вызова она стала короче динамической и содержит только главную процедуру и Ргос_1.
Преимущество явной статической цепочки в том, что она часто короче, чем динамическая (вспомните здесь о предельном случае рекурсивной процедуры). Однако мы все еще должны осуществлять поиск при каждом обращении к промежуточной переменной. Более эффективное решение состоит в том, чтобы использовать индикатор, который содержит текущую статическую цепочку в виде массива, индексируемого по уровню вложенности (см. рис. 7.10). В этом случае для обращения к переменной промежуточного уровня, чтобы получить указатель на правильную запись активации, в качестве индекса используется уровень вложенности, затем из записи извлекается указатель дна, и, наконец, прибавляется смещение, чтобы получить адрес переменной. Недостаток индикатора в том, что необходимы дополнительные затраты на его обновление при входе и выходе из процедуры.
Возможная неэффективность доступа к промежуточным переменным не должна служить препятствием к применению вложенных процедур, но программистам следует учитывать такие факторы, как глубина вложенности, и правильно находить компромисс между использованием параметров и прямым доступом к переменным.
7.8. Реализация на процессоре Intel 8086
Чтобы дать более конкретное представление
Чтобы дать более конкретное представление о реализации идей стековой архитектуры, рассмотрим вход в процедуру и выход из нее на уровне машинных команд для процессора серии Intel 8086. В качестве примера возьмем:
procedure Main is
Global: Integer;
procedure Proc(Parm: in Integer) is
Local'1, Local2: Integer;
begin
|
Ada |
end Proc;
begin
Proc(15);
end Main;
Процессор 8086 имеет встроенные команды push и pop, в которых подразумевается, что стек растет от старших адресов к младшим. Для стековых операций выделены два регистра: регистр sp, который указывает на «верхний» элемент в стеке, и регистр bр, который является указателем дна и идентифицирует местоположение начала записи активации.
При вызове процедуры в стек помещается параметр и выполняется команда вызова (call):
mov ax, #15 Загрузить значение параметра
push ax Сохранить параметр в стеке
call Proc Вызвать процедуру
На рисунке 7.11 показан стек после выполнения этих команд — параметр и адрес возврата помещены в стек.

Следующие команды являются частью кода процедуры и выполняются при входе в процедуру; они сохраняют старый указатель дна (динамическая связь), устанавливают новый указатель дна и выделяют память для локальных переменных, уменьшая указатель стека:
push bp Сохранить старый динамический указатель
mov bp, sp Установить новый динамический указатель
sub sp,#4 Выделить место для локальных переменных
Получившийся в результате стек показан на рис. 7.12.

Теперь можно выполнить тело процедуры:
mov ax,ds:[38] Загрузить переменную Global
к глобальным переменным делается через
add ax,[bp+06] Прибавить параметр Parm
add ax,[bp-02] Прибавить переменную Local 1
mov ax,[bp] Сохранить в переменной Local2
Обращение к глобальным переменным делается через смещения относительно специальной области памяти, на которою указывает регистр ds (сегмент данных). К параметру Parm, который располагается в стеке «ниже» начала записи активации, обращаются при положительном смещении относительно bp. К локальным переменным, которые в стеке располагаются «выше», обращаются при отрицательном смещении относительно bp. Важно обратить внимание, что поскольку процессор 8086 имеет регистры и способы адресации, разработанные для обычных вычислений с использованием стека, то ко всем этим переменным можно обращаться одной командой.
При выходе из процедуры должны быть ликвидированы все изменения, сделанные при входе в процедуру:
mov sp,bp Очистить все локальные переменные
pop bp Восстановить старый динамический указатель
ret 2 Вернуться и освободить память параметров
Указатель вершины стека принимает значение указателя дна и таким образом действительно освобождает память, выделенную для локальных переменных. Затем старый динамический указатель выталкивается (pop) из стека, и bр теперь указывает на предыдущую запись активации. Остается только выйти из процедуры, используя адрес возврата, и освободить память, выделенную для параметров. Команда ret выполняет обе эти задачи; операнд команды указывает, сколько байтов памяти, выделенных для параметра, необходимо вытолкнуть из стека.
Подведем итог: как для входа, так и для выхода из процедуры требуется только по три коротких команды, и доступ к локальным и глобальным переменным и к параметрам является эффективным.
Использует ли ваш компилятор Ada
7.9. Упражнения
1. Использует ли ваш компилятор Ada значения или ссылки для передачи массивов и записей?
2. Покажите, как реализуется оптимизация последнего вызова процедуры при рекурсиях. Можно ли выполнить эту оптимизацию для функции факториала?
3. Функция Маккарти определяется следующей рекурсивной функцией:
function M(l: Integer) return Integer is
|
Ada |
if I > 100 then return 1-10;
else return M(M(I + 11));
end M;
а) Напишите программу для функции Маккарти и вычислите M(l) для 80</<110.
б) Смоделируйте вручную вычисление для М(91), показав рост стека.
в) Напишите итерационную программу для функции Маккарти.
4. Функция Акерманна определяется следующей рекурсивной функцией:
function A(M, N: Natural) return Natural is
|
Ada |
if M = 0 then return N + 1 ;
elsif N = 0 then return A(M -1,1);
else return A(M - 1, A(M, N-1));
end A;
а) Напишите программу для функции Акерманна и проверьте, что А(0,0)=1, А(1,1 )=3, А(2,2)=7, А(3,3)=61.
б) Смоделируйте вручную вычисление для А(2,2)=7, проследив за ростом стека.
в) Попытайтесь вычислить А(4,4) и опишите, что при этом происходит. Попробуйте выполнить вычисление, используя несколько компиляторов. Не забудьте перед этим сохранить свои файлы!
г) Напишите нерекурсивную программу для функции Акерманна.
5. Как получить доступ к переменным промежуточной области действия на процессоре 8086?
6. Существует механизм передачи параметров, называемый вызовом по имени (call-by-name), в котором при каждом обращении к формальному параметру происходит перевычисление фактического параметра. Этот механизм впервые использовался в языке Algol, но его нет в большинстве обычных языков программирования.