Работа со скриптом imagemap
. Скрипт imagemap был разработан для организации доступа к документам по графическим гипертекстовым ссылкам. В общем случае это значит, что в текст HTML-документа встроена картинка. Данная картинка разбита на непересекающиеся области различной формы, обычно круги, прямоугольники или полигоны. С каждой из этих областей связан какой-либо объект (HTML-документ, другая картинка, фильм и т.п.). Выбирая мышью точку на этой картинке, пользователь выбирает объект, связанный с областью, которой принадлежит точка объекта и переходит к просмотру этого объекта. Например, на экране пользователя отображена Европейская часть территории Союза с административными границами республик. Выбирая точку внутри административных границ России, можно получить укрупненную карту европейской части России.
Некоторые HTTP-серверы реализуют функции imagemap самостоятельно, но чаще всего в Сети используют отдельный скрипт. Рассмотрим применение данного скрипта для сервера NCSA. Программа imagemap размещается в директории скриптов, обычно это: "/usr/local/etc/httpd/cgi-bin". В директории "/usr/local/etc/httpd/conf" размещается файл конфигурации скрипта. Для каждой картинки создается еще и файл разбиения картинки на области, адрес которого указывается в конфигурации скрипта.
Для организации стека графических ссылок в документе HTML используют следующую конструкцию:
<A href="http://polyn.net.kiae.su/cgi-bin/imagemap/russia"> <IMG SRC="http://demin.polyn.kiae.su/dss/russia.gif" ISMAP> </A>
Таким образом, URL скрипта imagemap в качестве последнего компонента пути содержит аргумент, в данном случае "russia". При использовании этой гипертекстовой ссылки программа-клиент добавляет после слова "russia" последовательность типа "?14,25". Первая цифра определяет координату X на картинке относительно левого ее края, а вторая цифра - координату Y относительно верхнего края картинки. При вызове скрипт ищет свой файл конфигурации, который имеет вид:
# метка : адрес файла описания картинки russia : /usr/local/etc/httpd/cgi-bin/maps/russia.map brussia : /usr/local/etc/httpd/cgi-bin/maps/brussia.map ....
Таким образом, для каждого вызова imagemap определяется описание разбивки картинки на непересекающиеся области. Каждый файл описания такой области может содержать три вида описаний: прямоугольной области, круговой области и полигона. Прямоугольник задается двумя углами: верхним левым и нижним правым, круг - центром и точкой на окружности, полигон - вершинами своих углов. При этом полигон рассматривается как замкнутый многоугольник, который может быть и невыпуклым. В качестве примера такого описания можно рассмотреть следующую запись:
#описание прямоугольника rect 10 20 100 200 circle 50 50 60 60 poly 10 10 20 20 20 10
Практически все программы imagemap имеют ограничения на число вершин полигона, так для MS-Windows 3.1 ограничение равно 100 точкам.
Для разметки картинок используются специальные вспомогательные программы типа mape-dit, которые позволяют сделать процесс разбивки картинки более наглядным и менее трудоемким.
Общей проблемой, связанной с использованием скриптов, является проблема безопасности. Во-первых, скрипты обычно не пишут сами, как, например, скрипт imagemap, а заимствуют. Понятно, что чужая программа может содержать ошибки. Поэтому лучше пользоваться библиотеками проверенных скриптов, которые рекомендованы, например, World Wide Web Consortium. Во-вторых, если пользователю разрешено иметь свои страницы, то он может получить возможность выполнять свои скрипты на сервере, что тоже приводит к брешам в системе безопасности, особенно если это shell-скрипты. Существуют такие скрипты, которые требуют прав доступа к ресурсам машины. Эти права шире, чем права пользователя "nobody", например, при доступе к базам данных. Все эти моменты следует учитывать, как при написании скриптов, так и при разрешении использования различным группам пользователей.
Как правило, новые возможности WWW опробуются на скриптах, а затем, если эти возможности широко используются в практике, они включаются в стандарты различных компонентов системы и могут быть реализованы в новых возможностях серверов, как например imagemap и системы безопасности. Скрипты позволяют новым энтузиастам Сети приобщиться к сообществу и внести свою лепту в развитие системы.
Рассылка на удаленную машину
. Для вызова программы рассылки sendmail открывает pipe и запускает программу рассылки, командная строка которой находится в файле конфигурации. Sendmail записывает заголовок и тело сообщения в pipe. Если программа рассылки не использует протокол SMTP, то адрес получателя передается через pipe. Если используется SMTP, то открывается двунаправленный канал для интерактивного взаимодействия с удаленным сервером SMTP. Если в качестве транспортного протокола используется TCP, то sendmail не запускает внешнюю программу рассылки, а сама инициирует TCP-соединение с удаленным сервером SMTP.
Регистрация доменных имен
Для того, чтобы получить зону надо отправить заявку в РосНИИРОС, который отвечает за делегирование поддоменов в пределах домена ru. В заявке указывается адрес компьютера-сервера доменных имен, почтовый адрес администратора сервера, адрес организации и ряд другой информации. Разберем эту заявку на примере заявки Международной лаборатории VEGA.
domain: vega.ru descr: International Agency VEGA descr: Kurchatov sq. 1 descr: 115470 Moscow descr: Russian Federation admin-c: Pavel B Khramtsov zone-c: Pavel B Khramtsov tech-c: Pavel B Khramtsov nserver: vega-gw.vega.ru nserver: ns.relarn.ru nserver: polyn.net.kiae.su dom-net: 194.226.43.0 changed: paul@kiae.su 961018 source: RIPN
person: Pavel B Khramtsov address: International Agency Vega address: Kurchatov sq. 1 address: 115470 Moscow address: Russian Federation phone: +7 095 1969124 fax-no: +7 095 9393670 e-mail: paul@kiae.su changed: paul@kiae.su 961018 source: RIPN
При заполнении этой заявки следует иметь в виду, что она будет обрабатываться роботом автоматом. Этот автомат проверяет ее на наличие ошибок заполнения и противоречия с существующей базой данных делегированных доменов. Так как робот не терпит неточностей и глух к различного рода просьбам, то заполнять заявку следует аккуратно. Автомат обрабатывает заявку, выделяет в ней записи для базы данных регистрации доменов. Сами эти записи состоят из полей. Каждое поле идентифицируется в заявке именем поля, после которого ставится символ ":".
В строке описания поля "domain:" указывается имя домена, которое вы просите зарегистрировать. РосНИИРОС регистрирует только поддомены домена ru. Регистрировать следует как "прямую" зону, так и "обратную"(см. раздел 3.1.4). В нашем случае это просто зона 43.226.194.inaddr.arpa.
В строке описания поля "descr:" указывают название и адрес организации, которая запрашивает домен. Так как на одной строке эта информация не может разместиться, то команд descr может быть несколько.
В строке описания поля "admin-c:" указывается персона, которая осуществляет администрирование домена. Поле имеет обязательный формат: <имя> <первая буква отчества> <фамилия>. Таких строк может быть несколько, если лиц отвечающих за администрирование домена больше одного. Вместо указанного выше формата можно использовать также и идентификатор персоны, если таковой имеется. Идентификатор называют nichandle, или персональный код.
Поле "zone-c:" заполняется для той персоны, чей почтовый адрес указан в записи SOA в описании зоны. Формат этого поля идентичен формату команды admin-c.
Поле "tech-c:" указывается для технического администратора домена, к которому обращаются в случае экстренных ситуаций. Формат этого поля совпадает с форматом команды admin-c. По моему глубокому убеждению во всех полях (admin-c, zone-c и tech-c) имеет смысл указывать координаты одного и того же человека. Мало кто из российских пользователей Internet может позволить роскошь держать сразу трех разных специалистов на обслуживании сервиса доменных имен. Учитывая отечественные реалии, можно со всей ответственностью утверждать, что кроме неразберихи ни к чему другому большое количество администраторов не приводит.
В строке описания поля "nserver:" указывают доменные имена серверов зоны. Как правило, таких строк в заявке бывает несколько. Первым указывается primary или главный сервер домена. В нашем случае это vega-gw.vega.ru. На этом сервере хранится база данных домена. Вторым указывается secondary или дублирующий сервер домена. В нашем случае это ns.relarn.ru. Дублирующие сервера призваны повысить надежность работы всей системы доменных имен, поэтому дублирующих серверов может быть несколько. Если существуют другие дублирующие сервера, то указываются и они (сервер polyn.net.kiae.su из нашей заявки также является дублирующим для домена vega.ru). При указании дублирующих серверов первым следует указывать тот, который наиболее надежно обслуживает запросы к домену. В нашем примере таким является сервер ns.relarn.ru. Выбран он был по тем соображениям, что регистрация проводилась в РосНИИРОС, специалисты которого администрируют домен relarn.ru. Первоначально, дублирующим сервером был только сервер polyn.net.kiae.su. Однако, медленная скорость разрешения доменных имен в домене kiae.su всем хорошо известна. Это приводит к достаточно большим задержкам при ответах на запросы на расширение имени. Особенно долго обрабатываются обратные запросы. В результате, автомат постоянно выдавал сообщение что сервер polyn.net.kiae.su недоступен, хотя при ручном тестировании все работало нормально. Для того, чтобы решить эту проблему было решено просить разрешения на использование ns.relarn.ru в качестве secondary сервера для домена vega.ru, справедливо полагая, что сервер доменных имен расположенный в том же домене, что и автомат, и сервер установленный на машине, использующий общий коаксиальный кабель с машиной автомата, будет отвечать гораздо оперативнее сервера, расположенного в другом домене, за несколькими репитерами и мостами. При выборе места размещения дублирующих серверов следует иметь в виду, что сначала проверяется возможность взаимодействия именно с этими серверами. Если хотя бы один из них не откликается на запросы автомата, то заявка отклоняется.
Поле "sub-dom:" описывает поддомены домена. В нашей заявке нет поля sub-net, т.к. в домене vega.ru нет поддоменов. Но если бы нам понадобилось изменять структуру домена, а именно, разбить его на зоны, то тогда следовало бы включить в заявку между строками nserver и строкой dom-net строку:
sub-net: zone1 zone2
В этом случае весь домен vega.ru разбит на два поддомена: zone1 и zone2. Например, машина quest из зоны zone1 будет иметь доменное имя quest.zone1.vega.ru, а машина query из зоны zone2 - query.zone2.vega.ru. Поддомены указываются в команде sub-dom через пробел.
Поле "dom-net:" указывает на список IP-сетей данного домена. В нашей заявке указана только одна сеть 194.226.43.0, но если у организации, которая заводит свой собственный домен имеется в наличии несколько сетей, то эти сети можно указать в этом поле, разделяя их пробелами.
Поле "changed:" является обязательным и служит указателем на то лицо, которое последним вносило изменения в заявку. В качестве значения поля после символа ":" указывается почтовый адрес этого лица и, через пробел дата внесения изменения в формате ГГММДД (Г-год, М-месяц, Д-день).
Последняя запись в заявке - это поле source, которое отделяет различные записи во входном потоке данных программы робота. Значение этого поля - RIPN.
Вслед за записью заявки следует запись описания персоны. Именно эта запись позволяет связывать поля admin-c, zone-c, tech-c с информацией о конкретном лице, которая содержится в записи описания персоны.
Запись описания персоны начинается с поля "person:". В данном поле указывается информация о лице (персоне). Обычно, данное поле имеет следующий формат: <имя> <первая буква отчества> <фамилия>.
Поле "address:" вслед за полем "person:". Данное поле состоит из нескольких строк, каждая из которых начинается с имени поля. Первым указывается организация, во второй строке - улица и номер дома, в третьей - почтовый индекс и название города или поселка, в последней строке - название страны. Одним словом - это типичный американский почтовый адрес.
За адресом следует поле "phone:". В нем указывается номер телефона, по которому можно связаться с указанным лицом. Номер задается с указанием номера страны и кода города. Для Москвы - +7 095 ___ __ __. Телефонов можно указать несколько.
Все выше сказанное для поля "phone:" относится и к полю "fax-no:". В этом поле указывается номер телефакса.
Самым важным, на мой взгляд, из всех полей, определяющих координаты персоны, является поле адреса электронной почты - "e-mail:", хотя оно и не является обязательным полем заявки. Адрес электронной почты указывается как адрес электронной почты Internet. Для абонентов других сетей возможны проблемы с регистрацией их адресов, т.к. указание символов "!", "%", "::" нежелательно.
В поле "nic-hdl:" указывается персональный номер пользователя, если он у данного пользователя есть. Поле не является обязательным, но, как подчеркивается в инструкции по заполнению заявок "крайне желательно".
Последним полем в описании персоны, как и в заявке на домен, является поле "source:". В заявке можно указать несколько персон, что породит для каждой из них свою собственную запись в базе данных описания доменов. Информация о зоне и лицах, которые ответственны за ведение зоны (и не только о них) можно найти по команде:
/usr/paul>whois -h whois.ripn.net <имя зоны или персоны>
Теперь после описания самой заявки перейдем к описанию ее регистрации. После того как заявка отправлена, следует настроить и запустить сервер в локальном режиме. Администратор РосНИИРОС обычно извещает о том, что у администрации домена ru нет претензий к вашей заявке и разрешает запустить ваш сервер для тестирования. Если в домене есть уже запрашиваемый вами поддомен или у администрации домена ru есть другие возражения по поводу регистрации вашего домена, то администрация домена ru вас об этом известит.
Если у администратора домена ru нет причин для отказа в регистрации, то он разрешает запуск сервера для тестирования. Если ваш сервер уже запущен, то это сообщение вы просто примете к сведению, если нет, то нужно срочно, обычно в течении 2-х часов настроить и запустить сервер (вообще-то, запускать надо сразу как только решили отправлять заявку).
Еще раз обратите внимание на то, что заявка, отправленная на адрес ru-dns@RIPN.net попадает на автомат обработки заявок, с которым бесполезно вступать в пререкания и прения по поводу различного рода ошибок и неточностей. При этом проблемы с регистрацией могут возникать как по вине заявителя (ошибки в полях заявки, например), так и по вине регистрирующей стороны. Так, например, регистрация домена vega.ru длилась почти два месяца из-за того, что в начале были ошибки в заявке, потом были выявлены несоответствия заявки и описания зоны, затем сломался автомат регистрации и заявка была утеряна. Затем возникли проблемы с дублирующим сервером зоны (слишком большое время отклика, из-за которого автомат отклонял заявку). При этом и сам автомат работал медленно, т.к. проблема скорости разрешения запросов на серверах имен РНЦ "Курчатовский Институт" хорошо всем известна. Поэтому лучше всего сразу узнать телефон администратора и общаться с ним непосредственно.
Именно "телефон", и об этом упоминается не случайно. Общение с администраторами по электронной почте ни к чему хорошему, в большинстве случаев, не приводит. Как правило, вы будете получать назад ваши же письма откомментированные администратором, который в момент отправки этого письма мгновенно забывает о ваших проблемах. Вообще, вся эта переписка напоминает разговор двух склеротиков, когда строк типа: "В письме от такого-то числа пользователь написал..." становится больше, чем содержательной информации. Выискивать в большом письме комментарии, которые могут занимать не больше двух слов трудно и нудно. Особенно глупо это выглядит если вы, того не ведая, вступите в переписку с автоматом. Я никому не хочу навязывать правила поведения в сети, но должны же существовать какие-то нормы, обусловленные здравым смыслом.
При размещении сервера домена следует позаботиться о том, чтобы существовал вторичный (secondary) сервер имен вашего домена. Согласно большинству рекомендаций, следует иметь от 2-х до 4-х серверов на случай отказа основного сервера доменных имен.
Вообще говоря, можно вести переговоры о создании вторичного сервера доменных имен и с самим РосНИИРОС и с любым провайдером. Но за услуги последнего придется заплатить. Можно запустить вторичный сервер и на одном из своих компьютеров, но в этом случае вы просто выполните требования РосНИИРОС формально, так как надежности процедуре разрешения имен вашего домена такое решение не принесет.

Рис.3.4. Схема подключения локальной сети к провайдеру
Действительно, если ваша сеть подключена к провайдеру через один единственный шлюз (рисунок 3.4), то все ваши компьютеры, оказываются за шлюзом. При отказе шлюза все они для внешнего пользователя сети исчезают, а это значит, что если сервер доменных имен расположен на шлюзе или одном из компьютеров вашей сети, то для внешнего пользователя и их имена исчезнут также, в отличии от IP-адресов, которые прописаны в маршрутизаторе провайдера.
На первый взгляд кажется, что если нет доступа, то и трансляция доменных имен в IP-адресе не нужна. Однако, это не совсем так. Если система не может разрешить доменное имя, то она сообщает - "unknown host", т.е. система такого компьютера не знает. Если же доменное имя успешно транслируется в IP-адрес, то, в случае потери связи, система сообщает - "host un-reachable", т.е. система знает о такой машине, но в данный момент достичь эту машину нет никакой возможности.
В критических ситуациях не всегда можно быстро сообразить, что происходит в сети, поэтому разница в сообщениях важна - она позволяет избежать лишних непродуманных действий.
В РосНИИРОС регистрируют не только "прямую" зону, но также и "обратную". Это две самостоятельные заявки. Понятие "прямая" зона - это калька с английского - forward zone, а понятие "обратная" зона - reverse zone. "Прямая" зона определяет соответствие доменного имени IP-адресу, в то время, как "обратная" зона определяет обратное соответствие IP-адреса доменному имени.
Режимы обмена данными
В протоколе большое внимание уделяется различным способам обмена данными между машинами различных архитектур. Действительно, чего только нет в Internet, от персоналок и Mac'ов до суперкомпьютеров. Все они имеют различную длину слова и многие различный порядок битов в слове. Кроме этого, различные файловые системы работают с разной организацией данных, которая выражается в понятии метода доступа.
В общем случае, с точки зрения FTP, обмен может быть поточный или блоковый, с кодировкой в промежуточные форматы или без нее, текстовый или двоичный. При текстовом обмене все данные преобразуются в ASCII и в этом виде передаются по сети. Исключение составляют только данные IBM mainframe, которые по умолчанию передаются в EBCDIC, если обе взаимодействующие машины IBM. Двоичные данные передаются последовательностью битов или подвергаются определенным в процессе сеанса управления преобразованиям. Обычно, при поточной передаче данных за одну сессию передается один файл данных, при блоковом способе за одну сессию можно передать несколько файлов.
Описав в общих чертах протокол обмена, можно перейти к описанию средств обмена по протоколу FTP. Практически для любой платформы и операционной cреды существуют как серверы, так и клиенты. Ниже описываются стандартные сервер и клиент Unix-подобных систем.
"Richtext"
определяет текст со встроенными в него специальными управляющими последовательностями, которые в соответствии со стандартом языка разметки документов SGML (Standard Generalized Markup Language) называются тагами. Таги представляют из себя последовательность символов типа "<строка-символов>". "Строка-символов" определяет управляющее действие. Таги делятся на таги начала элемента текста ("<......>") и таги конца элемента текста ("</......>"). В качестве примера такой разметки можно привести следующий фрагмент текста:
<bold>Now</bold> is the time for <italic>all</italic> good men <smaller>(and <lt>women>)</smaller> to <ignoreme></ignoreme> come to the aid of their <nl>
В этом фрагменте <bold> означает выделение "жирным" шрифтом, <italic> - курсив, <smaller> - мелкий шрифт, <lt> - знак "<", игнорирование обозначено как <ignoreme>, новая строка как <nl>. Далее приведен полный перечень управляющих последовательностей:
| Bold | "жирный" шрифт |
| Italic | курсив |
| Fixed | causes the subsequent text to be in a fixed width font |
| Smaller | уменьшенный шрифт |
| Bigger | увеличенный шрифт |
| Underline | подчеркнутый текст |
| Center | отцентрированный текст |
| FlushLeft | выровненный по левому краю |
| FlushRight | выровненный по правому краю |
| Indent | отступ от левого края |
| IndentRight | отступ от правого края |
| Outdent | отмена левого отступа |
| OutdentRight | отмена правого отступа |
| SamePage | размещение текста на одной странице |
| Subscript | подстрочный текст |
| Superscript | надстрочный текст |
| Heading | заголовок |
| Footing | текст ссылки |
| ISO-8859-X | текст в кодировке ISO-8859-X |
| US-ASCII | текст в кодировке US-ASCII |
| Excerpt | цитата |
| Paragraph | параграф |
| Signature | автограф (подпись) |
| Comment | комментарий (не отображается) |
| No-op | нет операции |
| lt | знак "меньше"("<") |
| nl | новая строка |
| np | новая страница |
Специальный тип разметки задается подтипом "html". Это так называемый гипертекст. Разметка гипертекста строится по тому же принципу, как и в тексте типа "richtext". Однако применяются таги, позволяющие описать гипертекстовые ссылки. К таким тагам относятся "<A HREF="......">.....</A>", <IMG ....>, <A NAME="...."></A>. Таг "<A HREF="......"> .......</A>" определяет следующий фрагмент текста, который будет просматриваться. При этом текст между тагом начала и тагом конца выделяется в программе просмотра цветом или другим способом и используется как контекстная гипертекстовая ссылка. Таг <IMG .....> задет встроенный в текст документа графический образ. В некотором смысле этот таг аналогичен "multipart", который разрешает комбинировать сообщение из нескольких фрагментов разного типа. Таг <A NAME...> определяет "якорь", т.е. место внутри документа, на которое можно сослаться как на метку. В качестве примера такой разметки текста можно привести следующий фрагмент:
Это пример разметки документа в формате HTML. <H1> Это заголовок документа</H1> <P> - Это параграф. <A HREF="test.html#mark1"> Это пример гипертекстовой ссылки.</A> <IMG SRC="test.gif" ALIGN=Bottom> Это встроенный image. <A NAME="mark1"></A> Это "якорь" внутри текста документа.
Search engine
- поисковая машина служит для трансляции запроса пользователя, который подготавливается на информационно-поисковом языке (ИПЯ), в формальный запрос системы, поиска ссылок на информационные ресурсы Сети и выдачи результатов этого поиска пользователю.
Secondary
- определяет зону, для которой данный сервер является secondary server, а также определяет адреса других серверов для этой зоны, обычно primary server, и имя файла где будет вестись копия базы данных этой зоны. Файл размещается в директории, указанной в команде directory.
Secondary server
- это дублирующий сервер зоны. Он также способен отвечать на запросы прикладных программ и других серверов, требующих разрешения доменных имен IP-адресами и/или наоборот, как и primary server. Главное отличие от primary server заключается в том, что secondary server не имеет своей базы данных зоны, а копирует ее с primary server в момент своего запуска и затем заботится о поддержке соответствия между скопированной базой данных и базой данных primary server в соответствии с настройками последнего.
Сервер-посредник(proxy)
не является, в прямом смысле этого слова, сервером. Его задача состоит в обслуживании запросов не к своей собственной базе данных, а к World Wide Web в целом. Это значит, что для внешнего мира вся организация, т.е. все пользователи организации, представлена в виде всего одного адреса, с которого сервер отправляет запросы на другие серверы сети. Такой метод позволяет скрыться за межсетевым фильтром.
Сервер протокола - программа ftpd
Команда ftpd предназначена для обслуживания запросов на обмен информацией по протоколу FTP. Сервер обычно стартует в момент загрузки компьютера. Синтаксис запуска сервера следующий:
ftpd [-d] [-1] [-t timeout] d - опция отладки; 1 - опция автоматической идентификации пользователя; t - время пассивного ожидания команд пользователя.
Каждый сервер имеет свое описание команд, которое можно получить по команде help. Автоматическая идентификация пользователей осуществляется при помощи файла /etc/passwd. Пароль пользователя не должен быть пустым.
Существует специальный файл, в котором содержатся запрещенные пользователи, т.е. те, кому обслуживание по протоколу FTP запрещено. Возможен вход в архив по идентификатору пользователя anonymous или ftp. В этом случае сервер принимает меры по ограничению доступа к ресурсам компьютера для данного пользователя. Обычно для таких пользователей создается специальная директория ftp, в которой размещают каталоги bin, etc и pub. В каталоге bin размещаются команды, разрешенные для использования, а в каталоге pub собственно сами файлы. Каталог etc закрыт для просмотра пользователем и в нем размещены файлы идентификации пользователей.
В ряде случаев в директории pub создают каталог incoming. Этот каталог предназначен для того, чтобы пользователь мог записать в этот каталог свои программы или любые другие файлы. Однако, это довольно небезобидная, с точки зрения безопасности, операция.
В директорию bin обычно записывается только одна команда ls. Данная команда позволяет выполнять просмотр текущей директории. Согласно правилам, анонимный пользователь должен иметь возможность выполнять только те команды, которые размещены в этой директории. Однако, в большинстве систем анонимный пользователь выполняет гораздо больший набор команд, при этом эти команды берутся из стандартных директорий системы. Способность этого пользователя создавать директории, удалять файлы и т.п. будет зависеть от прав, которые установлены администратором для той ветви, файловой системы, в которой располагается файловый архив FTP. Так, например, в Windows NT можно так назначить права, что при входе пользователя с консоли он сможет получить доступ к системе, а при доступе к своему архиву FTP пользователь таких прав не получает, точнее пользователь нормально идентифицируется и проходит аутентификацию, но после этого получает сообщение, что не обладает нужными правами для доступа к своей домашней директории. При этом данная проблема в рамках программ настроек Internet Information Services не решается. Приходится использовать стандартные средства Windows, определяющие эти права.
Другую опасность для системы представляют ссылки. Многие администраторы полагают, что взлом системы - это ситуация, когда злоумышленник проник в систему, однако это не так. Например, в классификации CERT тяжелый взлом - это, в том числе и выявление структуры файловой системы. В этом случае атакующий получает информацию о предмете атаки и может сосредоточить свои усилия на каком-то отдельном фрагменте системы.
Если в директорию etc не скопировать файл passwd, то никто не сможет получить доступ к данным FTP-архива. Однако, часто копируют настоящий файл паролей. Этого делать не следует. Во всяком случае следует убедиться в том, что поле паролей в записях описания пользователей должно быть пустым. Клиент FTP только проверяет наличие пользователя и наличие у него пароля, а идентификация проводится стандартным для системы способом через программу login.
Ниже приведена структура корня FTP-архива (рисунок 3.24).

Рис. 3.24. Структура ftp-архива
Серверы доменных имен и механизм поиска IP-адреса
В данном разделе речь пойдет о программе, которая называется named. Именно она используется в большинстве Unix-систем в качестве реализации Berkeley Internet Name Domain - BIND.
Как и любой другой сервис прикладного уровня, а система доменных имен - это сервис прикладного уровня, программа named использует транспорт TCP и UDP (порты 53). Очень часто пользователи сообщают администратору системы, что та или иная машина системе не известна, хотя вчера с ней можно было работать. При этом, как правило, называют доменные имена компьютеров. Первое, что следует проверить в этой ситуации - реальную доступность к компьютеру по его IP-адресу. Проблема действительно является серьезной, если и по IP-адресу нельзя "достучаться" до удаленной машины, в противном случае следует искать ошибки или отказы в работе сервиса доменных имен.
Сервис BIND строится по схеме "клиент-сервер". В качестве клиентской части выступает процедура разрешения имен - resolver, а в качестве сервера, в нашем случае, программа named.
Resolver, собственно, не является какой-либо программой. Это набор процедур из системной библиотеки (libс.a), которые позволяют прикладной программе, отредактированной с ними, получать по доменному имени IP-адрес компьютера или по IP-адресу доменное имя. Сами эти процедуры обращаются к системной компоненте resolver, которая ведет диалог с сервером доменных имен и таким образом обслуживает запросы прикладных программ пользователя.
На запросы описанных выше функций в системах Unix отвечает программа named. Идея этой программы проста - обеспечить как разрешение, так называемых, "прямых" запросов, когда по имени ищут адрес, так и "обратных", когда по адресу ищут имя. Управляется named специальной базой данных, которая состоит из нескольких фалов, и содержит соответствия между адресами и именами, а также адреса других серверов BIND, к которым данный сервер может обращаться в процессе поиска имени или адреса.
Общую схему взаимодействия различных компонентов BIND можно изобразить так, как это представлено на рисунке 3.5.

Рис. 3.5. Нерекурсивная процедура на разрешение имени
Опираясь на схему нерекурсивной процедуры разрешения имени (рисунок 3.5) рассмотрим два способа разрешения запроса на получение IP-адреса по доменному имени.
В первом случае будем рассматривать запрос на получение IP-адреса в рамках зоны ответственности данного местного сервера имен:
Прикладная программа через resolver запрашивает IP-адрес по доменному имени у местного сервера. Местный сервер сообщает прикладной программе IP-адрес запрошенного имени.
Для того, чтобы еще больше прояснить данную схему взаимодействия рассмотрим несколько примеров, когда появляется запрос на получение IP-адреса по доменному имени.
При входе в режиме удаленного терминала на компьютер polyn.net.kiae.su по команде:
/usr/paul>telnet polyn.net.kiae.su
/usr/paul>telnet polyn.net.kiae.su trying 144.206.130.137 ... login: .....
Строчка, в которой указан IP-адрес компьютера polyn.net.kiae.su, показывает, что к этому времени доменное имя было успешно разрешено сервером доменных имен и прикладная программа, в данном случае telnet получила на свой запрос IP-адрес. Таким образом, после ввода команды с консоли и до появления IP-адреса на экране монитора прикладная программа осуществила запрос к серверу доменных имен и получила ответ на него.
Довольно часто можно столкнуться с ситуацией, когда после ввода команды довольно долго приходиться ждать ответа удаленной машины, но зато после первого ответа удаленный компьютер начинает реагировать на команды с такой же скоростью, как и ваш собственный. В данном случае скорее всего в задержке виноват сервис доменных имен. Наиболее заметно такой эффект проявляется при использовании программы ftp. Например, при обращении к финскому архиву ftp.funet.fi, после ввода команды:
/usr/paul>ftp ftp.funet.fi
система долго не отвечает, но затем начинает быстро "сглатывать" и идентификатор и почтовый адрес, если входят как анонимный пользователь, и другие FTP-команды.
Другой пример того же сорта - это программа traceroute. Здесь задержка на запросы к серверу доменных имен проявляется в том, что время ответов со шлюзов, на которых "умирают" ICMP пакеты, указанное в отчете, маленькое, а задержки с отображением каждой строчки отчета довольно большие. В системе Windows 3.1 некоторые программы трассировки, показывают сначала IP-адрес шлюза, а только потом, после разрешения "обратного" запроса, заменяют его на доменное имя шлюза. Если сервис доменных имен работает быстро, то эта подмена практически незаметна, но если сервис работает медленно, то промежутки бывают довольно значительными.
Если в примере с telnet и ftp мы рассматривали, только "прямые" запросы к серверу доменных имен, то в примере с traceroute мы впервые упомянули "обратные" запросы. В "прямом" запросе прикладная программа запрашивает у сервера доменных имен IP-адрес, сообщая ему доменное имя. При "обратном" запросе прикладная программа запрашивает доменное имя, сообщая серверу доменных имен IP-адрес.
Следует заметить, что скорость разрешения "прямых" и "обратных" запросов в общем случае разная. Все зависит от того как описаны "прямые" и обратные "зоны" в базах данных серверов доменных имен, обслуживающих домен. Часто прямая зона бывает одна, а вот обратных зон может быть несколько, в силу того, что домен расположен на физически разных сетях или подсетях. В этом случае время разрешения "обратных" запросов будет больше времени разрешения "прямых" запросов. Более подробно этого вопроса мы коснемся при обсуждении файлов конфигурации программы named.
Процедура разрешения "обратных" запросов точно такая же, как и процедура разрешения "прямых" запросов, описанная выше.

Рис. 3.6. Нерекурсивный запрос resolver
Собственно нерекурсивным, рассмотренный выше запрос является только с точки зрения сервера, т.е. программы named. С точки зрения resolver процедура разрешения запроса является рекурсивной, так как resolver перепоручил named заниматься поиском нужного сервера доменных имен. Согласно RFC-1035, resolver и сам может опрашивать удаленные серверы доменных имен и получать от них ответы на свои запросы. Во многих Unix-системах именно так оно и сделано. В этом случае resolver обращается к локальному серверу доменных имен, получает от него адрес одного из серверов домена root, опрашивает сервер домена root, получает от него адрес удаленного сервера нужной зоны, опрашивает этот удаленный сервер и получает IP-адрес если он посылал, так называемый "прямой" запрос.
Как видно из этой схемы resolver сам нашел нужный IP-адрес. Однако чаще всего resolver не порождает нерекурсивных запросов, а переадресовывает их локальному серверу доменных имен. Кроме этого и локальный сервер и resolver не все запросы выполняют по указанной процедуре. Дело в том, что существует кэш, который используется для хранения в нем полученной от удаленного сервера информации (рисунок 3.7).

Рис. 3.7. Схема разрешения запросов с кэшированием ответов
Если пользователь обращается в течении короткого времени к одному и том же ресурсу сети, то запрос на удаленный сервер не отправляется, а информация ищется в кэше. Вообще говоря, прядок обработки запросов можно описать следующим образом:
поиск ответа в локальном кэше; поиск ответа на локальном сервере; поиск информации в сети.
При чем кэш может быть как у resolver'а, так и у сервера, но чаще всего эти временные хранилища информации о системе DNS объединяют.
Рассмотрим теперь нерекурсивный запрос прикладной программы к серверу доменных имен на получение IP-адреса по доменному имени из домена, который находится в ведении удаленного сервера доменных имен, т.е. сервера отличного от того, домену которого принадлежит компьютер, осуществляющий запрос. При рассмотрении этого запроса также будем опираться на схему с рисунка 3.5.
В общем виде такая схема будет выглядеть следующим образом:
Прикладная программа обращается к местному серверу доменных имен за IP-адресом, сообщая ему доменное имя. Сервер определяет, что адрес не входит в данный домен и обращается за адресом сервера запрашиваемого домена к корневому серверу доменных имен. Корневой сервер доменных имен сообщает местному серверу доменных имен адрес сервера доменных имен требуемого домена. Местный сервер доменных имен запрашивает удаленный сервер на предмет разрешения запроса своего клиента (прикладной программы) Удаленный сервер сообщает IP-адрес местному серверу. Местный сервер сообщает IP-адрес прикладной программе.
Среди указанных выше примеров, пример обращения к финскому ftp-архиву как раз и является иллюстрацией такой много ступенчатой схемы разрешения "прямого" запроса.
Однако, не всегда при разрешении запросов местный сервер обращается к корневому серверу. Дело в том, что, как указывает Крэг Ричмонд, существует разница между доменом и зоной. Домен - это все множество машин, которые относятся к одному и тому же доменному имени. Например, все машины, которые в своем имени имеют постфикс kiae.su относятся к домену kiae.su. Однако, сам домен разбивается на поддомены или, как их еще называют, зоны. У каждой зоны может быть свой собственный сервер доменных имен. Разбиение домена на зоны и организация сервера для каждой из зон называется делегирование прав управления зоной соответствующему серверу доменных имен, или просто делегированием зоны.
При настройке сервера, в его файлах конфигурации можно непосредственно прописать адреса серверов зон. В этом случае обращения к корневому серверу не производятся, т.к. местный сервер сам знает адреса удаленных серверов зон. Естественно, что все это относится к серверу, который делегирует права.
Существует еще и другой вариант работы сервера, когда он не запрашивает корневой сервер на предмет адреса удаленного сервера доменных имен. Это происходит тогда, когда незадолго до этого сервер уже разрешал задачу получения IP-адреса по данному доменному имени. Если требуется получить IP-адрес, то он будет просто извлечен из буфера сервера, т.к. в течении определенного времени, заданного в конфигурации сервера, этот адрес будет храниться в cache-сервере. Если нужен адрес из того же домена, который был указан в одном из имен, которые разрешались до этого, то сервер не будет обращаться к корневому серверу, т.к. адрес удаленного сервера для этого домена также хранится в кэше местного сервера.
Вообще говоря, понятия "зона" и "домен" носят локальный характер и отражают только тот факт, что при настройках и взаимодействии между собой серверы доменных имен исходят из двухуровневой иерархии. Это значит, что если в зоне необходимо создать разделение на группы, то зону можно назвать доменом, и в нем организовать новые зоны. Например, у компании Sun Microsystems есть зона russia в домене sun.com (russia.sun.com). Так вот, эту зону тоже можно разбить на зоны, например, info.russia.sun.com и market.russia.sun.com.
Кроме нерекурсивной процедуры разрешения имен возможна еще и рекурсивная процедура разрешения имен. Ее отличие от описанной выше нерекурсивной процедуры состоит в том, что удаленный сервер сам опрашивает свои серверы зон, а не сообщает их адреса местному серверу доменных имен. Рассмотрим эти два случая более подробно.
На рисунке 3.8 продемонстрирована нерекурсивная процедура разрешения IP-адреса по доменному имени. Основная нагрузка в этом случае ложится на местный сервер доменных имен, который осуществляет опрос всех остальных серверов. Для того, чтобы сократить число таких обменов, если позволяет объем оперативной памяти, можно разрешить буферизацию (кэширование) адресов. В этом случае число обменов с удаленными серверами сократится.
На рисунке 3.9 удаленный сервер домена сам разрешает запрос на получение IP-адреса хоста своего домена, используя при этом нерекурсивный опрос своих серверов поддоменов.

Рис. 3.8. Нерекурсивная обработка запроса на получение IP-адреса

Рис. 3.9. Рекурсивная и нерекурсивная процедуры разрешения адреса по IP-имени
При этом локальный сервер сразу получает от удаленного сервера адрес хоста, а не адреса серверов поддоменов. Последний способ получения адреса называют рекурсивным, т.е. локальный и удаленный серверы взаимодействуют по рекурсивной схеме, а удаленный и серверы поддоменов по нерекурсивной.
Теперь от общих рассуждений перейдем к описанию настроек системы разрешения доменных имен в BIND.
Сессия
- это множество обращений одного и того же пользователя к страницам базы данных за ограниченный промежуток времени. При этом время между посещениями страниц равно времени их прочтения. При работе с ресурсами Web нельзя точно определить сессию, т.к. если ее начало еще можно проидентифицировать, то определить конец сессии довольно трудно. Программное обеспечение пользователя не сообщает об окончании работы данной сессии. Следует заметить, что разные разработчики программ-клиентов WWW и серверов стремятся найти решение этой проблемы. В частности Netscape Communication предлагает в качестве решения ввести дополнительный атрибут в протокол обмена информации, который будет определять идентификатор сессии. Идентификатор должен сообщаться клиенту сервером и храниться у клиента в течении сеанса работы с данным сервером.
Схема FILE
. WWW-технология используется как в сетевом, так и в локальном режимах. Для локального режима используют схему FILE.
file:///C|/text/html/index.htm
В данном примере приведено обращение к локальному документу на персональном компьютере с MS-DOS или MS-Windows. Следует заметить, что данная схема не может быть применена к CGI-скриптам. Очень часто, однако, пользователи пытаются применить file к скрипту, что является ошибкой. Любой скрипт может быть запущен только сервером HTTP, т.к. ему надо передавать параметры и данные. Клиент запускает только программы просмотра на основе MIME-типов из заголовка сообщений сервера или по расширению файла.
Существует еще несколько схем. Эти схемы практически не используются или находятся в стадии разработки, поэтому останавливаться на них мы не будем.
Из приведенных выше примеров видно, что спецификация адресов ресурсов URI является довольно общей и позволяет проидентифицировать практически любой ресурс Internet. При этом число ресурсов может расширяться за счет создания новых схем. Они могут быть похожими на существующие, а могут и отличаться от них. Реальный механизм интерпретации идентификатора ресурса, опирающийся на URI, называется URL и пользователи WWW имеют дело именно с ним.
Схема FTP
. Данная схема позволяет адресовать файловые архивы FTP из программ-клиентов World Wide Web. При этом программа должна поддерживать протокол FTP. В данной схеме возможно указание не только имени схемы, адреса FTP-архива, но и идентификатора пользователя и даже его пароля. Наиболее часто данная схема используется для доступа к публичным архивам FTP:
ftp://polyn.net.kiae.su/pub/0index.txt
В данном случае записана ссылка на архив "polyn.net.kiae.su" c идентификатором "anonymous" или "ftp" (анонимный доступ). Если есть необходимость указать идентификатор пользователя и его пароль, то можно это сделать перед адресом машины:
ftp://nobody:password@polyn.net.kiae.su/users/local/pub
В данном случае эти параметры отделены от адреса машины символом "@", а друг от друга двоеточием. В некоторых системах можно указать и тип передаваемой информации, но данная возможность не стандартизирована. Стандарт рекомендует определять тип по характеру данных (текстовая информация - ASCII, двоичная - IMAGE). Следует также учитывать, что употребление идентификатора пользователя и его пароля не рекомендовано, т.к. данные передаются незашифрованными и могут быть перехвачены. Реальная защита в WWW осуществляется другими средствами и построена на других принципах.
Схема Gopher
. Данная схема используется для ссылки на ресурсы распределенной информационной системы Gopher. Схема состоит из идентификатора и пути, в котором указывается адрес Gopher-сервера, тип ресурса и команда Gopher.
gopher://gopher.kiae.su:70:/7/kuku
В данном примере осуществляется доступ к gopher-серверу gopher.kiae.su через порт 70 для поиска (тип 7) слова "kuku". Следует заметить, что gopher-тип, в данном случае 7, передается не перед командой, а вслед за ней.
Схема HTTP
. Это основная схема для WWW. В схеме указывается ее идентификатор, адрес машины, TCP-порт, путь в директории сервера, поисковый критерий и метка. Приведем несколько примеров URI для схемы HTTP:
http://polyn.net.kiae.su/polyn/manifest.html
Это наиболее распространенный вид URI, применяемый в документах WWW. Вслед за именем схемы (http) следует путь, состоящий из доменного адреса машины и полного адреса HTML-документа в дереве сервера HTTP.
В качестве адреса машины допустимо использование и IP-адреса:
http://144.206.160.40/risk/risk.html
Если сервер протокола HTTP запущен на другой, отличный от 80 порт TCP, то это отражается в адресе:
http://144.206.130.137:8080/altai/index.html
При указании адреса ресурса возможна ссылка на точку внутри файла HTML. Для этого вслед за именем документа может быть указана метка внутри документа:
http://polyn.net.kiae.su/altai/volume4.html#first
Символ "#" отделяет имя документа от имени метки. Другая возможность схемы HTTP - передача параметров. Первоначально предполагалось, что в качестве параметров будут передаваться ключевые слова, но, по мере развития механизма СGI-скриптов, в качестве параметров стала передаваться и другая информация.
http://polyn.net.kiae.su/isindex.html?keyword1+keyword2
В данном примере предполагается, что документ "isindex.html" - документ с возможностью поиска по ключевым словам. При этом в зависимости от поисковой машины (программы, реализующей поиск) знак "+" будет интерпретироваться либо как "AND", либо как "OR". Вообще говоря, "+" заменяет " " (пробел) и относится к классу неотображаемых символов. Если необходимо передать такой символ в строке параметров, то следует передавать в шестнадцатеричном виде его ASCII-код.
http://polyn.net.kiae.su/isindex.html?keyword1%20keyword2
В данном случае имеется один параметр, в котором два слова разделены пробелом. Символ "%" обозначает начало ASCII-кода, который продолжается до первого символа, отличного от цифры.
При использовании HTML Forms параметры передаются как поименованные поля:
http://polyn.net.kiae.su/isindex.html?field1=value1+field2=value
Значения "field1" и "field2" - это имена полей, а "value1" и "value" - их значения. При этом приведенному выше URI может соответствовать следующая HTML-форма:
<FORM ACTION=http://polyn.net.kiae.su/cgi-bin/test> Введите значения полей:<BR> Поле "field1":<INPUT NAME="filed1" VALUE="value1"><BR> Поле "field2":<INPUT NAME="field2" VALUE="value2"><BR> <HR> </FORM>
Схема MAILTO
. Данная схема предназначена для отправки почты по стандарту RFC-822 (стандарт почтового сообщения). Общий вид схемы выглядит как:
mailto:paul@quest.polyn.kiae.su
Схема NEWS
. Данная схема используется для просмотра сообщений системы Usenet. Для этой схемы используется следующая нотация:
news:comp.infosystems.gopher
В данном случае можно получить статьи из группы "comp.infosystems.gopher" в режиме уведомления. Можно получить и текст статьи, но в этом случае указывают ее идентификатор:
news:086@comp.infosystems.gopher
Заказана 86 статья из группы.
Схема NNTP
. Это еще одна схема получения доступа к ресурсам Usenet. В данной схеме обращение к группе comp.infosystems.gopher для получения статьи 86 будет выглядеть так:
nntp:comp.infosystems.gopher/086
Следует обратить внимание на то, что адрес сервера Usenet не указан. Программа-клиент должна быть предварительно сконфигурирована на работу с одним из серверов Usenet. Сама служба Usenet является распределенным информационным ресурсом, и группа comp.infosystems.gopher на сервере в домене kiae.su или где-либо еще в мире содержит одни и те же сообщения.
Схема TELNET
. По этой схеме осуществляется доступ к ресурсу в режиме удаленного терминала. Обычно клиент вызывает дополнительную программу для работы по протоколу telnet. При использовании этой схемы необходимо указывать идентификатор пользователя, допускается использование пароля. Реально, доступ осуществляется к публичным ресурсам, и идентификатор и пароль являются общеизвестными, например, их можно узнать в базах данных Hytelnet.
telnet://guest:password@apollo.polyn.kiae.su
Схема WAIS
. WAIS - распределенная информационно-поисковая система. Она работает в двух режимах: поиска и просмотра. При поиске используется форма со знаком "?", отделяющим адресную часть от ключевых слов:
wais://wais.think.com/wais?guide
В данном случае обращаются к базе данных wais на сервере wais.think.com с запросом на поиск документов со словом guide. Сервер должен вернуть клиенту список документов. После получения этого списка можно использовать вторую форму схемы wais - запрос на просмотр документа:
wais://wais.think.com/wais/wtype/039=/kuku/kuku.txt
039 - это идентификатор документа. Следует заметить, что не все клиенты умеют работать с этой схемой, и в ряде случаев следует пользоваться другими средствами. Схема wais хороша там, где надо обслуживать постоянно действующий запрос, который неизменен на протяжении длительного времени, но при этом выдает свежие документы.
Система Доменных Имен
Числовая адресация удобна для машинной обработки таблиц маршрутов, но совершенно не приемлема для использования ее человеком. Запомнить наборы цифр гораздо труднее, чем мнемонические осмысленные имена. Для облегчения взаимодействия в Сети сначала стали использовать таблицы соответствия числовых адресов именам машин. Эти таблицы сохранились до сих пор и используются многими прикладными программами. Некоторое время даже существовало центральное хранилище соответствий, которое можно было по FTP скачать на свою машину из
Системы почтовой рассылки (программа sendmail)
Основным средством рассылки почты в Internet является программа sendmail. Она обеспечивает работу модульной системы рассылки, которая предназначена для получения и отправки корреспонденции, а также управления программами подготовки и просмотра почтовых сообщений. Sendmail позволяет организовать почтовую службу локальной сети и обмениваться почтой с другими серверами почтовых служб через специальные шлюзы. Send-mail может быть сконфигурирована для работы с различными почтовыми протоколами. Обычно это протоколы UUCP (Unix-Unix-CoPy) и SMTP (Simple Mail Transfer Protocol).
Sendmail работает в стиле "отделения связи" обычной почтовой службы, которое принимает и пересылает почтовые сообщения. Sendmail может интерпретировать два типа почтовых адресов:
почтовые адреса SMTP; почтовые адреса UUCP.
Первые являются стандартными адресами Internet и фактически являются стандартом де-факто. Именно этот адрес обычно указан на визитных карточках.
Sendmail можно настроить для поддержки:
списка адресов-синонимов; списка адресов рассылки пользователя; автоматической рассылки почты через шлюзы; поддержки очередей сообщений для повторной рассылки почты в случае отказов при рассылке; работы в качестве SMTP-сервера; доступа к адресам машин через сервер доменных имен BIND; для доступа к внешним серверам имен.
Slave
- заставляет сервер отправлять все запросы на серверы, которые определены командой forwarders.
Прежде, чем рассматривать примеры файлов named.boot для различных типов серверов, хотелось бы обратить внимание читателя на две последние команды.
Фактически, именно они и определяют какая из процедур разрешения запроса (рекурсивная или нерекурсивная) будут применяться на вашем сервере. Если в файле named.boot есть команда slave, то определена рекурсивная процедура разрешения запроса, т.к. в этом случае named будет отсылать все запросы на серверы указанные в команде forwarders и от них получать адреса или имена удаленных хостов. В этом случае серверы из forwarders будут опрашивать корневые и удаленные серверы доменов. Если эти серверы также содержат команду slave, то поиск адреса или имени будут осуществлять серверы, которые определены в их файлах named.boot как forwarders.
Когда такая конфигурация сервера полезна? На сколько мне известно, обычно так настраивают серверы поддоменов внутри одной организации. В качестве сервера, на который осуществляется пересылка всех запросов, используется сервер всего домена. При этом с корневыми серверами общается только этот сервер, серверы зон самостоятельно на корневые серверы запросов не отправляют. Если число машин за пределами данного домена, с которыми общаются пользователи данного домена, не очень велико, и все они компактно расположены в других доменах, то центральный сервер домена быстро заполнит свой кэш необходимой для разрешения запросов информацией. При этом такой кэш будет только один, а работать он будет с той же скоростью, как если бы каждый из серверов зон создавал его у себя.
С точки зрения самого домена в любом случае сервер зоны обращается к серверу домена за адресами из другой зоны, если только сервер другой зоны не указан в файлах базы данных named.
Приведем теперь пример файла named.boot, в котором проиллюстрируем использование указанных выше команд.
Страница базы данных World Wide Web
- это законченный информационный объект, который отображается пользователю при обращении к информационному ресурсу World Wide Web по универсальному идентификатору этого ресурса (URI, URL).
Страницей-формой
будем называть в данном контексте файл в формате HTML, который содержит в себе HTML-форму.
После обращения к странице-форме, как правило, следует вызов либо API-модуля, встроенного в сервер, либо CGI-программы. В свою очередь такое действие вызывает генерацию этим модулем или программой виртуальной страницы.
Su
из сервера имен нельзя, на основе доменных имен строятся адреса электронной почты и доступ ко многим другим информационным ресурсам Internet. Поэтому гораздо проще оказалось ввести новый домен к существующему, чем заменить его. Таким образом в Москве существуют организации с доменными именами, оканчивающимися на su (например, kiae.su) и оканчивающимися на ru (msk.ru).
Если быть более точным, то новых имен с расширением su в настоящее время ни один провайдер не выделяет. Более того идет планомерная замена имен. Выявляются зарубежные информационные источники, и их администрация оповещается о замене доменных имен, после соответствующего подтверждения происходит удаление имени с расширением su.
Вслед за доменами верхнего уровня следуют домены, определяющие либо регионы (msk), либо организации (kiae). В настоящее время практически любая организация может получить свой собственный домен второго уровня. Для этого только надо направить заявку провайдеру и получить уведомление о регистрации (см. раздел 3.1.3). Далее идут следующие уровни иерархии, которые могут быть закреплены либо за небольшими организациями, либо за подразделениями больших организаций.
Всю систему доменной адресации можно представить следующим образом (рисунок 3.2):

Рис. 3.2. Пример дерева доменной адресации
Наиболее популярной программой поддержки DNS является named, которая реализует Berkeley Internet Name Domain (BIND). Но эта программа не единственная. Так в системе Windows NT 4.0 есть свой сервер доменных имен, который поддерживает спецификацию BIND. Определена в документе RFC 1033-1035.
Сервер часто не доступен
HTML-редакторы
| Название | Адрес | Примечание |
| HotDog | http://www.sausage.com/ | Сервер часто не доступен Windows |
| HTMLed | http://www.ist.ca/htmled/ | Windows |
| HotMetal | http://www.sq.com/ | Windows |
| InContext Spider | http://www.incontext.ca/ | Windows |
| Phoenix | http://www.bsd.uchicago.edu/ftp/pub/phoenix/ | Unix |
| Symposia | http://www.grif.fr/ | Unix |
| TkWWW | http://www.w3.org/hypertext/WWW/TkWWW/Status.html | Unix |
Текст на языке HTML:
Текст следующий за словом "Italic" <I>отображается как курсив</I>.
Текст отображаемый программой интерпретации:
Текст следующий за словом "Italic" отображается как курсив.
В приведенном выше примере элемент текста, который должен быть выделен курсивом, заключен между тагом начала стиля "Italic" - <I> и тагом конца стиля - </I>. Общая схема построения элемента текста в формате HTML может быть записана в следующем виде:
"элемент" := <"имя элемента" "список атрибутов"> содержание элемента </"имя элемента">
Конструкция перед содержанием элемента называется тагом начала элемента, а конструкция, расположенная после содержания элемента, - тагом конца элемента.
Структура гипертекстовой сети задается гипертекстовыми ссылками. Гипертекстовая ссылка - это адрес другого HTML документа, который тематически, логически или каким-либо другим способом связан с документом, в котором ссылка определена.
Для записи гипертекстовых ссылок в системе WWW была разработана специальная форма, которая называется Universe Resource Locator. Типичным примером использования этой записи можно считать следующий пример:
Этот текст содержит <A HREF="http://polyn.net.kiae.su/altai/index.html"> гипертекстовую ссылку</A>.
В приведенном выше примере элемент "A", который в HTML называют якорем (anchor), использует атрибут "HREF", который обозначает гипертекстовую ссылку (HyperText REFerence), для записи этой ссылки в форме URL. Данная ссылка указывает на документ с именем "index.html" в директории "altai" на сервере "polyn.net.kiae.su", доступ к которому осуществляется по протоколу "http".
Гипертекстовые ссылки в HTML делятся на два класса: контекстные гипертекстовые ссылки и общие. Контекстные ссылки вмонтированы в тело документа, как это было продемонстрировано в предыдущем примере, в то время как общие ссылки связаны со всем документом в целом и могут быть использованы при просмотре любого фрагмента документа. Оба класса ссылок присутствуют в стандарте языка с самого его рождения, однако, первоначально наибольшей популярностью пользовались контекстные ссылки. Эта популярность привела к тому, что механизм использования общих ссылок практически полностью "атрофировался". Однако по мере стандартизации интерфейса пользователя и стилей представления информации разработчики языка снова вернулись к общим ссылкам и стремятся приспособить их к задачам управления этим интерфейсом.
Структура HTML-документа позволяет использовать вложенные друг в друга элементы. Собственно, сам документ - это один большой элемент с именем "HTML":
<HTML> <HEAD> <TITLE>JavaScript</TITLE> <SCRIPT LANGUAGE="JavaScript"> <!-- Hide script from user // * * * // * * Form runing string // * * * adv_string = "Internet\"" status_string = adv_string+adv_string+adv_string+adv_string+adv_string+adv_string // * * * // * * Background function definition // * * * i=0 function background() { // Select 50 symbols from status string target. window.status = status_string.substring(i,i+180) // After last character move to first position if(++i == 180) i=0 // The Clock is here current_date = new Date() window.document.form1.clock.value = current_date.getHours()+":"+current_date.getMinutes() +":"+current_date.getSeconds() // Set timeout between function execution id = setTimeout("background()",500) window.document.form1.kuku.value = "number" + i } // This is the end of code definition --> </SCRIPT> </HEAD> <BODY onLoad="background()" BACKGROUND=www_wal0.jpg> <H1>JavaScript</H1> <HR> JavaScript - текст о JavaScript.: <UL> <LI><A HREF="#m_clock">Часы</A> <LI><A HREF="#wind">Бегущая строка</A> </UL> <HR> <A NAME=m_clock> <FORM NAME=form1 ACTION="new_window()"> <INPUT NAME=clock TYPE=text SIZE=8 MAXLENGTH=8> <HR> <A NAME=wind> <INPUT TYPE=button NAME=help Value="HELP" onClick="window.open('clock.htm','Clock_Window',' scrollbars=yes,width=450,height=350')">. <HR> <INPUT NAME=kuku type=text> <HR> </FORM <P> </BODY> </HTML>
В данном случае описаны две программы: программа идущих часов и программа бегущей строки. Данный язык поддерживают не все программы просмотра.
Тело сообщения
. Первая пустая строка в файле почтового сообщения отделяет заголовок от тела сообщения. Все, что следует после этой строки, называется телом сообщения и передается по почте без изменений.
Sendmail может быть вызвана:
программой подготовки сообщений для отправки уже подготовленных сообщений; программой получения почты для пересылки полученной из сети почты; непосредственно пользователем для отправки по почте файла или короткого сообщения; почтовым демоном, которым обычно является сама sendmail.
После того, как почта собрана, начинается ее рассылка. При этом выполняются следующие действия:
адреса отправителя и получателя преобразуются в формат сети-получателя почты; если необходимо, то в заголовок сообщения добавляются строки, позволяющие получателю отвечать на принятое сообщение (например: FROM: <адрес>); почта передается одной из программ рассылки почты.
На рисунке 3.18 представлена схема функционирования почтового сервера на базе программы sendmail.
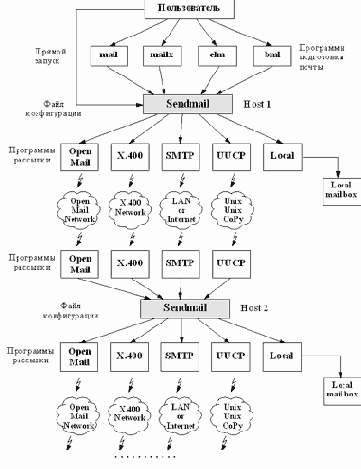
Рис. 3.18. Схема функционирования почтового сервера на базе программы Sendmail
Когда программа приема почты получает сообщение, то она передает его программе sendmail для последующей рассылки. Если сообщение достигло машины адресата, то оно отправляется программой местной рассылки в почтовый ящик пользователя.
Первый этап рассылки - сбор сообщений. Sendmail получает почтовые сообщения из трех источников:
командной строки или стандартного ввода; через SMTP-протокол (из сети); из очереди сообщений.
При получении сообщений из командной строки или стандартного ввода, sendmail вызывается пользователем с указанием адреса доставки сообщения. При этом выполняются следующие действия: определяется адрес отправителя, выбирается из командной строки адрес получателя и оба адреса преобразуются в соответствии с описанием файла конфигурации, определяется способ доставки сообщения, размещается заголовок в оперативной памяти для последующих преобразований, а тело сообщения размещается во временном файле для отправки без изменений.
При получении сообщений по протоколу SMTP, sendmail используется как программа клиента и сервера протокола. Протокол определен в RFC-821 и является основным для рассылки почты в Internet. В этом случае sendmail запускается как демон, который "слушает" порт TCP и в случае получения сообщения устанавливает соединение с удаленным клиентом SMTP. Как правило, таким клиентом является другая программа sendmail.
Программа подготовки почты на локальной машине также может использовать SMTP. Для этого sendmail открывает канал (pipe) межпроцессного обмена.
При получении сообщений из очереди используются временные файлы очередей. Эти очереди используются для хранения неразосланных сообщений. Сообщение хранится в двух файлах. В одном файле хранится тело сообщения, а в другом конверт и заголовок сообщения. Обычно sendmail опрашивает очереди через определенные администратором почтового сервера промежутки времени, на предмет наличия в них неразосланных сообщений.
Вторая стадия рассылки почты - рассылка сообщений.
Как только одним из описанных выше способов sendmail получила сообщение, делается попытка его отправить по адресу. Для этого sendmail определяет три параметра: программу рассылки, узел сети и получателя. Эта процедура производится по правилам, которые содержатся в файле конфигурации. Sendmail сохраняет одну копию тела сообщения во временном файле, а заголовок загружает в оперативную память. Для каждого сообщения программа доставки (рассылки) сообщений вызывается отдельно. Если сообщение должно быть доставлено на разные машины, то для каждой из машин также вызывается своя программа доставки. Некоторые программы могут обслуживать сразу несколько абонентов одной машины, если это невозможно, то для каждого абонента вызывается также своя программа доставки. Рассматривают два типа рассылки: на удаленную машину и местную рассылку.
Text
. Этот тип указывает на то, что в теле сообщения содержится текст. Основным подтипом типа "text" является "plain", что обозначает так называемый планарный текст. Понятие планарного текста появилось в связи с тем, что существует еще размеченный текст, т.е. текст со встроенными в него символами управления отображением, и гипертекст, т.е. текст, который можно просматривать не последовательно, а произвольно, следуя гипертекстовым ссылкам. Для обозначения размеченного текста используют подтип "richtext", а для обозначения гипертекста - подтип "html". Вообще говоря, "html" - это специальный вид размеченного текста, который используется для представления гипертекстовой информации в системе World Wide Web, которая получила в последнее время широкое распространение в Internet. Понятие размеченного текста требует более подробного обсуждения, так как его передача и интерпретация являются одной из причин появления стандарта MIME.
Тип "message"
предназначен для работы с обычными почтовыми сообщениями, которые однако не могут быть переданы по почте по разного рода причинам. Эти причины объясняются подтипами данного типа.
Типы информационно-поисковых языков
Главная задача информационно-поисковой системы - это поиск информации релевантной информационным потребностям пользователя. Слово релевантность означает соответствие между желаемой и действительно получаемой информацией. Релевантность можно еще представить как меру близости между реально полученными документами и тем, что следовало бы получить из системы. Естественно, что здесь возникает две задачи, которые следует решить: представление информации в системе и формулирование информационных потребностей пользователя. Эти две проблемы тесно связаны друг с другом. Руководства по многим информационно-поисковым системам Internet (Yahoo, OpenText и др.), что система реализует запрос типа "найди похожее". Но что значит эта фраза в реальности? Как вычислить эту самую похожесть?
Наиболее распространенными моделями представления документов в информационно-поисковой системе являются различные вариации на тему векторной модели, когда документ представляется как набор терминов. Как уже упоминалось ранее, это не весь текст документа, а только небольшой набор терминов, который отражает его содержание. Базируясь на таком представлении о документе и рассмотрим различные информационно-поисковые языки.
Типы информационных ресурсов
Информация в FTP-архивах разделена на три категории:
Защищенная информация, режим доступа к которой определяется ее владельцами и разрешается по специальному соглашению с потребителем. К этому виду ресурсов относятся коммерческие архивы (например, коммерческие версии программ в архивах ftp.microsoft.com или ftp.bsdi.com), закрытые национальные и международные некоммерческие ресурсы (например, работы по международным проектам CES или IAEA), частная некоммерческая информация со специальными режимами доступа (частные благотворительные фонды, например). Информационные ресурсы ограниченного использования, к которым относятся, например, программы класса shareware (Trumpet Winsock, Atis Mail, Netscape, и т.п.). В данный класс могут входить ресурсы ограниченного времени использования (текущая версия Netscape перестанет работать в июне если только кто-то не сломает защиту) или ограниченного времени действия, т.е. пользователь может использовать текущую версию на свой страх и риск, но никто не будет оказывать ему поддержку. Свободно распространяемые информационные ресурсы или freeware, если речь идет о программном обеспечении. К этим ресурсам относится все, что можно свободно получить по сети без специальной регистрации. Это может быть документация, программы или что-либо еще. Наиболее известными свободно распространяемыми программами являются программы проекта GNU Free Software Foundation. Следует отметить, что свободно распространяемое программное обеспечение не имеет сертификата качества, но как правило, его разработчики открыты для обмена опытом.
Из выше перечисленных ресурсов наиболее интересными, по понятным причинам, являются две последних категории, которые, как правило, оформлены в виде FTP-архивов.
Технология FTP была разработана в рамках проекта ARPA и предназначена для обмена большими объемами информации между машинами с различной архитектурой. Главным в проекте было обеспечение надежной передачи и поэтому с современной точки зрения FTP кажется перегруженным излишними редко используемыми возможностями. Стержень технологии составляет FTP-протокол.
Традиционные информационно-поисковые языки и их модификации
Наиболее распространенным ИПЯ является язык, позволяющий составить логические выражения из набора терминов. При этом используются булевые операторы AND, OR, NOT. Запрос при этом может выглядеть следующим образом: ((информационная and система ) or ИПС) not СУБД
В данном случае эта фраза означает: "Найди все документы, которые содержат одновременно слова "информационная" и "система", либо слово "ИПС", но не содержат слова "СУБД"".
Запрос можно рассматривать как и реальный документ из базы данных. В нашем случае, фактически, мы имеем дело с двумя запросами:
информационная and система not СУБД
и
ИПС not СУБД
каждый из которых подразумевает как бы два действия: сначала найти все документы, содержащие необходимые пользователю термины, а потом отсеять те, которые содержат термин "СУБД".
Такая схема достаточно проста, и поэтому наиболее широко применяется в современных информационно-поисковых системах. Но еще 20 лет тому назад были хорошо известны и ее недостатки.
Булевый поиск плохо масштабирует выдачу. Оператор AND может очень сильно сократить число документов, которые выдаются на запрос. При этом все будет очень сильно зависеть от того, насколько типичными для базы данных являются поисковые термины. Оператор OR напротив может привести к неоправданно широкому запросу, в котором полезная информация затеряется за информационным шумом. Для успешного применения этого ИПЯ следует хорошо знать лексику системы и ее тематическую направленность. Как правило, для системы с таким ИПЯ создаются специальные документально лексические базы данных со сложными словарями, которые называются тезаурусами и содержат информацию о связи терминов словаря друг с другом.
Модификацией булевого поиска является взвешенный булевый поиск. Идея такого поиска достаточно проста. Считается, что термин описывает содержание документа с какой-то точностью, и эту точность выражают в виде веса термина. При этом взвешивать можно как термины документа, так и термины запроса. Запрос может формулироваться на ИПЯ, описанном выше, но выдача документов при этом будет ранжироваться в зависимости от степени близости запроса и документа. При этом измерение близости строится таким образом, чтобы обычный булевый поиск был бы частным случаем взвешенного булевого поиска.
Ua, ru, la, li
, и т.п. Однако Internet не СССР, и просто так выбросить домен
Uk, jp, au, ch
, и т.п. Для СССР также был выделен домен su. После 1991 года, когда республики союза стали суверенными, многие из них получили свои собственные домены:
Universal Resource Identifier
Из всех спецификаций World Wide Web только спецификация URI доведена до состояния RFC. За этим стандартом закреплен номер 1630. Выпущен этот документ в 1994 году и отражает состояние информационных ресурсов Internet на это время.
URI определяет способ записи (кодирования) адресов различных информационных ресурсов при обращении к ним из страниц WWW. Однако в последнее время данная спецификация стала встречаться и в почтовых сообщениях. При этом видимо предполагается, что пользователи почты должны использовать клиентов, поддерживающих этот формат сообщения (HTML). Реально, речь может идти о клиентах MIME.
Необходимость в URI была понятна разработчикам WWW c момента зарождения системы, т.к. предполагалось объединение в единую информационную среду средств, использующих различные способы идентификации информационных ресурсов. Первоначально это были FTP-архивы, информационно-поисковая система Alise, и справочная система ЦЕРН. Однако Бернерс-Ли подошел к делу основательно и разработал спецификацию, которая включала в себя обращения к FTP, Gopher, WAIS, Usenet, E-mail, Prospero, Telnet, Whois, X.500 и, конечно, HTTP (WWW). В итоге была разработана универсальная спецификация, которая позволяет расширять список адресуемых ресурсов за счет появления новых схем.
Место применения URI - гипертекстовые ссылки, которые записываются в тагах <A HREF=URI> и <LINK HREF=URI>. Встраиваемые графические объекты также адресуются по спецификации URI в тагах <IMG SRC=URI> и <FIG SRC=URI>. Реализация URI для WWW называется URL (Uniform Resource Locator). Точнее, URL - это реализация схемы URI, отображенная на алгоритм доступа к ресурсам по сетевым протоколам. Существует еще и URN (Uniform Resource Name), которое отображает URI в пространство имен на сети. Появление URN связано с желанием адресовать части почтового сообщения MIME. Но здесь есть момент, который находится в стадии дебатов. Сообщение "живет" не более 5 дней. Если оно сохранено, то его можно превратить в другой информационный ресурс, например, WWW-страницу. Поэтому судьба URN еще не решена.
User interface
- интерфейс пользователя - это не просто программа просмотра. В случае информационно-поисковой системы под этим словосочетанием понимают и способ общения пользователя с поисковым аппаратом системы, т.е. с системой формирования запросов и просмотров результатов поиска. Просмотр результатов поиска и информационных ресурсов сети - это совершенно разные вещи, на которых остановимся чуть позже.
Виртуальной страницей Website
будем называть страницу, которая в виде файла в файловой системе сервера не существует. Данная страница появляется только в момент обращения клиента к серверу.
Один из способов генерации виртуальной страницы - это генерация при помощи API-модуля или CGI-программы. При этом весь текст страницы может порождаться программой, либо для генерации могут использоваться файлы-заготовки. Генерируют не только текстовые файлы, но и графику. Одним из наиболее популярных способов генерации документов является обращение к стекам гипертекстовых ссылок и системам управления универсальными базами данных(СУБД).
Второй способ генерации виртуальной страницы - это генерация такой страницы сервером. В данном случае в тело документа и файлы описания иерархии документов сервера включаются команды преобразования документов. Сервер может, в общем случае, производить условную генерацию документов на основе информации, полученной от программы-клиента.
Другим типом объекта, который хранится в Website, являются страницы в формате Virtual Reality Modeling Language(VRML). VRML-страница - это такой же объект, как и обычные страницы Website, только написанная на другом языке. К VRML-страница можно применять те же механизмы генерации, что и к страницам HTML.
Java-applet - это мобильный код, сгененрированный компилятором applet'ов. Applet'ы составляют в базе данных Website отдельную директорию в файловой системе сервера. В страницы HTML встраиваются специальные контейнеры applet'ов, которые позволяют программе-клиенту распознавать наличие applet'а и подгружать его в качестве части страницы.

Рис. 3.31. Структура базы данных и программного обеспечения Website
Как видно из рисунка 3.31, кроме перечисленных выше компонентов, базу данных Website составляют еще и другие файлы. Главным образом, это файлы графических и мультимедийных форматов. Для просмотра этих файлов программа-клиент должна уметь запускать либо внешнюю программу, либо plug-ins, т.е. программу, которая отображает файл графического или мультимедийного формата внутрь рабочей области программы-клиента.
Совершенно очевидно, что для создания всего этого многообразия файлов и компонентов Website необходимо программное обеспечение, которое не входит в стандартный набор, представленный на рисунке 3.31. Самый минимальный набор инструментов, который необходим для поддержания страниц базы данных можно определить следующим образом:
Редактор файлов формата HTML. Графический редактор, сохраняющий файлы в форматах GIF, в том числе и версии GIF89A, и JPEG. Редактор файлов формата MPEG. Редактор файлов VRML. Редактор аудиофайлов. Компилятор байткода Java. и др.
Кроме прочего, для того, чтобы тестировать страницы, необходимо иметь версии клиентского программного обеспечения различных производителей и различных версий. Определить какие именно программы и их версии необходимы, можно по файлу статистики сервера. Позже будет рассказано, как это сделать.
В рамках данного курса мы не будем останавливаться подробно на всех этих типах программных продуктов, так как это предмет отдельного курса, но об основных из них - редакторах HTML-документов и редакторах графических файлов, имеет смысл поговорить более детально.
Внутренние макроопределения sendmail
. В данном разделе присваиваются значения переменным, которые sendmail использует при взаимодействии с другими транспортными агентами.
Выбор и установка сервера протокола
Как уже было сказано выше, сервер World Wide Web - это программа, обслуживающая запросы клиентов по протоколу HTTP. Иногда серверами WWW называют и другие программы, например, поисковые машины Wide Area Information Server. Но это слишком вольное толкование понятия WWW сервера. Главной задачей сервера "паутины" является обеспечение доступа пользователей к базе данных HTML документов. Однако, в настоящее время функциональные возможности серверов значительно расширились и вышли за пределы простой отсылки документов на запросы клиентов. Наиболее типичными для современных серверов являются следующие функции:
ведение иерархической базы данных документов, контроль за доступом к информации со стороны программ-клиентов, предварительная обработка данных перед ответом на запрос, взаимодействие с внешними программами через Common Gateway Interface, реализация взаимодействия с клиентами и другими серверами в режиме посредника, реализация встроенных или взаимодействие с внешними поисковыми машинами.
Кроме того, такие серверы как NetSite (Netscape Communication) и Apachie реализуют шифрованные протоколы HTTP для обмена информацией с клиентами. Рассмотрение перечисленных свойств и функций WWW серверов полезно провести на примерах, основанных на практике эксплуатации серверов NCSA httpd, CERN httpd, Winhttpd и WN, Apachie.
WAIS
WAIS является одной из наиболее изощренных поисковых систем Internet. В отличии от многих поисковых машин, ИПЯ системы позволяет строить не только вложенные булевые запросы, считать формальную релевантность по различным мерам близости, взвешивать термины запроса и документа, но и осуществлять коррекцию запроса по релевантности. Система также позволяет использовать усечение терминов, разбиение документов на поля и ведение распределенных индексов. Не случайно именно эта система была выбрана в качестве основной поисковой машины для реализации энциклопедии "Британика" на Internet.
Www sites
- это весь Internet. А если говорить более точно, то это те информационные ресурсы, просмотр которых обеспечивается программами просмотра.
Рассмотрим теперь назначение и принцип построения каждой из этих компонент более подробно и определим в чем отличие данной системы от традиционной информационно-поисковой системы локального типа.
Yahoo
Данная система появилась в сети одной из первых, и поэтому говорить будем о сегодняшнем состоянии Yahoo, а не о состоянии годовой давности. В настоящее время Yahoo сотрудничает со многими производителями средств информационного поиска и на различных ее серверах используется различное программное обеспечение. На мой взгляд, это самая незатейливая информационная служба, которая сосредоточилась на информации о Web как таковой. ИПЯ Yahoo достаточно прост: все слова следует вводить через пробел и они соединяются либо AND, либо OR. При выдаче не выдается степени соответствия документа запросу, а только подчеркиваются слова из запроса, которые встретились в документе. При этом не производится нормализация лексики и не проводится анализ на "общие" слова. Хорошие результаты поиска получаются только тогда, когда пользователь знает, что информация в базе данных Yahoo точно есть. Ранжирование производится по числу терминов запроса в документе.
Yahoo относится к классу простых традиционных систем с ограниченными возможностями поиска.
- документ попал в список найденных и занял третье место (ошибка в запросе: вместо "on the" следовало указывать "of the"). Но здесь следует заметить, что основное место хранения этого документа база данных Yahoo, т.е. запрос точно совпадает с тематикой базы данных.
Следует заметить, что приведенный пример не стоит рассматривать как реальную оценку возможностей описанных выше систем. Это просто иллюстрация, которая поможет провести свой собственный выбор наиболее подходящего средства поиска.
В завершении хотелось бы обратить внимание читателей еще на один аспект выбора информационно-поисковой системы. Это профиль ее баз данных. Можно возразить, что все системы индексируют одно и тоже - массив документов Internet. Однако делают они это по-разному. Очень важен профиль системы, который задается разбиением документов по темам и словарем индексирования, а также способом его поддержания. Определенным ориентиром здесь могут служить виртуальные библиотеки. Но об этом в следующий раз.
Заголовок
. Заголовок состоит из стандартных текстовых строк, которые содержат адреса, информацию о рассылке и данные. Заголовок может быть частью подготовленного пользователем текстового файла, а может быть подготовлен и добавлен к телу сообщения программой подготовки почты. Данные из заголовка могут быть использованы для оформления конверта сообщения.