Berkeley Internet Name Domain
- это сервер доменных имен реализованный в университете Беркли, который широко применяется на Intenet'е. Он обеспечивает поиск доменных имен и IP-адресов для любого узла Сети. BIND обеспечивает рассылку сообщений электронной почты через узлы Internet. Если говорить более точно BIND обеспечивает поиск доменного адреса машины пользователя, которому адресована почта, и определение IP-адреса доменному адресу. Эта информация используется программой рассылки почтовых сообщений sendmail, которая выступает в качестве почтового сервера.
BIND реализован по схеме "клиент/сервер". Собственно BIND - это сервер, а функции клиента выполняет name resolver или просто resolver. Обычно, модули resolver'а находятся в библиотеке libc.a, если речь идет о системе UNIX, и редактируются вместе с программой, использующей вызовы gethostbyname и gethostbyaddr. Как уже отмечалось, базовым понятием для BIND является "домен". На рисунке 3.3 представлена схема описания системы доменов.

Рис. 3.3. Схема доменной адресации
На рисунке домены изображены в виде кругов. Каждый круг соответствует множеству компьютеров, которые образуют домен. Вложенные круги - это поддомены, которые, в свою очередь тоже могут быть разбиты на поддомены и т.д. При отображении этой структуры в доменные имена получается иерархия имен узлов сети.
Однако разговоры об архитектуре сервиса доменных имен и различных его реализаций совершенно беспочвенны, если только не иметь своего собственного домена. Ведь проблемы с администрированием возникают только в этом случае. В следующем разделе рассказано о том, как его получить.
Cache
- определяет имя кэш-файла. Обычно в кэш-файле описаны адреса и имена корневых серверов, которые данный сервер будет использовать для получения адресов удаленных серверов доменных имен.
Caсhe server
- это сервер, который запоминает в своем буфере (caсhe) соответствия между именами и IP-адресами и хранит их некоторое время. Если пользователь достаточно часто обращается к каким-либо ресурсам сети, то в случае использования caсhe-сервера он всегда будет быстро получать IP-адрес или доменное имя, т.к. его прикладное программное обеспечение будет пользоваться услугами caсhe-сервера. При этом обращение к местному серверу зоны, корневому серверу и удаленным серверам зон будут осуществляться только один раз - в момент первого обращения к ресурсу.
Для организации зоны (домена) необходимо иметь primary server и, как минимум один secondary server. Если с primary server все более или менее понятно - он создается на компьютере, который входит в описываемый домен и управляется администратором домена, то размещение secondary server всегда вызывает определенные трудности. Как уже говорилось выше, его можно создать на другом компьютере домена и тем самым формально выполнить условия по организации двух серверов доменных имен для одной зоны . Но в этом решении есть два нюанса. Во-первых, организация второго сервера доменных имен заставляет устанавливать либо еще одну Unix-машину, либо Windows NT, в которых есть поддержка BIND. Во-вторых, с точки зрения надежности secondary server лучше всего размещать у провайдера, т.к. обычно именно он делегирует зону из своего домена, и через его сервер доменных имен по рекурсивной или нерекурсивной процедуре разрешения имени весь остальной мир получает доступ к машинам вашего домена.
Если же домен распределен по нескольким сетям или подсетям, которые к тому же и территориально расположены в разных зданиях или различных частях города, или даже в разных городах, то тогда для каждой из этих частей домена следует организовать secondary server, что не отменяет размещения secondary server у провайдеров, поддерживающих такую распределенную систему.
В любом случае secondary server всегда не один, но каждый администратор должен сам решать сколько их надо заводить. Кроме этого если сервер заводится у коммерческого провайдера, то за него придется платить.
О второй Unix-машине или Windows NT было упомянуто из тех соображений, что многие маленькие локальные сети строятся по схеме, в которой многозадачная и многопользовательская операционная система ставится только на машине-шлюзе, через которую локальная сеть подключается к сети провайдера. На всех остальных машинах устанавливается либо Windows 95, либо MS-DOS, одним словом персональная операционная система.
Совершенно очевидно, что выделять еще одну машину для общественных нужд не очень хочется, а свою собственную зону иметь желательно. Поэтому, либо обращаются к провайдеру с запросом на размещение secondary server, либо договариваются с кем-то еще.
Любой сервер является кэширующим сервером. И primary, и secondary серверы запоминают на некоторое время, в своем буфере (cache) соответствие между именами и IP-адресами любой зоны, если к ней хоть раз обращались, и была выполнена процедура разрешения адреса. Это позволяет сократить обмен запросами между серверами и обеспечить более быстрое разрешение адреса для часто используемых ресурсов.
Организация на базе named только кэширующего сервера основано на том предположении, что primary и secondary серверы зоны могут быть перегружены запросами (типичный случай для большой организации). В этих условиях время на разрешение имени может быть довольно значительным. Кэширующий сервер на вашей вычислительной установке позволит несколько сократить это время если вы постоянно обращаетесь к одним и тем же хостам. Ждать придется только при первом обращении, когда будет выполняться стандартная процедура разрешения адреса, все последующие обращения будут удовлетворяться вашим кэширующим сервером.
Если число зон, к которым вы обращаетесь не очень велико, то для них на вашей вычислительной установке имеет смысл сделать secondary server для этих зон (если конечно позволяют ресурсы вашего компьютера). При этом ни у кого регистрировать ваш secondary server не надо. В этом случае для указанных зон вы просто создаете долговременный кэш, который обслуживает только вашу зону.
От общего описания типов серверов, которые можно организовать при помощи программы named прейдем к файлам ее настройки.
Client
- это программа просмотра конкретного информационного ресурса. В настоящее время наиболее популярны мультипротокольные программы типа Netscape Navigator. Такая программа обеспечивает просмотр документов World Wide Web, Gopher, Wais, FTP-архивов, почтовых списков рассылки и групп новостей Usenet. В свою очередь все эти информационные ресурсы являются объектом поиска информационно-поисковой системы.
Common Gateway Interface - средство расширения возможностей технологии World Wide Web
Спецификация CGI была разработана в Центре Суперкомпьютерных Приложений Унив-ерситета штата Иллинойс (NCSA). Работы над ней велись параллельно с Mosaic. С точки зрения общей архитектуры программного обеспечения World Wide Web, CGI определила все дальнейшее развитие системных средств. До появления этой спецификации все новые возможности реализовывались в виде модулей, включенных в библиотеку общих кодов ЦЕРН. Разработчики серверов должны были использовать эти коды для реализации программ или заменять их своими собственными аналогами. Это означало, что после компиляции сервера добавить в него новые возможности будет невозможно. CGI в корне изменила эту практику.
Главное назначение Common Gateway Interface - обеспечение единообразного потока данных между сервером и прикладной программой, которая запускается из-под сервера. CGI определяет протокол обмена данными между сервером и программой. Для тех, кто знаком с протоколом HTTP, может показаться, что CGI - это просто подмножество этого протокола. Однако это не так. Во-первых, CGI определяет порядок взаимодействия сервера с прикладной программой, в котором сервер выступает инициирующей стороной, во-вторых, CGI определяет механизм реального обмена данными и управляющими командами в этом взаимодействии, что не определено в HTTP. Естественно, что такие понятия, как метод доступа, переменные заголовка, MIME, типы данных, заимствованы из HTTP и делают спецификацию прозрачной для тех, кто знаком с самим протоколом.
При описании различных программ, которые вызываются сервером HTTP и реализованы в стандарте CGI, используют следующую терминологию:
CGI-скрипт - программа, написанная в соответствии со спецификацией Common Gateway Interface. CGI-скрипты могут быть написаны на любом языке программирования (C, C++, PASCAL, FORTRAN и т.п.) или командном языке (shell, cshell, командный язык MS-DOS, Perl и т.п.). Скрипт может быть написан даже на языке редактора EMAC в системах Unix.
Шлюз - это CGI-скрипт, который используется для обмена данными с другими информационными ресурсами Internet или приложениями-демонами. Обычная CGI-программа запускается сервером HTTP для выполнения некоторой работы, возвращает результаты серверу и завершает свое выполнение. Шлюз выполняется точно также, только, фактически, он инициирует взаимодействие в качестве клиента с третьей программой. Если эта третья программа является сервисом Internet, например, сервер Gopher, то шлюз становится клиентом Gopher, который посылает запрос по порту Gopher, а после получения ответа пересылает его серверу HTTP.
Аналогично происходит взаимодействие с серверами распределенных баз данных, например, Oracle.
Directory
- адрес директории в файловой системе компьютера, на котором запускается named.
Дисциплины работы и команды протокола
. Обмен сообщениями и инструкциями в SMTP ведется в ASCII-кодах. В протоколе определено несколько видов взаимодействия между отправителем почтового сообщения и его получателем, которые здесь называются дисциплинами.
Наиболее распространенной дисциплиной является отправление почтового сообщения, которое начинается по команде MAIL, идентифицирующей отправителя:
MAIL FROM: paul@quest.polyn.kiae.su
Следующей командой определяется адрес получателя:
RCPT TO: paul@apollo.polyn.kiae.su
После того, как определены отправитель и получатель, можно отправлять сообщение:
DATA
DNS и безопасность
В сентябре 1996 года многие компьютерные издания Москвы опубликовали материал, в котором рассматривался случай подмены доменных адресов World Wide Web сервера агенства InfoART, что привело к тому, что подписчики этого сервиса в течении некоторого времени вместо страниц этого агенста просматривали картинки "для взрослых".
Администрирование DNS осуществляла компания Demos, поэтому пресс-конферению по поводу этого случая Demos и InfoArt проводили совместно. Разъяснения провайдера главным образом свелись к тому, что в базе данных DNS самого Demos никаких изменений не проводилось, а за состояние баз данных secondary серверов Demos ответственности не несет. Почему такое заявление вполне оправдывает провайдера?
Как было указано раньше, обслуживание запросов на получение IP-адресов по доменным именам, а именно об этом идет речь в случае InfoArt, осуществляется не одним сервером доменных имен, а множеством серверов. Все secondary серверы копируют базу данных с primary сервера, но делают они это с достаточно большими интервалами, иногда не чаще одного раза в двое суток. Запрос разрешает тот сервер, который быстрее откликается на запрос клиента. Таким образом, если подправить информацию на secondary сервере о базе данных primary сервера, то можно действительно на время между копированиями описания зоны заставить пользователей смотреть совсем не то, что нужно. Таким образом, практически все провайдеры попадают в категорию неблагонадежных. Но провайдеры также могут оказаться не при чем. В принципе, любой администратор может запустить у себя на машине named и скопировать зону с primary сервера, не регистрируя ее в центре управления сетью. Это обычная практика, т.к. разрешение имен - главный тормоз при доступе к удаленной машине, и часто по timeout прерывается работа с ресурсом из-за невозможности быстрого разрешения имени. Таким образом, все администраторы сети попадают в потенциальных злоумышленников. Но на самом деле существуют еще и другие способы. Например, кэш re-solver или сервера имен. Если время хранения записи в кэше большое, то сервер или resolver не будут обращаться к удаленному серверу вообще, а будут брать записи из кэша. Вмешаться в структуру данных кэша также возможно, а это значит, что можно и увеличить время хранения записи. Если организация- подписчик пользуется для доступа в сеть proxy-сервером, а это также обычная практика, то достаточно поправить кэш этого proxy и все пользователи этой организации будут ходить туда, куда их направит поправленная запись.
Существует несколько способов ограничения этого произвола. Первый из них - это точное знание IP-адресов ресурсов. В этом случае можно проверить состояние ресурса и выявить причину ошибки. Второй сопособ, запретить копировать описание зоны кому не поподя. Современные программы named позволяют описывать IP-адреса сетей, из которых можно копировать зоны. Правда такая политика должна быть согласована с другими владельцами зоны, в противном случае зону скопируют с secondary сервера. И наиболее мягкое средство - уменьшение времени хранения записей в кэше.
Для защиты можно использовать и фильтрацию пакетов. Зоны раздаются только по 53 порту TCP, в отличии от простых запросов. Если определить правила работы по этому порту, используя межсетевой фильтр, то можно и ограничить произвол при копировании информации с сервера доменных имен. Вообще, не стоит относиться к сервиру доменных имен легкомысленно. Следует учитывать тот факт, что используя этот сервис, можно выявить структуру вашей локальной сети.
Доставка местной почты
. Если sendmail определяет, что адреса доставки местные, то происходит обращение к файлу адресных синонимов и производится преобразование адресов (расширение). Файл адресных синонимов можно использовать для перенаправления почты в файлы или для обработки местными программами. Пользователь может иметь и свой собственный файл адресных синонимов для управления рассылкой персональной почты. После преобразования адресов почта отправляется программе местной рассылки (например rmail).
Важным моментом при работе sendmail является алгоритм определения типа адресов. При использовании стандартного файла конфигурации применяются следующие правила: почта рассылается в соответствии с форматом адреса получателя, адреса при этом бывают местные, UUCP и SMTP.
Местные адреса имеют вид:
user user@localhost user@localhost.localdomain user@alias user@alias.localdomain user@[local.host.internet.address] localhost!user localhost!localhost!user user@localhost.uucp
Местный адрес - это адрес, который распознается как адрес на машине, с которой осуществляется отправка почты.
Адреса UUCP имеют вид:
host!user host!host!user user@host.uucp
Если машина, с которой отправляется почта, имеет прямую линию связи по протоколу UUCP со следующей машиной (в адресе), то почта передается на эту машину, если такого соединения нет, то почта не рассылается и выдается сообщение об ошибке. Файл конфигурации должен содержать детальное описание маршрутов для пересылки сообщений на машины по протоколу UUCP.
Адреса SMTP - это адреса, описанные в стандарте RFC-822 или стандартные адреса Internet. Эти адреса имеют вид:
usr@host usr@host.domain <@host1,@host2,@host3:user@host4> user@[remote.host`s.internet.address]
Почта с адресами SMTP рассылается по протоколу SMTP.
Если в системе для адресации используется BIND-сервер, то sendmail может определять адреса получателей, используя сервис BIND. Если BIND не используется, то sendmail сама определяет адреса.
При рассылке почты можно использовать и смешанную адресацию:
user%hostA@hostB - почта отправляется с машины hostB на машину hostA user!hostA@hostB - почта отправляется с машины hostB на машину hostA hostA!user%hostB - почта отправляется с hostA на hostB
Подводя итог под обсуждением принципов работы sendmail следует специально подчеркнуть тот факт, что почта реально рассылается двумя принципиально разными способами. При использовании протокола UUCP почта рассылается по принципу "stop-go", т.е. сообщения передаются от машины к машине по указанному в адресе пути. Следует ясно представлять, если почта ушла с машины отправителя, то это не означает, что она поступит получателю. Промежуточная машина может вернуть почту назад, если не сможет разослать. Электронная почта действительно работает как система обычной почты, физически перемещая и храня сообщения на промежуточных почтовых станциях. При работе по протоколу SMTP почта реально отправляется только тогда, когда установлено интерактивное соединение с программой-сервером на машине-получателе почты. При этом происходит обмен командами между клиентом и сервером протокола SMTP в режиме on-line. При смешанной адресации доставка почты происходит по смешанному сценарию. Как шла доставка и как маршрутизировалось сообщение можно определить из заголовка сообщения, которое вы получили.
Доступ к базе данных под управлением Ingres
. Система управления базами данных Ingres является одной из популярных CУБД, работающих в среде операционной системы UNIX. Использование технологии разработки CGI-скриптов помогает построить современный дружественный интерфейс для пользователей WWW к базам данных под управлением данной СУБД. Начнем обсуждение этой возможности с простейших способов обращения с СУБД.
#!/bin/sh echo Content-type: text/plain echo ingres polyn < query #The end of script
В данном случае запрос заранее подготовлен в виде файла query. Скрипт не получает данных из интерфейсной программы, и действует по жесткой схеме запроса. Аналогично можно вызвать скрипт, выполняющий утилиты Ingres:
#!/bin/sh echo Content-type: text/plain echo helpr polyn #The end of script
В данном случае скрипт возвращает справку по базе данных polyn.
Естественно, что можно использовать не только тип text/plain, но и text/html. Пример такого использования приведен ниже:
#!/bin/sh echo Content-type: text/html echo echo '< PRE> ' helpr polyn situat echo '< /PRE> ' #The end of script
Выполнение жестких запросов не очень интересно для пользователя. Он обычно жаждет сформулировать свой собственный запрос. В следующем примере скрипту передается запрос методом доступа GET, который помещен в переменную окружения QUERY_STRING:
#!/bin/sh echo Content-type: text/html echo echo '< PRE> ' echo $QUERY_STRING | tr "+" " " | ingres polyn echo '< /PRE> ' #The end of script
Прежде всего данные посылаются на предобработку, т.к. все пробелы в запросе заменяются на знак "+" в соответствии с правилами HTTP. После этого фильтра данные поступают на стандартный ввод интерпретатора Ingres и результат работы возвращается пользователю.
Вообще говоря необходима фильтрация и на выходе после Ingres, т.к. вывод содержит неотображаемые символы, например символ '/007', который лучше заменить на что-нибудь отображаемое.
Отчеты могут быть достаточно большими, поэтому имеет смысл ограничить отчет определенным числом строк:
Доверенные пользователи
. В данной секции описываются пользователи, которым разрешено переписывать адреса отправителей, т.е. выступать не под тем адресом, который за ними закреплен.
Формат почтового сообщения (RFC-822)
При обсуждении примеров отправки и получения почтовых сообщений уже упоминался формат почтового сообщения. Разберем его подробнее. Формат почтового сообщения Internet определен в документе RFC-822 (Standard for ARPA Internet Text Message). Это довольно большой документ объемом в 47 страниц машинописного текста, поэтому рассмотрим формат сообщения на примерах. Почтовое сообщение состоит из трех частей: конверта, заголовка и тела сообщения. Пользователь видит только заголовок и тело сообщения. Конверт используется только программами доставки. Заголовок всегда находится перед телом сообщения и отделен от него пустой строкой. RFC-822 регламентирует содержание заголовка сообщения. Заголовок состоит из полей. Поля состоят из имени поля и содержания поля. Имя поля отделено от содержания символом ":". Минимально необходимыми являются поля Date, From, cc или To, например:
Date: 26 Aug 76 1429 EDT From: Jones@Registry.org cc: или Date: 26 Aug 76 1429 EDT From: Jones@Registry.org To: Smith@Registry.org
Поле Date определяет дату отправки сообщения, поле From - отправителя, а поля сс и To - получателя(ей). Чаще заголовок содержит дополнительные поля:
Date: 26 Aug 76 1429 EDT From: George Jones<Jones@Registry.org> Sender: Secy@SHOST To: Smith@Registry.org Message-ID: <4231.629.XYzi-What@Registry.org>
В данном случае поле Sender указывает, что George Jones не является автором сообщения. Он только переслал сообщение, которое получил из Secy@SHOST. Поле Message-ID содержит уникальный идентификатор сообщения и используется программами доставки почты. Следующее сообщение демонстрирует все возможные поля заголовка:
Date: 27 Aug 76 0932 From: Ken Davis <Kdavis@This-Host.This.net> Subject: Re: The Syntax in the RFC Sender: KSecy@Other-host Reply-To: Sam.Irving@Reg.Organization To: George Jones <Jones@Registry.org> cc: Important folks: Tom Softwood <Balsa@Tree.Root>, "Sam Irving"@Other-Host;, Standard Distribution: /main/davis/people/standard@Other-Host Comment: Sam is away on bisiness. In-Reply-To: <some.string@DBM.Group>, George`s message X-Special-action: This is a sample of user-defined field- names. Message-ID: <4331.629.XYzi-What@Other-Host
Поле Subject определяет тему сообщения, Reply-To - пользователя, которому отвечают, Comment - комментарий, In-Reply-To - показывает, что сообщение относится к типу "В ответ на Ваше сообщение, отвечающее на сообщение, отвечающее ...", X-Special-action - поле, определенное пользователем, которое не определено в стандарте.
Следует сказать, что формат сообщения постоянно дополняется и совершенствуется. Так в RFC-1327 введены дополнительные поля для совместимости с почтой X.400. Кроме этого, следует обратить внимание на поля некоторых довольно часто встречающихся заголовков, которые не регламентированы в RFC-822. Так первое предложение заголовка, которое начинается со слова From, содержит UUCP-путь сообщения, по которому можно определить, через какие машины сообщение "пробиралось". Поле Received: содержит транзитные адреса почтовых серверов с датой и временем прохождения сообщения. Вся эта информация полезна при разборе трудностей с доставкой почты.
В заключении хотелось бы отметить, что возможности почты не ограничиваются только пересылкой корреспонденции. По почте можно получить доступ ко многим ресурсам Internet, которые имеют почтовых роботов, отвечающих на запросы страждущих. Поэтому имеет смысл более детально изучить программное обеспечение, поддерживающее e-mail. Время, затраченное на чтение документации и опыты, окупятся возможностью получения информации из информационных архивов сети.
Формат представления почтовых сообщений MIME и его влияние на информационные технологии Internet
Стандарт MIME (или в нотации Internet, RFC-1341) предназначен для описания тела почтового сообщения Internet. Предшественником MIME является Стандарт почтового сообщения ARPA (RFC-822). Стандарт RFC-822 был разработан для обмена текстовыми сообщениями. С момента опубликования стандарта возможности аппаратных средств и телекоммуникаций ушли далеко вперед и стало ясно, что многие типы информации, которые широко используются в сети, невозможно передать по почте без специальных преобразований. Так в тело сообщения нельзя включить графику, аудио, видео и другие типы информации. RFC-822 не дает возможностей для передачи даже текстовой информации, которую нельзя реализовать 7-битовой кодировкой ASCII. Естественно, что при использовании RFC-822 не может быть и речи о передаче размеченного текста для отображения его различными стилями. Ограничения RFC-822 становятся еще более очевидными, когда речь заходит об обмене сообщениями в разных почтовых системах. Например, для приема/передачи сообщений из/в X.400 (новый стандарт ISO), который позволяет иметь двоичные данные в теле сообщения, ограничения старого стандарта могут стать фатальными, так как не спасает старый испытанный способ кодировки информации процедурой uuencode, так как эти данные могут быть по различному проинтерпретированы в X.400 и в программе рассылки почты в Internet (mail-agent).
В некотором смысле стандарт MIME ортогонален стандарту RFC-822. Если последний подробно описывает в заголовке почтового сообщения текстовое тело письма и механизм его рассылки, то MIME, главным образом, ориентирован на описание в заголовке письма структуры тела почтового сообщения и возможности составления письма из информационных единиц различных типов.
В стандарте зарезервировано несколько способов представления разнородной информации. Для этого используются специальные поля заголовка почтового сообщения:
поле версии MIME, которое используется для идентификации сообщения, подготовленного в новом стандарте; поле описания типа информации в теле сообщения, которое позволяет обеспечить правильную интерпретацию данных; поле типа кодировки информации в теле сообщения, указывающее на тип процедуры декодирования; два дополнительных поля, зарезервированных для более детального описания тела сообщения.
Стандарт MIME разработан как расширяемая спецификация, в которой подразумевается, что число типов данных будет расти по мере развития форм представления данных. При этом следует учитывать, что анархия типов (безграничное их увеличение) тоже не допустима. Каждый новый тип в обязательном порядке должен быть зарегистрирован в IANA (Internet Assigned Numbers Authority). Остановимся подробнее на форме и назначении полей, определяемых стандартом.
Формат стандартного ввода
. Стандартный ввод используется при передаче данных в скрипт по методу POST. Объем передаваемых данных задается переменной окружения CONTENT_LENGTH, а тип данных - переменной CONTENT_TYPE. Если из HTML-формы надо передать запрос типа: a=b&b=c, то CONTENT_LENGTH=7, CONTENT_TYPE=application/x-www-form-urlencoded, а первым символом в стандартном вводе будет символ "а". Следует всегда помнить, что конец файла сервером в скрипт не передается, а поэтому завершать чтение следует по числу прочитанных символов. Позже мы разберем примеры скриптов и обсудим особенности их реализации в разных операционных системах.
Формат стандартного вывода
. Стандартный вывод используется скриптом для возврата данных серверу. При этом вывод состоит из заголовка и собственно данных. Результат работы скрипта может передаваться клиенту без каких-либо преобразований со стороны сервера, если скрипт обеспечивает построение полного HTTP-заголовка, в противном случае сервер заголовок модифицирует в соответствии со спецификацией HTTP. Заголовок сообщения должен отделяться от тела сообщения пустой строкой. Обычно в скриптах указывают только три поля HTTP-заголовка:
Content-type, Location, Status.
Content-type указывается в том случае, когда скрипт сам генерирует документ "на лету" и возвращает его клиенту. В этом случае реального документа в файловой системе сервера не остается. При использовании такого сорта скриптов следует учитывать, что не все серверы и клиенты отрабатывают так, как представляется разработчику скрипта. Так, при указании Content-type: text/html, некоторые клиенты не реализуют сканирования полученного текста на предмет наличия в нем встроенной графики. Обычно в Content-type указывают текстовые типы text/plain и text/html.
Location используется для переадресации. Иногда переадресация помогает преодолеть ограничения сервера или клиента на обработку встроенной графики или серверной предобработки. В этом случае скрипт создает файл на диске и указывает его адрес в Location. Сервер, таким образом, передает реально существующий файл. В последнее время серверы стали буферизовать возвращаемые клиентам данные, что приводит к решению вопросов, связанных с повторным запуском скриптов для встраивания графики и разгрузки компьютера с сервером HTTP.
Forwarders
- данная команда определяет адреса серверов доменных имен куда следует отправлять не разрешенные запросы.
Админисрирование сети и сервисов INTERNET
- метод, позволяющий получить данные, заданные в форме URI в запросе ресурса. Если ссылаются на программу, то возвращается результат выполнения этой программы, но не текст программы. Дополнительные данные, которые надо передать для обработки, кодируются в запрос ресурса. Имеется разновидность метода GET - условный GET. При использовании этого метода сервер ответит на запрос только в том случае, если будут выполнены условия передачи. Это позволяет разгрузить сеть, избавив ее от передачи ненужной информации. Условие указывается в поле "if-Modified-Since" заголовка запроса. При использовании метода GET в поле тела ресурса возвращается собственно затребованная информация (текст HTML-документа, например).
HEAD
- метод, аналогичный GET, но не возвращает тела ресурса. Используется для получения информации о ресурсе. Условного HEAD не существует. Данный метод используется для тестирования гипертекстовых ссылок.
Hosts
. Если речь идет о системе типа Unix, то этот файл расположен в директории /etc и имеет следующий вид:
| IP-адрес | имя машины | синонимы |
| 127.0.0.1 | localhost | localhost |
| 144.206.160.32 | Polyn | polyn |
| 144.206.160.40 | Apollo | www |
Рис. 3.1. Пример таблицы имен хостов (файл /etc/hosts)
Конечно, в машине этот файл записывается не в виде таблицы, а следующим образом:
Index database
- индекс - это основной массив данных информационно-поисковой системы. Он служит для поиска адреса информационного ресурса. Архитектура индекса устроена таким образом, чтобы поиск происходил максимально быстро и при этом можно было бы оценить ценность каждого из найденных информационных ресурсов сети.
индексировщик служит для сканирования Internet
- робот- индексировщик служит для сканирования Internet и поддержки базы данных индекса в актуальном состоянии. Эта программа является основным источником информации о состоянии информационных ресурсов сети.
Информационно-поисковые языки Internet
При описании и классификации информационно-поисковых систем ставилась задача проанализировать наиболее популярные и наиболее типичные системы, которыми пользуются в Сети.
Информационно-поисковые системы Internet
Такие имена информационных служб как Lycos, AltaVista, Yahoo, OpenText, InfoSeek и ряд других, хорошо известны пользователям Internet. Без пользования услугами этих систем практически нельзя найти что-либо полезное в море информационных ресурсов Сети. Но что они из себя представляют, как устроены, почему результат поиска в терабайтах информации выдается так быстро, как устроено ранжирование документов при выдаче, что из себя представляют информационные массивы этих систем - этим вопросам посвящен этот раздел.
Информационно-поисковый язык системы
Однако, индекс - это только часть поискового аппарата, причем не видная глазу пользователя. Второй частью этого аппарата является информационно-поисковый язык. ИПЯ позволяет сформулировать запрос к системе в довольно простой и доходчивой форме. Уже давно осталась позади романтика создания ИПЯ, как естественного языка. Именно этот подход использовался в системе Wais на первых стадиях ее реализации. Если даже пользователю предлагается вводить запросы на естественном языке, то это не значит, что система будет осуществлять семантический разбор запроса пользователя. Проза жизни заключается в том, что обычно фраза разбивается на слова, из этого списка удаляются запрещенные и общие слова, иногда производится нормализация лексики, а затем все слова связываются либо логическим AND, либо OR. Таким образом запрос типа:
>Software that is used on Unix Platform
будет преобразован в: >Unix AND Platform AND Software
что будет означать примерно следующее: "Найди все документы, в которых слова Unix, Platform и Software встречаются одновременно".
Возможны и варианты. Так в большинстве систем фраза "Unix Platform" будет опознана как ключевая фраза, и не будет разделяться на отдельные слова. Вообще говоря, и все три слова могут быть опознаны как одна ключевая фраза. Другой подход заключается в вычислении близости между запросом и документом. Именно этот подход используется в Lycos, например. В этом случае, в соответствии с векторной моделью представления документов и запросов вычисляется мера близости. К настоящему времени известно около дюжины различных мер близости. Наиболее часто применяется cos угла между поисковым образом документа и запросом пользователя. Именно эти проценты соответствия документа запросу и выдаются в качестве справочной информации при списке найденных документов.
Наиболее продвинутым языком запросов из современных информационно-поисковых систем Internet обладает AltaVista[4]. Кроме обычного набора AND, OR, NOT, эта система позволяет использовать еще и NEAR. Последний оператор позволяет организовать контекстный поиск. Все документы в системе разбиты на поля, поэтому в запросе можно указать в какой части документа пользователь хочет увидеть ключевое слово (в ссылке, заголовке и т.п.). Можно также задать поле ранжирования выдачи и критерий близости документов запросу.
Информационные ресурсы и их представление в информационно-поисковой системе
Как видно из схемы (рисунок 3.41) документальным массивом ИПС Internet является все множество документов шести основных типов: WWW-страницы, Gopher-файлы, документы Wais, записи архивов FTP, новости Usenet, статьи почтовых списков рассылки. Все это довольно разнородная информация, которая представлена в виде различных, никак несогласованных друг с другом форматов данных. Здесь есть и текстовая информация, и графическая информация, и аудио информация и вообще все, что есть в указанных выше хранилищах. Естественно встает вопрос, как информационно-поисковая система должна со всем этим работать. В традиционных системах есть понятие поискового образа документа - ПОД'а. ПОД (Поисковый Образ Документа) - это нечто, что заменяет собой документ и используется при поиске вместо реального документа. Поисковый образ является результатом применения некоторой модели информационного массива документов к реальному массиву. Наиболее популярной моделью является векторная модель[7], в которой каждому документу приписывается список терминов, наиболее адекватно отражающих его смысл. Если быть более точным, то документу приписывается вектор, размерность которого равна числу терминов, которыми можно воспользоваться при поиске. При булевой векторной модели элемент вектора равен 1 или 0, в зависимости от наличия термина в ПОД'е документа или его отсутствия. В более сложных моделях термины взвешиваются, т.е. элемент вектора равен не 1 или 0, а некоторому числу, которое отражает соответствие данного термина документу. Именно последняя модель наиболее популярна в информационно-поисковых системах Internet[4,6,7]. Вообще говоря, существуют и другие модели описания документов: вероятностная модель информационных потоков и поиска, и модель поиска в нечетких множествах[7]. Анализ преимуществ и недостатков применения этих моделей при реализации информационно-поисковых систем в Internet - это тема специального исследования. Здесь имеет смысл обратить внимание читателя только на то, что пока именно линейная модель применяется в системах Lycos, WebCrawler, AltaVista, OpenText, AliWeb и ряде других. Исследования по применению других моделей также ведутся, например, в рамках проекта AltaVista[4] или научными группами[6]. Таким образом, первая задача, которою должна решить информационно-поисковая система - это приписывание списка ключевых слов документу или информационному ресурсу. Именно эта процедура и называется индексированием. Часто, однако, индексированием называют составление файла инвертированного списка, в котором каждому термину индексирования ставится в соответствие список документов, в которых он встречается. Такая процедура является только частным случаем, а точнее техническим аспектом создания поискового аппарата информационно-поисковой системы.
Проблема, связанная с индексированием, заключается в том, что приписывание поискового образа документу или информационному ресурсу опирается на представление о словаре, из которого эти термины выбираются, как о фиксированной совокупности терминов. В традиционных системах существовало разбиение на системы с контролируемым словарем и системы со свободным словарем. Контролируемый словарь предполагал ведение некоторой лексической базы данных, добавление терминов в которую производилось администратором системы. Таким образом, все новые документы могли быть заиндексированы только теми терминами, которые были в этой базе данных. Свободный словарь пополнялся автоматически по мере появления новых документов. Однако, на момент актуализации словарь также фиксировался. Актуализация предполагала полную перезагрузку базы данных. В момент этого обновления перегружались сами документы и обновлялся словарь, а после его обновления производилась переиндексация документов. Процедура актуализации занимала достаточно много времени и доступ к системе в момент ее актуализации закрывался.
Теперь представим себе возможность такой процедуры в анархичном Internet, где ресурсы появляются и исчезают ежедневно. При создании программы Veronica для GopherSpace предполагалось, что все серверы должны быть зарегистрированы и таким образом велся учет наличия или отсутствия ресурса. Veronica раз в месяц проверяла наличие документов Gopher и обновляла свою базу данных ПОД'ов документов Gopher. В World Wide Web ничего подобного нет. Для решения этой задачи используются программы сканирования сети или роботы-индексировщики. Разработка роботов - это довольно нетривиальная задача, т.к. существует опасность зацикливания робота или попадания на виртуальные страницы. Все системы имеют своего робота. Робот просматривает сеть, находит новые ресурсы, приписывает им термины и помещает в базу данных индекса. Главный вопрос заключается в том, какие термины приписывать документам, откуда их брать, ведь ряд ресурсов вообще не является текстом. В настоящее время различные роботы используют для индексирования следующие источники для пополнения своих виртуальных словарей: гипертекстовые ссылки, заголовки (title), заглавия (H1, H2 и т.п.), аннотации, списки ключевых слов и полные тексты документов, сообщения администраторов о своих Web-страницах[9]. Для индексирования telnet, gopher, ftp, нетекстовой информации используются главным образом URL, для новостей Usenet и почтовых списков - поля Subject и Keywords. Наибольший простор для построения ПОД'ов дают HTML-документы. Однако не следует думать, что все термины из перечисленных выше элементов документов попадают в их поисковые образы. Очень активно используются списки запрещенных слов (stop-words), которые не могут быть использованы для индексирования, общих слов (предлоги, союзы и т.п.), а также часто производится нормализация лексики. Таким образом, даже то, что в OpenText, например, называется полнотекстовым индексированием реально является выбором слов из текста документа и сравнением с целым набором различных словарей, после которого термин попадает в поисковый образ документа, а потом и в индекс системы. Для того, чтобы не раздувать словарей и индексов, а индекс Lycos, например, равен 4TB, применяется такое понятие как "вес" термина[10]. Документ обычно индексируется 40[6] - 100[8] наиболее "тяжелых" терминами.
После того, как ресурсы заиндексированы, т.е. система составила массив поисковых образов документов, начинается построение поискового аппарата системы. Совершенно очевидно, что лобовой просмотр файла или файлов ПОД'ов займет много времени, что абсолютно не приемлемо для интерактивной системы, которой является Web. Для того, чтобы можно было быстро находить информацию в базе данных ПОД'ов строится индекс. Индекс в большинстве систем - система связанных между собой файлов, которая нацелена на быстрый поиск данных по запросу пользователя. Структура и состав индексов различных систем могут отличаться друг от друга и зависят от многих факторов. К этим факторам можно отнести и размер массива поисковых образов, и информационно-поисковый язык системы, и размещения различных компонентов системы и т.п. Рассмотрим структуру индекса на примере системы[6]. Этот проект выбран потому, что он позволяет реализовывать не только примитивный булевый поиск, но и контекстный поиск, взвешенный поиск и ряд других возможностей, которые отсутствуют во многих поисковых системах, например Internet, Yahoo.
Индекс рассматриваемой системы состоит из таблицы идентификаторов страниц (page-ID), таблицы ключевых слов (Keyword-ID), таблицы модификации страниц, таблицы заголовков, таблицы гипертекстовых связей, инвертированного списка (IL) и прямого списка (FL).
Page-ID отображает идентификаторы станиц в URL этих страниц, Keyword-ID отображает каждое ключевое слов в уникальный идентификатор этого слова, таблица заголовков отображает идентификатор страницы в заголовок страницы, таблица гипертекстовых ссылок отображает идентификатор страниц в гипертекстовую ссылку на эту страницу. Инвертированный список ставит в соответствие каждому ключевому слову список пар (номер документа, идентификатор страницы, позиция слова в странице), а прямой список - это массив поисковых образов страниц. Все эти файлы так или иначе используются при поиске, но главным среди них, безусловно, является файл инвертированного списка. Результат поиска в этом файле - это объединение и/или пересечение списков идентификаторов страниц. Результирующий список, который преобразовывается в список заголовков, снабженных гипертекстовыми ссылками, возвращается пользователю в его программу просмотра Web. Для того, чтобы быстро искать записи инвертированного списка, над ним надстраивается еще несколько файлов, например, файл буквенных пар с указанием записей инвертированного списка, с этих пар начинающихся, а также применяется механизм прямого доступа к данным - хеширование.
Для обновления индекса применяется комбинация двух подходов. Первый можно назвать коррекцией индекса "на ходу". Для этого служит таблица модификации страниц. Суть такого решения довольно проста: старая запись индекса ссылается на новую, которая и используется при поиске. Когда число таких ссылок становится достаточным для того, чтобы ощутить это при поиске, то происходит полное обновление индекса, т.е. его перезагрузка.
Успех информационно-поисковой системы с точки зрения скорости поиска, определяется исключительно архитектурой индекса. Как правило, способ организации этих массивов является "секретом фирмы" и гордостью компании. Для того, чтобы убедиться в этом, достаточно почитать материалы OpenText[11].
InfoSeek
Система InfoSeek обладает довольно развитым информационно-поисковым языком, который позволяет не просто указывать какие термины должны встречаться в документах, но и своеобразно взвешивать их. Достигается это при помощи специальных знаков "+" - термин обязан быть в документе, "-" - термин обязан отсутствовать в документе. Кроме этого InfoSeek позволяет проводит то, что называется контекстным поиском. Это значит, что используя специальную форму запроса можно потребовать последовательной совместной встречаемости слов. Кроме этого можно указать, что некоторые слова должны совместно встречаться не только в одном документе, а даже в отдельном параграфе или заголовке. Есть возможность и указания ключевых фраз. Ключевая фраза от последовательной встречаемости отличается тем, что фраза всегда ищется как единое целое, а при последовательной встречаемости слова могут стоять рядом, но в произвольном порядке. Ранжирование при выдаче осуществляется по числу терминов запроса в документе, по числу фраз запроса в документе, за вычетом общих слов. Все эти факторы используются как вложенные процедуры.
Подводя краткое резюме можно сказать, что InfoSeek относится к традиционным системам с элементом взвешивания терминов при поиске.
- при расширенном поиске нужный документ был найден третьим в списке из десяти документов. Уточнение поиска привело только к миграции документа вглубь списка.
Интерфейс Eudora
Интерфейс Eudora является одним из множества почтовых интерфейсов, ориентированных на работу с почтой Internet из системы MS-Windows. На примере этого интерфейса мы рассмотрим типичные проблемы, которые возникают у пользователей персональных компьютеров при подключении к почтовому сервису Internet, и пути их решения.
Первой проблемой является тот факт, что компьютер выключается из сети на время отсутствия пользователя. Это значит, что в это время прием почтовых сообщений не производится. Следовательно, вся почта должна хранится на почтовом сервере и получаться пользователем по его запросу. При работе с Unix об этом заботится программа sendmail, в MS-Windows такой программы нет (точнее есть, но она не ориентирована на Internet). Поэтому обычно применяется следующая схема (рисунок 3.16):

Рис. 3.16. Схема работы с почтовым сервером из-под MS-Windows и MS-DOS
Такая схема предполагает, что пользователь имеет почтовый ящик на машине-сервере, которая не выключается круглосуточно. Все почтовые сообщения складываются в этот почтовый ящик. По мере необходимости, пользователь из своего почтового клиента обращается к почтовому ящику и забирает из него пришедшую на его имя почту. При отправке программа-клиент обращается непосредственно к серверу рассылки почты и передает отправляемые сообщения на этот сервер для дальнейшей рассылки.
Подробно система рассылки сообщений будет описана ниже, но здесь эти сведения необходимы для описания некоторых особенностей интерфейса Eudora, и поэтому, несколько забегая вперед, имеет смысл с ними познакомится.
На рисунке 3.17 приведен экран Eudora, на котором представлено меню настройки и два почтовых ящика: принятых писем и отправленных писем.
На этом рисунке в меню настроек хорошо виден POP Account - адрес пользователя на машине-сервере, SMTP-сервер и POP (Ph) сервер. Как видно из настроек, Eudora каждые 30 минут проверяет почтовый ящик пользователя и сообщает о получении новых писем. Кроме того, что Eudora позволяет читать просто письма в обычном почтовом формате Internet (RFC822), о котором пойдет речь в следующем параграфе, она распознает и новый формат, ориентированный на отображение мультимедийных почтовых сообщений MIME, который последнее время становится все более популярен в Internet.
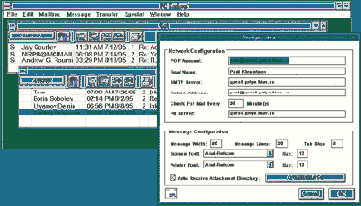
Рис. 3.17. Интерфейс Eudora для MS-Windows
Для установки этого интерфейса требуются определенные знания и доступ к информации, которой располагает только системный администратор, поэтому предпочтительней обратиться именно к нему с просьбой об установке программы или за необходимой информацией (адреса машин серверов). Работа с Eudora чрезвычайно проста: надо выбирать при помощи мыши или клавиатуры интересующие Вас сообщения и отправлять в "корзину" то, что бесполезно.
И последнее замечание относительно работы из под MS-Windows с почтой в Internet. Если пользователь пишет только по английски, то у него нет проблем с кодировкой и набором текста, но если он пишет по русски и получает такие же сообщения, то сразу же возникают проблемы. Дело в том, что большинство почтовых сетей для обмена данными между серверами используют кодировку KOI8. Эта кодировка отличается как от кодировки для MS-DOS, так и от кодировки MS-Windows. Поэтому, возвращаясь к иллюстрации с настройками интерфейса Eudora, хочется обратить внимание читателя на поля "Send Font" и "Printer Font". В этих полях указан шрифт "Arial-Relcom", который разложен по кодировке KOI8, и используется для отображения и печати почтовых сообщений. Для того, чтобы правильно набирать сообщения, следует к стандартным раскладкам клавиатуры в драйвере клавиатуры (cyrwin, например) добавить раскладку для KOI8.
При этом драйвер должен уметь менять раскладку по мере необходимости. В противном случае у пользователя будет возможность читать сообщения, но не набирать их.
На этом описание существующих почтовых клиентов можно закончить, так как в наличии имеется их великое множество и описать их все в рамках этого курса нет возможности.
Интерфейс пользователя (telnet) и демон (telnetd)
Для того, чтобы протокол стал реально шествующим стандартом, нужна программа, его реализующая, такими программами являются telnet и telnetd в Unix-системах.
Интерфейс системы
Важным фактором является вид представления информации в программе-интерфейсе. При этом различают два типа интерфейсных страниц: страницы запросов и страницы результатов поиска.
При составлении запроса к системе используют либо меню-ориентированный подход, либо командную строку. Меню-ориентированный подход позволяет ввести список терминов, обычно через пробел, и выбрать тип логической связи между ними. Логическая связь распространяется на все термины. На нашей схеме (рисунок 3.41) есть так называемые сохраненные запросы пользователя. В большинстве систем это просто фраза на ИПЯ, которую можно расширить за счет добавления новых терминов и логических операторов. Но это только один тип использования сохраненных запросов. В традиционных системах это называется расширением или уточнением запроса, в зависимости от того, что получаем в результате преобразования запроса: увеличение размера выборки или ее сокращение. При этом традиционная система хранит не запрос как таковой, а результат поиска, т.е. список идентификаторов документов, который объединяется/пересекается со списком полученным при поиске документов по новым терминам. К сожалению, сохранение списка идентификаторов найденных документов в World Wide Web не практикуется. Вызвано это особенностью протоколов взаимодействия программы-клиента и сервера системы, которые не поддерживают сеансовый режим работы.
Как стало уже понятно из выше изложенного, результат поиска в базе данных ИПС - это список указателей на удовлетворяющие запросу документы. Различные системы представляют этот список по-разному. В некоторых системах выдается только список ссылок, а в таких системах как Lycos, AltaVista, Yahoo кроме ссылок дается еще и краткое описание, которое заимствуется либо из заголовков, либо из тела самого документа. Кроме этого система сообщает на сколько найденный документ соответствует запросу. В Yahoo, например, сообщается сколько терминов запроса содержится в поисковом образе документа и в соответствии с этим ранжируется результат поиска. В Lycos выдается мера соответствия документа запросу и ранжирование производится по этому параметру. Обычно пользователь имеет возможность уточнить запрос.
При обзоре интерфейсов и средств поиска нельзя пройти мимо процедуры коррекции запросов по релевантности[7]. Релевантность - это мера соответствия найденного системой документа потребности пользователя. Различают формальную релевантность и реальную. Формальная - это та, что вычисляет система и на основании чего ранжируется выборка найденных документов. Реальная - это та, как сам пользователь оценивает найденные документы. Некоторые системы имеют для этого специальное поле[6], где пользователь может отметить документ как релевантный. При следующей поисковой итерации запрос расширяется терминами этого документа. И выдача снова ранжируется. Так происходит до тех пор, пока результат не стабилизируется. Это означает, что ничего лучше, чем полученная выборка, от данной системы не добьешься.
Кроме ссылок на документы в списке, полученном пользователем, могут оказаться ссылки на части документов или на их поля. Это происходит при наличии ссылок типа http://host/path#mark или ссылок по схеме WAIS. Возможны ссылки и на скрипты, но обычно такие ссылки роботы пропускают и система не индексирует. Если с http-ссылками все более или менее понятно, то ссылки WAIS - это гораздо более сложные объекты. Дело в том, что WAIS реализует архитектуру распределенной информационно-поисковой системы. Это значит, что одна ИПС, например, Lycos строит поисковый аппарат над поисковым аппаратом другой системы - WAIS. При этом серверы WAIS имеют свои собственные локальные базы данных. При загрузке документов в WAIS администратор может описать структуру документов, т.е. разбить их на поля, и хранить документы как один файл. индекс WAIS будет ссылаться на отдельные документы и их поля как на самостоятельные единицы хранения. В этом случае программа просмотра ресурсов Internet должна уметь работать с протоколом WAIS, чтобы получить доступ к этим документам.
История развития, отцы-основатели, современное состояние
Что же предлагал Тим Бернерс-Ли в 1989 году и что из этого получилось? В "World Wide Web: Proposal for HyperText Project", направленных руководству CERN, он считал, что информационная система, построенная на принципах гипертекста, должна объединить все множество информационных ресурсов CERN, которое состояло из базы данных отчетов, компьютерной документации, списков почтовых адресов, информационной реферативной системы, наборов данных результатов экспериментов и т.п. Гипертекстовая технология должна была позволить легко "перепрыгивать" из одного документа в другой.
Проект делился на две фазы, или, как у нас принято говорить, очереди. Первая очередь (продолжительностью в три месяца) должна была показать жизнеспособность идеи проекта. В течении этого этапа работ предполагалось разработать программы-интерфейсы для работы в алфавитно-цифровом режиме и программу-интерфейс для Macintosh и NeXT, работающую в графическом режиме, сервер для доступа к ресурсам Usenet, сервер для доступа к информационно-поисковой системе CERN, гипертекстовый сервер и программу-шлюз между Internet и DECnet.
В последующие три месяца (вторая очередь) предполагалось разработать средства подготовки гипертекстовых документов, полноэкранную программу просмотра для VM/XA, X-Window-интерфейс и систему автоматической нотификации просматриваемых материалов.
Кроме программного обеспечения предполагалось разработать общий протокол обмена информацией в сети, метод отображения текста на экране компьютера, создать набор базовых документов, иллюстрирующих работу системы, который мог бы пополняться за счет документов пользователей, обеспечить поиск по ключевым словам в этом наборе документов.
Любопытно, что из проекта в обязательном порядке исключались всякие исследования, связанные с конвертированием информации из форматов каких-либо редакторов в форматы данных системы, возможностью работы с видео- и аудио-информацией, все работы, связанные с защитой информации от несанкционированного доступа.
На всю эту полугодовую работу автор просил 4-х разработчиков (software designers) и одного программиста, и для каждого из них отдельное рабочее место (компьютер того типа, для которого разработчик будет писать программное обеспечение). Кроме этого требовалось приобрести коммерческое программное обеспечение, которое было бы полезно при разработке системы (Guide, KMS, FrameMaker).
Как видно, запросы были невелики, и в октябре 1990 года проект стартовал. Уже в ноябре был реализован прототип системы для NeXT, к рождеству "задышал" line mode browser, разработке которого придавалось особое значение, т.к. он открывал доступ к системе через telnet, а в марте его можно было уже демонстрировать. Через год в Internet был установлен анонимный telnet для доступа в систему. Первое сообщение об WWW было послано в телеконференции: alt.hypertext, com.sys.next, comp.text.sgml и comp.mail. multimedia, в августе 1991 года.
По современным меркам результаты, которых достигли разработчики к 1991 году выглядят довольно скромно, если не вдаваться в суть работы и ограничиться только внешним ее проявлением. Сообщество Internet получило еще одну программу, работающую в режиме командной строки. Прошло еще целых полтора года до того момента, когда программа Mosaic, разработанная Марком Андресеном (Mark Andressen) из Национального Центра Суперкомпьютерных Приложений (NCSA), и построенная на принципах WWW, обеспечили бурный рост популярности "паутины" в Internet.
NCSA начала проект по разработке интерфейса в World Wide Web месяц спустя после объявления CERN. Одна из задач NCSA - это разработка доступных некоммерческих программ, с другой стороны NCSA изучает новые технологии на предмет их коммерческого применения в будущем. World Wide Web безусловно подходила под эти два параметра. Кроме того, спецификации WWW производили впечатление добротно выполненной академической работы с обзором литературы по данному вопросу, обилием ссылок и обоснованностью принятых решений. Мультипротокольный переносимый интерфейс в WWW, создание которого начала Группа Разработки Программного Обеспечения NCSA, был назван Mosaic. Пробная версия программы была закончена в первой половине 1993 года, а в августе 1993 была анонсирована альфа-версия для Internet.
Следует отметить, что сам проект Mosaic внес огромный вклад в развитие спецификаций World Wide Web, существенно обогатив различные компоненты системы. Разработчики Mosaic ввели в стандарты WWW большое количество новшеств. Агрессивная политика команды NCSA привела к тому, что многие программы-интерфейсы, разработанные в рамках ранних стандартов, постепенно стали отмирать, не выдержав конкуренции. Для самого NCSA это закончилось тем, что лидер команды, Марк Андресен, покинул в марте 1994 года NCSA и организовал коммерческую корпорацию Netscape. C этого момента начался новый этап борьбы, но теперь между старыми коллегами. Netscape активно навязывает свои стандарты, что приводит к тому, что документы, подготовленные с расширениями Netscape неправильно отображаются Mosaic, а документы с расширенными возможностями NCSA могут вообще не отображаться Netscape.
Следует отметить, что проект NCSA преследовал большие цели, нежели просто программу-интерфейс в WWW. С самого начала Mosaic разрабатывалась как программа с возможностями доступа к ресурсам Internet посредством различных протоколов, в число которых входили FTP, telnet, NNTP, SMTP. Однако вначале предполагалось, что делаться это будет за счет вызова внешних, относительно Mosaic, программ. В настоящее время Netscape сам поддерживает, кроме перечисленных, протоколы доступа в Gopher и Wais. Последнее позволяет использовать Netscape, впрочем как и Mosaic, для работы вне рамок World Wide Web.
Mosaic на некоторое время затмила разработки CERN. Однако эта группа имела хорошо продуманную стратегию развития системы, которая включала в себя следующие основные моменты: разработка и поддержка стандартов спецификаций системы, разработка библиотеки свободно распространяемых мобильных кодов системы, полного комплекта средств, обеспечивающих разработку и реализацию компонентов системы на любом типе компьютера в сети, подготовка набора справочных и демонстрационных документов о состоянии сети и направлениях ее развития. Данная стратегия позволила распространять программное обеспечение, разработанное в рамках проекта в Internet, а наличие line mode broser'а позволила открыть возможности WWW для огромной аудитории пользователей алфавитно-цифровых устройств, подключенных в сеть. Некоторое время NCSA лидировала и по числу установок серверов, однако в настоящее время CERN обеспечил себе паритет и в этой области. Правда, и здесь не обошлось без "накладок". Так, форматы файлов конфигурации программы imagemap, обеспечивающей работу с графическими гипертекстовыми ссылками, у этих двух серверов различны.
Другим показателем успешного развития работ является образование W3-консорциума. Консорциум образован после подписания соглашения между Масачусетским Технологическим Институтом (MIT, USA) и Национальным Институтом Информатики и Автоматики (INRA, France) c согласия CERN. Если не вдаваться в подробности, то смысл этого соглашения заключается в том, что все программное обеспечение аккумулируется в MIT, участники имеют право copyright на все разработанное программное обеспечение и спецификации. Программное обеспечение распространяется свободно. За представителем MIT закрепляется должность директора, а за представителем INRA - должность зам. директора. Взносы полноправных участников W3C составляют $50.000 в год, а ассоциированных членов - $5.000 в год, соглашение заключено на три года начиная с 1 октября 1994 года. Любопытно, что организации с годовым оборотом, превышающим $50 миллионов, обязаны регистрироваться как полноправные члены, и что консорциум надеется получать прибыль, превышающую $1,5 миллиона, т.к. предусмотрен порядок использования средств сверх этой суммы. Средства до этого предела используются на развитие системы и исследования.
Образование Netscape Corporation и W3C легко объяснимы с точки зрения роста популярности WWW. В марте 1993 года трафик World Wide Web составлял 0,1% от общего трафика сети NSF, сентябре 1993 года он уже составил 1,0% от общего трафика сети NSF. В октябре 1993 года количество зарегистрированных серверов WWW равнялось 500, а к июню 1994 года оно достигло 1500 и продолжает стремительно расти.
Следует отметить, что появление технологии WWW и ее бурный прогресс не одинок. Приблизительно в это же время появились и другие распределенные информационные технологии в Internet. Это, в первую очередь, Gopher и Wais. Столь бурный рост этого сектора компьютерных технологий привел к появлению на свет очень интересного документа, подготовленного по заказу Комиссии Европейского Союза к ежегодной встрече руководителей Союза 24-25 июня 1994 года на Корфу. Документ прямо обращает внимание руководителей стран Союза на тот факт, что происходит бурный рост рынка информационных технологий, и если Союз не хочет в очередной раз оказаться на вторых ролях, то должен предпринять энергичные усилия по поддержке работ в этой области. Авторы доклада утверждают, что происходит очередная техническая революция, вызванная возможностями современных телекоммуникационных систем и компьютерных сетей. Авторы выделяют десять основных сфер применения новых технологий:
работа посредством сети, т.е. создание новых рабочих мест; обучение по сети; научные коммуникации; обычные услуги по сети; управление дорожным движением; управление воздушным движением; быстрое медицинское обслуживание; создание единой системы защиты прав потребителей и производителей информационных услуг; создание единой европейской административной сети; создание информационной сети общего пользования для всех граждан Союза.
В каком-то смысле учреждение W3C является ответом профессионалов на медлительность бюрократов из Комиссии ЕвроСоюза. Среди учредителей W3C один из авторов документа - Мартин Банжеманн (Martin Bangemann).
Следующим важным этапом развития технологии World Wide Web стало появление весной 1995 года языка программирования Java, анонсированного компанией Sun Microsystems. Если быть более точным, то прямое отношение к World Wide Web имеет не сам язык, а мобильные коды и возможность их интерпретации программами просмотра Web. Создав свой броузер (программу просмотра) HotJava, Sun смогла продемонстрировать, что идеология интерпретации языка разметки документов может быть расширена. В страницы теперь можно стало встраивать фрагменты программ, которые после передачи по сети активировались на компьютере пользователя, расширяя тем самым концепцию распределенных вычислений.
К этому времени кроме Java появились еще и языки управления сценариями просмотра документов, самым известным из которых стал JavaScript. Тем самым, к середине 1996 года технология World Wide Web превратилась в полноценную гипертекстовую технологию, которая стала позволять решать большинство из тех задач, до которых доросли локальные гипертекстовые системы.
Учитывая все сказанное выше, попытаемся подробно остановиться на особенностях World Wide Web и отдельных ее компонентах, спецификациях и способах наращивания системы за счет внешнего программного обеспечения, существующем программном обеспечении и особенностях его функционирования на различных компьютерных платформах. Этим вопросам и будут посвящены следующие несколько разделов.
Языки типа "Like this"
При внимательном рассмотрении взвешенного поиска закрадывается естественное желание вообще обойтись без логических коннекторов и измерять близость документа и запроса какими-либо другими критериями. Наиболее простой моделью этого типа является линейная модель индексирования и поиска, когда близость документа и запроса рассматривается как угол между ними. В этом случае высчитывается sin угла, который получают как скалярное произведение двух векторов. В соответствии со значением меры близости происходит ранжирование документов при выдаче ссылок на них пользователю. Вообще говоря, скалярное произведение не очень хорошо подходит для информационно-поисковых систем Internet, так как длина запроса обычно невелика. Это в традиционных системах существовали специальные службы, которые отлаживали длинные запросы, а в Internet такие службы только нарождаются. Поэтому реально применяются другие меры близости, но принцип остается тот же: сначала вычисляется мера, а потом происходит ранжирование.
Рассмотренный подход дает возможность более мягкого расширения и уточнения запросов, но он также не гарантирует высоких показателей релевантности, в случае выбора неудачной лексики.
Электронная почта в Internet
Электронная почта - один из важнейших информационных ресурсов Internet. Она является самым массовым средством электронных коммуникаций. Любой из пользователей Internet имеет свой почтовый ящик в сети. Если учесть, что через Internet можно принять или послать сообщения еще в два десятка международных компьютерных сетей, некоторые из которых не имеют on-line сервиса вовсе, то становится понятным, что почта предоставляет возможности, в некотором смысле даже более широкие, чем просто информационный сервис Internet. Через почту можно получить доступ к информационным ресурсам других сетей. Хорошим примером может служить доступ к архивам сети BITNET - документам и телеконференциям, которые ведутся на серверах списков (LISTSERVER) BITNET.
Эмуляция удаленного терминала. Удаленный доступ к ресурсам сети
Telnet - это одна из самых старых информационных технологий Internet. Она входит в число стандартов, которых насчитывается три десятка на полторы тысячи рекомендуемых официальных материалов сети, называемых RFC (Request For Comments).
Под telnet понимают триаду, состоящую из:
telnet-интерфейса пользователя; telnetd-процесса; TELNET-протокола.
Эта триада обеспечивает описание и реализацию сетевого терминала для доступа к ресурсам удаленного компьютера.
В настоящее время существует достаточно большое количество программ - от Kermit до различного рода BBS (Belluten Board System), которые позволяют работать в режиме удаленного терминала, но ни одна из них не может сравниться с telnet по степени проработанности деталей и концепции реализации. Для того, чтобы оценить это, знакомство с telnet стоит начать с протокола.
Кэширующий сервер
- это другая разновидность сервера, точнее другое свойство сервера World Wide Web. Главная задача кэширующего сервера - это сокращение трафика в сети. Кэширующий сервер захватывает документы, которые пользователи запрашивают из сети. Обычно этот прием применяется на серверах посредниках. Таким образом создается временная локальная база данных страниц. Как показывает практика пользователи в своей массе, до 80% от их общего числа, используют одну и туже информацию, что составляет только около 20%, опрашиваемых информационных ресурсов. Если документы захватываются и хранятся на кэширующем сервере, то это позволяет разгрузить обмен по сети.
Все виды серверов можно использовать и для анализа статистики посещения серверов. Рассмотрим теперь конкретные пример серверов.
Кластерная модель и Вероятностная модель информационного поиска
В кластерной модели может использоваться два подхода. Первый заключается в том, что массив заранее разбивается на подмножества документов и при поиске высчитывается близость запроса некоторому подмножеству. В другом подходе кластер "накручивается" вокруг запроса и ближайших к нему терминов. Наиболее часто эта модель применяется в системах, уточняющих запрос по релевантности найденных документов.
При вероятностной модели вычисляется вероятность принадлежности документа классу релевантных запросу документов. При этом используется вероятность принадлежности терминов запроса каждому из документов базы данных.
Команда DATA
вводится без параметров и идентифицирует начало ввода почтового сообщения. Сообщение вводится до тех пор, пока не будет введена строка с точкой в первой позиции. Согласно стандарту почтового сообщения RFC-822 отправитель передает заголовок и тело сообщения, которые разделены пустой строкой. Сам протокол SMTP не накладывает каких-либо ограничений на информацию, которая заключена между командой DATA и "." в первой позиции последней строки. Приведем пример обмена сообщениями при дисциплине отправки почты:
S: MAIL FROM: <paul@quest.polyn.kiae.su> R: 250 Ok S: RCPT TO: <dobr@kiae.su> R: 250 Ok S: DATA R: 354 Start mail input; end with <CRLF>.<CRLF> S: Это текст почтового сообщения S: . R: 250
Другой дисциплиной, определенной в протоколе SMTP, является перенаправление почтового сообщения (forwarding). Если получатель не найден и известно его местоположение, то сервер может выдать сообщение:
R: 251 User not local; will forward to <user@domain.domain>
Если сервер может сделать только предположение о дальнейшей рассылке, то ответ будет несколько иным:
R: 551 User not local; please try <user@host.domain>
Верификация и расширение адресов составляют дисциплину верификации. В ней используются команды VRFY и EXPN. По команде VRFY сервер подтверждает наличие или отсутствие указанного пользователя:
S: VRFY paul R: 250-Paul Khramtsov<paul@quest.polyn.kiae.su>
Используя команду EXPN, можно получить список местных пользователей:
S: EXPN Example-People R: 250-Paul Khramtsov<paul@quest.polyn.kiae.su> R: 250-Vladimir Drach-Gorkunov<vovka@quest.polyn.kiae.su>
В список дисциплин, разрешенных протоколом SMTP, входит кроме отправки почты еще и прямая рассылка сообщений. В этом случае сообщение будет отправляться не в почтовый ящик, а непосредственно на терминал пользователя, если пользователь в данный момент находится за своим терминалом. Прямая рассылка осуществляется по команде SEND, которая имеет такой же синтаксис, как и команда MAIL. Кроме SEND прямую рассылку осуществляют SOML (Send or Mail) и SAML (Send and Mail).
Для инициализации канала обмена почтой и его закрытия используются команды HELO и QUIT соответственно. Первой командой сеанса должна быть команда HELO.
Протокол допускает рассылку почтовых сообщений в режиме оповещения. Для этого отправитель в адресе получателя может указать несколько пользователей или групповой адрес. Обычно, программное обеспечение SMTP выбирает эту информацию из заголовка почтового сообщения и на ее основе формирует параметры команд протокола.
Если сообщение по какой-либо причине не может быть разослано, то получатель формирует сообщение о неразосланном сообщении:
S: MAIL FROM:<> R: 250 Ok S: RCPT TO: <@host.domain:JOE@host.domain> R: 250 Ok S: DATA R: 354 send the mail data, end with . S: Date 23 Oct 95 11:23:30 S: From: SMTP@remote.domain S: To: <JOE@host.domain> S: S: Undelivered message. Your message lost. 550 No such user. S: .
При использовании доменных имен следует использовать канонические имена, т.к. некоторые системы не могут определить синоним по базе данных named.
Кроме вышеперечисленных дисциплин, протокол позволяет отправителю и получателю меняться ролями друг с другом. Происходит это по команде TURN.
Для отладки или проверки соединения по SMTP можно использовать telnet. Для этого вслед за адресом машины следует ввести номер порта:
/users/local>telnet apollo.polyn.kiae.su 25
25 порт используется в Internet для обмена сообщениями по протоколу SMTP. В интерактивном режиме пользователь сам изображает клиента SMTP и может посмотреть реакцию удаленной машины на его действия.
Команда "Прервать процесс"
(Interrupt Process - IP). Данная команда реализует стандартный для многих систем механизм прерывания процесса выполнения задачи пользователя (Cntrl+C в Unix-системах или Cntrl+Break в MS-DOS). Следует заметить, что команда IP может быть использована и другим протоколом прикладного уровня, который может использовать telnet.
Команда "Прервать процесс выдачи"
(Abort Output - AO). Многие системы позволяют остановить процесс, выдающий информацию на экран. Здесь следует понять отличие данной команды от IP. При выполнении IP прерывается выполнение текущего процесса пользователя, но не происходит очистка буфера вывода, т.е. процесс может быть остановлен, а буфер вывода будет продолжать передаваться на экран. Обычно это происходит при взаимодействии по медленным линиям связи. Пользователи персональных компьютеров прекрасно знакомы с этой особенностью буферизованных устройств, когда возникают проблемы с остановкой печати: пользователь уже прервал печать и очистил по команде print /t буфер печати на компьютере, а лазерный принтер продолжает изводить бумагу лист за листом. Это типичный пример непродуманного подхода к процессу управления терминальным устройством, который характерен для разработчиков MS-DOS. Для того, чтобы избежать подобного казуса и существует команда AO. Реально проверить ее может любой пользователь медленного телефонного канала связи - для этого можно запустить команду more для просмотра большого файла, после этого по команде Cntrl+C прервать ее - выдача информации на экран будет продолжаться, и после этого выдать из командной строки telnet команду AO, что прервет выдачу.
Команда "Ты еще здесь?"
(Are You There - AYT). Назначение этой команды - дать возможность пользователю убедиться, что в процессе работы по медленным линиям он не потерял связи с удаленной машиной. В силу буферизации ввода и вывода может оказаться, что пользователь может вводить данные, а связь с удаленной машиной уже потеряна. В стандартной ситуации этот факт будет обнаружен только после нажатия клавиши "Enter". Telnet дает возможность убедится в наличии связи в любой момент времени.
Команда "Удалить символ"
(Erase Character - EC). Многие системы обеспечивают возможность редактирования командной строки путем введения так называемых символов "забой" или удалением последнего напечатанного символа на устройстве отображения. В любом случае последний введенный в буфер символ удаляется. Команда EC призвана стандартизировать реализацию этого механизма.
Команда "Удалить строку"
(Erase Line - EL). Данная команда аналогична EC, но удаляет целую строку ввода. Обычно выполнение этой команды приводит к очистке буфера ввода, т.к. при работе в режиме командной строки строка ввода только одна.
Синхронизация. В локальных системах синхронизация работы процессов обычно реализуются через механизм прерываний или, как в Unix, механизм сигналов. Это означает, что система имеет возможность вмешаться в процесс обработки данных практически в любой момент времени. В контексте взаимодействия программы обработки данных и терминальной программы это означает возможность прервать программу обработки или очистить один из буферов с/без отображением(я) информации из него. Именно к этому типу взаимодействия относятся команды IP и AO. Однако в сети сделать это не так просто, как в локальной вычислительной среде. Данные при передаче между машинами буферизуются и обмен происходит пакетами. Если бы команда "Прервать процесс" просто вставлялась в последовательность символов в пакете, то это приводило бы к эффекту запаздывания, т.е. после ввода пользователем команды "прервать процесс", а процесс будет продолжать выполняться пока не доберется до идентификатора команды IP в полученном пакете. Результат - бесполезно потраченное время. Поэтому механизм синхронизации telnet состоит из использования специальной формы пакета TCP (TCP Urgent notification) и команды DATA MARK (DM). Специальная форма TCP пакета используется для изменения процедуры обработки пакетов. Обычно пакет обрабатывается, начиная с первого символа пакета последовательно. В случае специальной формы пакета сначала происходит поиск "интересных" сигналов, а уже потом производится обработка пакета по стандартному сценарию. Команда DM обычно замыкает пакет и обозначает конец специальной обработки. Если TCP-пакет содержит специальные символы до DM, то порядок специальной обработки отменяется, а DM воспринимается как команда No- Operation (NO). Если специальные символы не найдены, то порядок специальной обработки пакетов продолжается. В этом смысле интересными сигналами или символами являются стандартные команды telnet IP, AO, AYT или другие команды, требующие немедленного выполнения.
Команды telnet имеют свой формат. Команда - это 2-байтовая последовательность, состоящая из Esc-символа (255) IAC (Interpret as Command) и кода команды (240-255). Команды, связанные с процедурой согласования параметров сеанса, имеют 3-х байтовый формат: третий байт - ссылка на устанавливаемую опцию.
Стандартным портом TCP для telnet является порт 23.
Конверт
. Конверт состоит из адреса отправителя, адреса получателя и информации рассылки, которая используется программами подготовки, рассылки и получения почты. Конверт остается невидимым для отправителя и получателя почтового сообщения.
Коррекция запроса по релевантности
Многие системы применяют механизм коррекции запроса по релевантности. Это означает, что процедура поиска носит интерактивный и итеративный характер. После проведения первичного поиска пользователь отмечает из всего списка найденных документов релевантные. На следующие итерации система расширяет/уточняет запрос пользователя терминами из этих документов и снова выполняет поиск. Так продолжается до тех пор пока пользователь не сочтет, что лучшего результата, чем он уже имеет добиться не удастся. Коррекция запроса по релевантности - это достаточно широко внедренный способ уточнения запросов. В некоторых системах пользователь может и не знать, о том, что эта процедура применяется, например, OpenText. В этом случае несколько итераций выполняется без его вмешательства.
Весь этот краткий обзор современного состояния ИПЯ ставил перед собой одну простую задачу: определить степень развития и современный уровень информационно-поисковых средств Internet.
Lycos
Как и большинство систем, Lycos дает возможность использовать простой запрос и более изощренный метод поиска. В простом запросе в качестве поискового критерия вводится предложение на естественном языке. Lycos производит нормализацию запроса, удаляя из него так называемые stop-слова, и только после этого приступает к его выполнению. Почти сразу выдается информация о числе документов на каждое слово, а уже позже и список ссылок на формально релевантные документы. В списке напротив каждого документа указывается его мера близости запросу, число слов из запроса, которые попали в документ и оценочная мера близости, которая может быть больше или меньше формально вычисленной. На апрель 1996 года в Lycos не был реализован булевый поиск, такие планы были анонсированы. Последнее предложение подразумевает только то, что нельзя вводить эти операторы в строке вместе с терминами, но использовать логику через систему меню Lycos позволяет. Последнее относится к расширенной форме запроса, который предназначен для использования искушенными пользователями системы, которые уже научились пользоваться этим механизмом.
Таким образом мы видим, что Lycos относится к системе с языком запросов типа "Like this", но предполагается его расширения и на другие способы организации поисковых предписаний.
- здесь отсеялись "on the" и документ был указан только в конце списка. Поиск по фразе улучшения результатов не дал.
Машино-зависимая часть общего правила преобразования адресов
. В данной секции содержание определяется способом рассылки почты. Например, данная секция при рассылке по SMTP будет отличаться от случая рассылки по UUCP.
В большинстве случаев все изменения, которые приходиться внести в файл конфигурации касаются только имени машины, домена и машин шлюзов в другие почтовые службы. Однако, если у организации имеется достаточно продолжительная и славная история использования электронной почты, то может оказаться, что для нормального функционирования придется произвести и ряд более существенных изменений.
В целом все описанные выше секции решают три основных задачи:
определение окружения sendmail, анализ и преобразование адресов электронной почты, рассылка сообщений при помощи программ рассылки.
При редактировании файла следует учитывать некоторые правила, которые используются при написании файла конфигурации: вся информация локального характера сосредоточена в начале файла, команды одного типа собраны в компактные группы, большую часть файла составляют правила преобразования адресов, в конце файла описаны программы рассылки электронной почты.
Все команды, которые используются в файле настроек sendmail можно представить в виде следующей таблицы:
| Команда | Синтаксис | Назначение |
| Define Macro | Dxvalue | Установить значение x |
| Define Class | Ссword1 word2 ... | Установить значение класса c |
| Define Class | Fcfile | загрузить значение класса из файла |
| Set Option | Oovalue | Установить значение опции o |
| Trusted Users | Tuser1 user2 ... | Определить доверенных пользователей |
| Set Precedence | Pname=number | Для номера ошибки number установить имя name |
| Define Mailer | Mname,[field=value] | Определить программу рассылки почты. |
| Define Header | H[?mflag?]name:format | Определить формат поля заголовка |
| Set Rulset | Sn | Начать определение набора правил преобразования адресов |
| Define Rule | Rlhs rhs comment | Определить правило преобразования адреса. |
Формат команды файла настроек sendmail не очень удобен для чтения. В целом его можно определить следующим образом:

Рис. 3.19. Структура команды файла настроек sendmail
Теперь разберем более подробно некоторые команды и секции файла настроек sendmail. Лучше всего это сделать на основе реального файла. Начнем с секции описания локальных параметров:
################## # local info # ################## Cwlocalhost CP. # UUCP relay host DYucbvax.Berkeley.EDU CPUUCP # BITNET relay host #DBmailhost.Berkeley.EDU DBrelay.kiae.su CPBITNET # "Smart" relay host (may be null) DSrelay.kiae.su # who I send unqualified names to (null means deliver locally) DR # who gets all local email traffic ($R has precedence for unqualified names) DH # who I masquerade as (null for no masquerading) DM # class L: names that should be delivered locally, even if we # have a relay # class E: names that should be exposed as from this host, even if we # masquerade #CLroot CEroot # operators that cannot be in local usernames (i.e., network indicators) CO @ % ! # a class with just dot (for identifying canonical names) C.. # dequoting map Kdequote dequote
Как видно из этого листинга, в данной секции описаны имя данной машины (Dwlocalhost), а также класс машин-шлюзов в другие почтовые системы. При этом наращивание класса происходит по мере описания шлюза для каждого из видов постовых служб. В конце секции описаны символы, которые не могут использоваться в именах пользователей или доменов.
Следующая секция - определение макросов sendmail:
###################### # Special macros # ###################### # SMTP initial login message De$j Sendmail $v/$Z ready at $b # UNIX initial From header format DlFrom $g $d # my name for error messages DnMAILER-DAEMON # delimiter (operator) characters Do.:%@!^/[] # format of a total name Dq$?x$x <$g>$|$g$. # Configuration version number DZ8.6.6
В данной секции описаны сообщения, которые выдает sendmail при взаимодействии с другими транспортными агентами. Как видно из этого описания, определение макроса это не только присваивание значения, но и выполнение определенных действий. Наиболее интересное предложение из всех - предложение определяющее значение макроса q:
Dq$?x$x <$g>$|$g$.
Здесь описана условная подстановка значения. Все предложение можно описать следующей фразой:
"Если значение переменной x установлено, то: q = значение_x <значение_g>, иначе: q=значение_g".
То же самое можно записать и по другому:
if(x!=NULL) { strcpy(q,x); strcat(q," <"); strcat(q,g); strcat(q,">"); { else { strcpy(q,g); }
В данном случае $? соответствует оператору if, $| - else, а $. - конец условного оператора.
Следующая секция - это определение опций:
############### # Options # ############### # strip message body to 7 bits on input? #O7False # Insist that the BIND name server be running to resolve names OI # deliver MIME-encapsulated error messages? OjTrue
В данном случае приведен только фрагмент этой секции. Большинство параметров общие для всех установок sendmail. Указанные же в листинге параметры являются принципиальными с точки зрения режимов работы sendmail. Первый параметр определяет тот факт, что по почте можно пересылать 7-битовую информацию. Согласно RFC-822 информация должна быть 7-битовая, но для передачи кириллицы это значит использовать кодирование, что абсолютно не приемлемо. Поэтому данный параметр должен быть закомментирован. В системах, где используется сервер доменных имен, опция I должна быть установлена, чтобы не было ошибок при идентификации доменов. Последний параметр не является принципиальным, но для более понятного представления его следует установить. Если почтовый клиент не поддерживает MIME, то данный параметр следует закомментировать.
Следующие две секции определяют уровень сообщений об ошибках и доверенных пользователей:
########################### # Message precedences # ########################### Pfirst-class=0 Pspecial-delivery=100 Plist=-30 Pbulk=-60 Pjunk=-100 ##################### # Trusted users # ##################### Troot Tdaemon Tuucp
За этими двумя секциями следует секция описания полей заголовка почтового сообщения, который генерируется программой sendmail:
######################### # Format of headers # ######################### H?P?Return-Path: $g HReceived: $?sfrom $s $.$?_($?s$|from $.$_) $.by $j ($v/$Z)$?r with $r$. id $i$?u for $u$.; $b H?D?Resent-Date: $a H?D?Date: $a H?F?Resent-From: $q H?F?From: $q H?x?Full-Name: $x HSubject: # HPosted-Date: $a # H?l?Received-Date: $b H?M?Resent-Message-Id: <$t.$i@$j> H?M?Message-Id: <$t.$i@$j>
Формат команд данной секции определяет, какие поля включаются в заголовок, а какие не включаются. Данная секция тесно связана с секцией определения программ рассылки почты. Если после "H" нет знака вопроса, то поле включается в заголовок сообщения для любой программы рассылки, если после "H" символ "?" присутствует, то в строке аргументов программы рассылки данный флаг должен быть определен для того, чтобы данное поле было включено в заголовок. Как следует из приведенного выше описания, всегда включаются только поля Recieved и Subject. Все перечисленные поля не являются обязательными полями заголовка.
Следующая секция - правила преобразования адресов. Но прежде чем обсуждать ее содержание следует сказать как и когда sendmail эти адреса преобразовывает.

Рис. 3.20. Порядок обработки адресов
Данная диаграмма представляет типовой набор блоков правил преобразования адресов. Как видно из рисунка, все адреса попадают на правила канонизации адресов (Rule Set 3). Если адреса достаточны для рассылки, то выполняется набор правил 0, в противном случае адреса анализируются на наличие в них доменной информации и, если данная информация отсутствует, то в блоке D она добавляется к адресу. Набор 1 применяется ко всем адресам отправителей, набор 2 применяется ко всем адресам получателей. Набор правил 4 - это выходной набор, который предназначен для преобразования адресов в формат программ рассылки. Ниже приведен фрагмент правил набора 3:
### Rulset 3 -- Name Canonicalization ### S3 # handle null input (translate to <@> special case) R$@ $@ <@> # basic textual canonicalization -- note RFC733 heuristic here R$*<$*>$*<$*>$* $2$3<$4>$5 strip multiple <> <> R$*<$*<$+>$*>$* <$3>$5 2-level <> nesting R$*<>$* $@ <@> MAIL FROM:<> case R$*<$+>$* $2 basic RFC821/822 parsing
Не будем подробно разбирать все записи секции преобразования адресов, их очень много, поясним только сам механизм этого преобразования. Механизм основывается на применении так называемых token'ов и pattern'ов, образованных этими token'ами.
| Pattern | Значение |
| $* | пусто или любое количество token'ов |
| $+ | один или более token'ов |
| $- | точно один token |
| $=x | любое количество token'ов одного класса x |
| $~x | любое количество token'ов, не принадлежащих классу x |
| $x | все token'ы макро x |
Указанные паттерны используются в правой части правила. В левой части правила используются метасимволы, в которые эти паттерны отображаются.
| Символ | Значение |
| $n | Token номер n |
| $[name$] | Каноническое имя |
| $>n | Вызвать набор правил n |
| $@ | Завершить набор правил |
| $: | Завершить правило |
| $#mailer$@host$:user | образец вызова программы рассылки |
XPOL < @ xbm11 . BITNET > $+ < @ $+ . BITNET > $1 % $2 < @ $B > XPOL % xbm11 < @ relay.kiae.su >
В этом примере правило преобразования выглядит следующим образом:
R$+<@$+.BITNET> $1%$2<@$B>
Речь идет о преобразовании адресов сообщений отправленных в BITNET.
Ниже приведен фрагмент правил набора 0, в котором определяется рассылка почты программами рассылки:
###################################### ### Ruleset 0 -- Parse Address ### ###################################### S0 :. # handle local hacks R$* $: $>98 $1 # short circuit local delivery so forwarded email works R$+ < @ $=w . > $: $1 < @ $2 . @ $H > first try hub R$+ < $+ @ $+ > $#local $: $1 yep .... R$+ < $+ @ > $#local $: @ $1 nope, local address # resolve remotely connected UUCP links (if any) # resolve fake top level domains by forwarding to other hosts R$*<@$+.BITNET.>$* $: $>95 < $B > $1 <@$2.BITNET.> $3 user@host.BITNET # forward non-local UUCP traffic to our UUCP relay R$*<@$*.UUCP.>$* $: $>95 < $Y > $1 <@$2.UUCP.> $3 uucp mail # pass names that still have a host to a smarthost (if defined) R$* < @ $* > $* $: $>95 < $S > $1 < @ $2 > $3 glue on smarthost name # deal with other remote names R$* < @$* > $* $#smtp $@ $2 $: $1 < @ $2 > $3 user@host.domain :
За секцией преобразования адресов следует секция определения программ рассылки почты. В ней определяется локальная программа рассылки (mail), программа рассылки для выполнения (sh), и программа рассылки по SMTP.
################################################## ### Local and Program Mailer specification ### ################################################## Mlocal, P=/usr/libexec/mail.local, F=lsDFMrmn, S=10, R=20/40, A=mail -d $u Mprog, P=/bin/sh, F=lsDFMeu, S=10, R=20/40, D=$z:/, A=sh -c $u S10 R<@> $n errors to mailer-daemon R$+ $: $>40 $1 S20 R$+ < @ $* > $: $1 strip host part S40 ##################################### ### SMTP Mailer specification ### ##################################### Msmtp, P=[IPC], F=mDFMuX, S=11/31, R=21, E=\r\n, L=990, A=IPC $h Mesmtp, P=[IPC], F=mDFMuXa, S=11/31, R=21, E=\r\n, L=990, A=IPC $h Mrelay, P=[IPC], F=mDFMuXa, S=11/31, R=61, E=\r\n, L=2040, A=IPC $h
Затем идут правила определения локального преобразования адресов для конкретных программ рассылки, в частности набор правил S11.
# envelope sender and masquerading recipient rewriting # S11 R$+ $: $>51 $1 sender/recipient common R$* :; <@> $@ $1 :; list:; special case R$* $@ $>61 $1 qualify unqual'ed names
В секции программ рассылки мы в нашем примере не указали еще одну важную возможность - рассылку по протоколу UUCP:
Мuucp, P=/usr/bin/uux, F=DFMhuU, S=13, R=23, M=100000, A=uux - -r -z -a$f -gC $h!rmail
Естественно, что правила преобразования адресов S13 и R23 должны быть описаны в файле настроек sendmail.
Модель протокола
. Взаимодействие в рамках SMTP строится по принципу двусторонней связи, которая устанавливается между отправителем и получателем почтового сообщения. При этом отправитель инициирует соединение и посылает запросы на обслуживание, а получатель - отвечает на эти запросы. Фактически, отправитель выступает в роли клиента, а получатель - сервера.

Рис. 3.15. Схема взаимодействия по протоколу SMTP
Канал связи устанавливается непосредственно между отправителем и получателем сообщения. При таком взаимодействии почта достигает абонента в течении нескольких секунд после отправки.
Multipart
. Этот тип содержания тела почтового сообщения определяет смешанный документ. Смешанный документ может состоять из фрагментов данных разного типа. Данный тип имеет ряд подтипов.
Настройка программы sendmail
Настройка программы sendmail происходит при помощи файла /etc/sendmail/conf. Этот файл можно разбить на несколько частей:
Настройка resolver
Как уже говорилось выше, система разрешения доменных имен IP-адресами и обратная процедура построены по схеме "клиент-сервер". Функции из библиотеки libc.a выступают в качестве клиентов и вся их совокупность носит название resolver. Для того, чтобы клиент мог обратиться к серверу, он должен знать следующее:
Установлен ли вообще сервер доменных имен; Если сервер установлен, то где (IP-адрес); Если сервер установлен, то к какому домену относится машина.
Вся совокупность этих параметров задается в файле resolv.conf. Приведем пример этого файла и разберем назначение каждой из команд, которая может быть использована в файле настройки resolver.
Номер версии файла конфигурации
. Данная переменная должна изменяться каждый раз как только в файл конфигурации вносятся какие-либо изменения.