Файлы настройки named
Всего существует три типа файлов настройки программы named, или, как их еще называют, базы данных домена. К ним относятся:
файл начальной загрузки буфера (cache); описания базы данных, он называется named.boot; файлы описания "прямой" и "обратной" зон.
В литературе по named принято начинать с файла описания базы данных named - named.boot
Этот файл named использует для своей настройки и первичной загрузки базы данных домена. Это первое, что ищет named при своем запуске. Если внимательно изучить скрипты начальной загрузки любого Unix, то при запуске сетевых серверов в части, отвечающей за запуск сервера доменных имен, можно увидеть, что в случае отсутствия файла named.boot программа named не будет запущена.
В файле named.boot для описания настроек named используются следующие команды:
Форма запроса клиента
Программа-клиент посылает после установления соединения запрос серверу. Этот запрос может быть в двух формах: в форме полного запроса и в форме простого запроса. Простой запрос содержит метод доступа и запрос ресурса. Например:
GET http://polyn.net.kiae.su/
В этой записи слово GET обозначает метод доступа GET, а http://polyn.net.kiae.su/ - это запрос ресурса. Клиенты, которые способны поддерживать версии протокола выше 0.9 должны пользоваться полной формой запроса. При использовании полной формы в запросе указываются строка запроса, несколько заголовков (заголовок запроса или общий заголовок) и, возможно, тело обозначения ресурса. В форме Бекуса-Наура общий вид полного запроса выглядит так:
<Полный запрос> := <Строка Запроса> (<Общий заголовок>|<Заголовок запроса>|<Заголовок обозначения ресурса>)<символ новой строки>[<тело ресурса>]
Квадратные скобки здесь обозначают необязательные элементы заголовка. Строка запроса - это, практически, простой запрос ресурса. Отличие состоит в том, что в строке запроса можно указывать различные методы доступа и за запросом ресурса следует указывать версию протокола. Например, для вызова внешней программы можно использовать следующую строку запроса:
POST http://polyn.net.kiae.su/cgi-bin/test HTTP/1.0
В данном случае используется метод POST и протокол версии 1.0.
Язык гипертекстовой разметки HTML
Язык гипертекстовой разметки HTML (HyperText Markup Language) был предложен Тимом Бернерсом-Ли в 1989 году в качестве одного из компонентов технологии разработки распределенной гипертекстовой системы World Wide Web.
Разработчики HTML пытались решить две задачи:
дать дизайнерам гипертекстовых баз данных простое средство создания документов; сделать это средство достаточно мощным, чтобы отразить имевшиеся на тот момент представления об интерфейсе пользователя гипертекстовых баз данных.
Первая задача была решена за счет выбора таговой модели описания документа. Такая модель широко применяется в системах подготовки документов для печати. Примером такой системы является хорошо известный язык разметки научных документов TeX, предложенный Американским Математическим Обществом, и программы его интерпретации.
К моменту создания HTML существовал стандарт языка разметки печатных документов - SGML (Standard Generalized Markup Language), который и был взят в качестве основы HTML. Предполагалось, что такое решение поможет использовать существующее программное обеспечение для интерпретации нового языка. Однако, будучи доступным широкому кругу пользователей Internet, HTML зажил своей собственной жизнью. Вероятно, многие администраторы баз данных WWW и разработчики программного обеспечения для этой системы имеют довольно смутное представление о стандартном языке разметки SGML.
Вторым важным моментом, повлиявшим на судьбу HTML, стал выбор в качестве элемента гипертекстовой базы данных обычного текстового файла, который хранится средствами файловой системы операционной среды компьютера. Такой выбор был сделан под влиянием следующих факторов:
такой файл можно создать в любом текстовом редакторе на любой аппаратной платформе в среде любой операционной системы. к моменту разработки HTML существовал американский стандарт для разработки сетевых информационных систем - Z39.50, в котором в качестве единицы хранения указывался простой текстовый файл в кодировке LATIN1, что соответствует US ASCII.
Таким образом, гипертекстовая база данных в концепции WWW - это набор текстовых файлов, написанных на языке HTML, который определяет форму представления информации (разметка) и структуру связей этих файлов (гипертекстовые ссылки).
Такой подход предполагает наличие еще одной компоненты технологии - интерпретатора языка. В World Wide Web функции интерпретатора разделены между сервером гипертекстовой базы данных и интерфейсом пользователя.
Сервер, кроме доступа к документам и обработки гипертекстовых ссылок, осуществляет также препроцессорную обработку документов, в то время как интерфейс пользователя осуществляет интерпретацию конструкций языка, связанных с представлением информации.
К настоящему времени известна уже третья версия языка - HTML 3.0, которая находится в стадии развития. Если первая версия языка (HTML 1.0) была направлена на представление языка как такового, где описание его возможностей носило скорее рекомендательный характер, вторая версия языка ( HTML 2.0) фиксировала практику использования конструкций языка, версия ++ ( HTML++) представляла новые возможности, расширяя набор элементов HTML в сторону отображения научной информации и таблиц, а также улучшения стиля компоновки изображений и текста, то версия 3.0 призвана упорядочить все нововведения и согласовать их с существующей практикой. Кроме этого, в версии 3.0 снова делается попытка формализации интерфейса пользователя гипертекстовой распределенной системы.
Механизмы обмена данными
Собственно спецификация CGI описывает четыре набора механизмов обмена данными:
через переменные окружения; через командную строку; через стандартный ввод; через стандартный вывод.
Небольшой поддомен в домене ru
В данном случае организация получила домен в домене ru и зарегистрировала его в РосНИИРОС. Primary сервер доменных имен установлен на шлюзе 194.226.43.1. Это единственная машина в сети, которая работает под управлением Unix. Все остальные машины - это персональные компьютеры сотрудников. В общем виде схему такого домена можно представить в виде рисунка 3.13:

Рис. 3.13. Структура простой локальной сети
Домен, который зарегистрировала данная организация, пусть будет называться vega.ru. Так как это домен второго уровня, то он должен иметь как минимум два сервера доменных имен: primary и secondary. Основной сервер, primary, установлен на машине-шлюзе, на размещение вторичного получено разрешение от администратора сервера ns.rekarn.ru, который расположен в другой сети, имеющей свой собственный выход в Internet.
Программа named, установленная на машине шлюзе будет иметь следующую конфигурацию, которая задается файлом named.boot:
; ; Zone vega.ru data base files. ; directory /etc/namedb primary vega.ru vega.ru primary 127.in-addr.arpa localhost primary 43.226.194.in-addr.arpa vega.rev forwarders 144.206.136.1 144.206.130.137 cаche . named.root
В этом файле определено, что директория расположения описания файлов зоны vega.ru - /etc/namedb. Это стандартная директория для операционной системы FreeBSD. Файла описания "прямой" зоны домена vega.ru - файл vega.ru будет размещен в этой директории (/etc/namedb/vega.ru). Кроме "прямой" зоны описаны еще две "обратных" зоны 127.in-adrr.arpa и 43.226.194.in-addr.arpa. Первая определяет обратное соответствие между адресом 127.0.0.1 и именем localhost, а вторая множество обратных соответствий для сети 194.226.43.0. Последним указан файл начальной загрузки cache. Символ "." в качестве первого аргумента указывает на описание домена root.
Кроме этого команда forwarders указывает IP-адреса серверов доменных имен, к которым следует обращаться в случае невозможности самостоятельно получить адрес. Это сделано для того, чтобы в начальный период функционирования сервера он мог отвечать на запросы клиентов из данной зоны, хотя сам он еще и не зарегистрирован в корневом сервере домена ru.
В принципе, можно было бы просто указать данные сервера в настройках resolver для машин данного домена, но зато потом везде нужно было бы их снова менять. Использование forwarders позволяет после регистрации домена и размещения серверов не перестраивать настройки всех компьютеров в домене. Кроме того, named сразу начинает работать как интеллектуальный кэширующий сервер, что при частом обращении к одним и тем же именам позволяет быстро получать IP-адреса или имена машин.
Файл описания "прямой" зоны для домена vega.ru будет выглядеть следующим образом (/etc/namedb/vega.ru):
@ IN SOA vega-gw.vega.ru paul.vega.ru ( 101 ;serial number 86400 ;refresh 3600 ;retry 3888000 ;expire 99999999 ;minimum ) ; Name server IN NS vega-gw.vega.ru. IN NS ns.relarn.ru. IN NS polyn.net.kiae.su. IN A 194.226.43.1 IN MX 0 vega-gw.vega.ru. IN MX 10 ns.relarn.ru. ; localhost IN A 127.0.0.1 ; vega-gw IN A 194.226.43.1 IN MX 0 vega-gw IN MX 10 ns.relarn.ru. www IN CNAME vega-gw ftp IN CNAME vega-gw gopher IN CNAME vega-gw ; dos1 IN A 194.226.43.2 dos2 IN A 194.226.43.3 ; The rest of net should be presented below.
Запись SOA берет имя зоны из записи primary файла named.boot (символ "@"). В качестве машины, на которой установлен сервер, указана машина vega-gw.vega.ru, а в качестве администратора - paul@kiae.su. Остальные поля установлены в соответствии с описанием записи SOA.
Обратите внимание на следующее обстоятельство: имя текущей зоны будет взято из команды primary файла named.boot и использоваться для описания зоны, только в том случае если в записи SOA будет указан символ коммерческого "@". Например, в следующем примере могут возникнуть проблемы с описанием зоны:
IN SOA vega-gw.vega.ru paul.vega.ru ( 101 ;serial number 86400 ;refresh 3600 ;retry 3888000 ;expire 99999999 ;minimum ) ; Name server IN NS vega-gw.vega.ru. IN NS ns.relarn.ru. IN NS polyn.net.kiae.su. IN A 194.226.43.1 IN MX 0 vega-gw.vega.ru. IN MX 10 ns.relarn.ru.
Ни NS-записи, ни A-запись, ни MX-записи не привязаны к конкретному домену, и следовательно не используются named.
Две NS-записи определяют три машины в качестве сервера доменных имен для данной зоны: vega-gw.vega.ru, ns.relarn.ru и polyn.net.kiae.su. Первая запись типа A определяет адрес всего домена для обслуживания неполных запросов. Следующие две записи MX определяют правила пересылки почты на домен по адресам типа user@vega.ru.
За описанием зоны в нашем файле следует описание "петли", т.е. имени для адреса 127.0.0.1. В FAQ по сервису доменных имен можно найти и другие решения, но в большинстве случаев, обычно, рекомендуется определять имя localhost как localhost.domain.name, или в нашем случае - localhost.vega.ru.
Первой в домене описана машина-шлюз. На ней установлены сервисы World Wide Web, FTP и Gopher. Для каждого из них определены имена, которые должны облегчить запоминание доменного имени сервера. После записей CNAME идут записи описания других машин зоны. Так как это обычные рабочие места под управлением MS-DOS и Widows, то никаких дополнительных записей для их описания не требуется.
Как утверждается во всех руководствах по DNS, описание обратных зон для домена не является обязательным, но крайне желательно. Для нашего простого домена в файле named.boot описаны две обратные зоны: 127.in-addr.arpa и 43.226.194.in-addr.arpa.
Зона 127.in-addr.arpa описывает обратное соответствие межу адресом 127.0.0.1 и именем lo-calhost.vega.ru. Описание зоны будет располагаться в файле /etc/namedb/localhost:
@ IN SOA vega-gw.vega.ru paul.vega.ru ( 101 ;serial number 86400 ;refresh 3600 ;retry 3888000 ;expire 99999999 ;minimum ) ; Localhost declaration 1 IN PTR localhost.vega.ru.
В данном случае имя зоны также, как и в предыдущем случае берется из команды primary файла named.boot:
primary 127.in-addr.arpa localhost
Согласно этому описанию символ "@" заменяется на имя 127.in-addr.arpa, которое и добавляется к цифре 1, образуя имя 1.127.in-addr.arpa. Так как сеть 127.0.0.0 - это сеть класса А, то адрес 127.1 эквивалентен адресу 127.0.0.1.
Вторая "обратная" зона описывает все остальные IP-адреса и размещается в файле /etc/namedb/vega.rev:
@ IN SOA vega-gw.vega.ru paul.vega.ru ( 101 ;serial number 86400 ;refresh 3600 ;retry 3888000 ;expire 99999999 ;minimum ) IN NS vega-gw.vega.ru. IN NS ns.relarn.ru. IN NS polyn.net.kiae.su. ; Reverse zone description. 1 IN PTR vega-gw.vega.ru. 2 IN PTR dos1.vega.ru. 3 IN PTR dos2.vega.ru. ; description of the other hosts should be placed below. ;
Первые две NS-записи в этом примере определяют сервера доменных имен для этой зоны. Так как "прямая" зона это зона второго уровня в домене ru, то будет логичным и для "обратной" зоны разместить дублирующий сервер в том же месте, что и дублирующий сервер для "прямой" зоны. Имя зоны берется из команды primary файла named.boot:
primary 43.226.194.in-addr.arpa vega.rev
Таким образом к единичке, указанной в записи PTR для машины vega-gw.vega.ru будет получено "обратное" имя 1.43.226.194.in-addr.arpa.
Все имена машин в поле данных записей типа PTR должны обязательно заканчиваться точкой, иначе они будут расширены именем зоны.
И последний файл, который необходим для запуска сервера доменных имен, - это файл начальной загрузки named, определенный в команде cache файла named.boot. В нашем случае этот файл имеет полное имя - /etc/namedb/named.root. Содержание этого файла приведено в примере 5. Файл просто копируется с сервера ftp.internic.net. В ряде случаев провайдеры рекомендуют пользоваться их файлом начальной загрузки, а не стандартным.
Поле версии MIME (MIME-Version)
Поле версии указывается в заголовке почтового сообщения и позволяет программе рассылки почты определить, что сообщение подготовлено в стандарте MIME. Формат поля выглядит как:
MIME-Version: 1.0
Поле версии указывается в общем заголовке почтового сообщения и относится ко всему сообщению целиком. Здесь уместно отметить, что в отличии от стандарта RFC-822 стандарт MIME позволяет перемешивать поля заголовка сообщения с телом сообщения. Поэтому все поля делятся на два класса: общие поля заголовка, которые записываются в начале почтового сообщения и частные поля заголовка, которые относятся только к отдельным частям составного сообщения и записываются перед ними.
Принцип работы программы sendmail
Sendmail отправляет почту в два приема: сначала почтовые сообщения собираются в очереди, а затем отсылаются.
Каждое сообщение состоит из трех частей: конверта, заголовка и тела сообщения.
Принципы построения адреса WWW
В основу URI были заложены следующие принципы:
Расширяемость - новые адресные схемы должны были легко вписываться в существующий синтаксис URI. Полнота - по возможности, любая из существовавших схем должна была описываться посредством URI. Читаемость - адрес должен был быть легко читаем пользователем, что вообще характерно для технологии WWW - документы вместе с ссылками могут разрабатываться в обычном текстовом редакторе.
Расширяемость была достигнута за счет выбора определенного порядка интерпретации адресов, который базируется на понятии "адресная схема". Идентификатор схемы стоит перед остатком адреса, отделен от него двоеточием и определяет порядок интерпретации остатка.
Полнота и читаемость порождали коллизию, связанную с тем, что в некоторых схемах используется двоичная информация. Эта проблема была решена за счет формы представления такой информации. Символы, которые несут служебные функции, и двоичные данные отображаются в URI в шестнадцатеричном коде и предваряются символом "%".
Прежде, чем рассмотреть различные схемы представления адресов приведен пример простого адреса URI:
http://polyn.net.kiae.su/polyn/index.html
Перед двоеточием стоит идентификатор схемы адреса - "http". Это имя отделено двоеточием от остатка URI, который называется "путь". В данном случае путь состоит из доменного адреса машины, на которой установлен сервер HTTP и пути от корня дерева сервера к файлу "index.html".
Кроме представленной выше полной записи URI, существует упрощенная. Она предполагает, что к моменту ее использования многие параметры адреса ресурса уже определены (протокол, адрес машины в сети, некоторые элементы пути). При таких предположениях автор гипертекстовых страниц может указывать только относительный адрес ресурса, т.е. адрес относительно определенных базовых ресурсов.
Программа-сервер (telnetd)
Telnetd - это сервер, который обслуживает протокол TELNET. Обычно telnetd запускается через сервис Internet (inetd), в некоторых системах может быть запущен и вручную. Telnetd обслуживает TCP-порт 23, но может быть запущен и на другой порт.
Принцип работы сервера заключается в том, что он "слушает" порт TCP. В случае поступления запроса на обслуживание, telnetd назначает каждому удаленному клиенту псевдотерминал (pty) в качестве стандартного файла ввода (stdin), стандартного файла вывода (stdout) и стандартного файла ошибок (stderr).
При установке взаимодействия с удаленным клиентом telnetd обменивается командами настройки (эхо, обмен двоичной информацией, тип терминала, скорость обмена, переменные окружения).
Надо сказать, что telnetd реализует протокол TELNET частично. При работе по telnet никогда не используется сигнал Go Ahead (GA). Двоичный режим передачи данных можно реально использовать только для одинаковых операционных сред.
Статистика доступа к системе и ее анализ
Все сервера обеспечивают контроль доступа к своим информационным ресурсам. Осуществляется он на базе специального журнала доступа. Для пояснения целей задач сбора и обработки статистики буде рассматривать конкретный пример - базу данных "Polyn" РНЦ "Курчатовский Институт"
При обращении к информационным ресурсам систем, разработанных в рамках технологии World Wide Web, главным в процессе обработки запросов пользователя является сервер протокола HTTP. Общая схема получения статистики обращения пользователя к системе может быть изображена следующим образом:
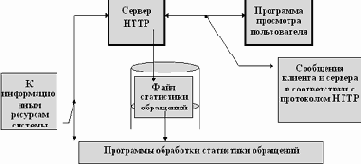
Рис. 3.34. Схема получения статистики обращений к информационным ресурсам базы данных под управлением сервера HTTP
Как отображено на этой схеме (рисунок 3.34) любой сервер ведет файл статистики (в нашем случае файл статистики сервера NCSA 1.2).
Этот файл является главным инструментом при анализе эффективности работы базы данных Web. Каждый сервер ведет статистику посещений базы данных пользователями Internet в этом файле. Прежде чем начать описание содержания такого файла следует условиться об определенной терминологии. Визитом или посещением базы данных Web принято называть обращение к странице базы данных. Посещение следует отличать от сессии и обращения к файлу базы данных (Hit).
Структура базы данных сервера WWW
Итак первой основной задачей для любого сервера является ведение его базы данных. База данных сервера - это часть файловой системы, отведенная для размещения файлов HTML документов. Большинство современных файловых систем - это иерархические деревья, следовательно, и база данных HTTP сервера также является таким деревом. Для любой базы данных необходимо ввести понятие единицы хранения - минимальный объект, к которому можно обратиться извне или получить в качестве ответа на запрос. Стандартным объектом хранения в базе данных HTTP сервера является HTML документ, который является обычном текстовым файлом. Кроме такого стандартного объекта многие серверы поддерживают различные комбинированные объекты хранения, создаваемые в ряде случаев из нескольких файлов или генерируемые программами "на лету".
Если обратиться к терминологии, которая принята в системах World Wide Web, то можно выделить следующие основные объекты, с которыми оперирует сервер и программа-клиент:
Тестирование Sendmail и способы запуска
При работе с программой Sendmail возникает ряд ситуаций, когда необходимо протестировать работу системы рассылки электронной почты. Чаще всего это связано с тем, что программа неаккуратно работает с сервисом доменных имен. Дело в том, что определение макросов w и j связано скорее с функционированием системы в среде NIS, а не BIND, что влечет за собой определенные проблемы при идентификации программы при работе по SMTP, например.
Собственно проблемы возникают между sendmail и resolver. Для их решения следует в файле конфигурации resolver не указывать имя домена, а в файле настроек sendmail сделать это явно.
Для проверки работы можно запустить sendmail с ключом -v:
quest:/usr/paul:\[1\]%sendmail -v paul@polyn.kiae.su This is a test message. . paul@polyn.kiae.su... Connecting to cpuv1.net.kiae.su. (relay)... 220 cpuv1.net.kiae.su (RELCOM) ready ( Tue, 5 Nov 1996 11:46:12 +0300 ) >>> EHLO quest.net.kiae.su 500 Command unrecognized >>> HELO quest.net.kiae.su 250 Hello quest.net.kiae.su, pleased to meet you >>> MAIL From:<paul@quest.net.kiae.su> 250 <paul@quest.net.kiae.su>... Sender ok >>> RCPT To:<paul@polyn.kiae.su> 250 <paul@polyn.kiae.su>... Recipient ok >>> DATA 354 Enter mail, end with "." on a line by itself >>> . 250 Ok paul@polyn.kiae.su... Sent (Ok) Closing connection to cpuv1.net.kiae.su. >>> QUIT 221 cpuv1.net.kiae.su closing connection quest:/usr/paul:\[2\]%
Как видно из этого примера, система выдает полную трассу взаимодействия с удаленным хостом по протоколу SMTP.
Стандартный режим запуска sendmail - это запуск в виде процесса демона в момент начальной загрузки системы:
/usr/paul>sendmail -bd -q30m
Однако, надо всегда помнить, что перед запуском в режиме демона следует создать файл ali-ases:
/usr/paul>sendmail -bi
Методы доступа
В настоящее время в практике World Wide Web реально используются только три метода доступа: POST, GET, HEAD.
Описание "прямой" и "обратной" зон для поддомена определенного на двух подсетях
В данном примере мы рассмотрим описание домена третьего уровня polyn.kiae.su, который определен на двух подсетях сети 144.206.0.0: 144.206.160.0 и 144.206.192.0. Если в предыдущем случае мы выделяли две "обратные" зоны из-за особой роли адреса 127.0.0.1, то в данном случае нам придется выделить "обратные" зоны на каждую из подсетей. Кроме того этот сервер мы также будем использовать в качестве дублирующего для домена vega.ru. Файл named.boot в этом случае будет иметь вид:
; ; Zone polyn.kiae.su - data base files. ; directory /etc/namedb primary polyn.kiae.su polyn.kiae.su primary 127.in-addr.arpa localhost primary 160.206.144.in-add.arpa polyn primary 192.206.144.in-addr.arpa quest secondary vega.ru 194.226.43.1 vega.ru secondary 43.226.194.in-addr.arpa 194.226.43.1 vega.rev forwarders 144.206.136.1 144.206.130.3 cаche . named.root
Как видно из содержания этого файла все файлы описания зоны расположены в директории /etc/namedb (команда directory), описание зоны polyn.kiae.su находится в файле /etc/namedb/polyn.kiae.su, описание зоны 127.in-addr.arpa - в файле /etc/namedb/localhost, описание зоны 160.206.144.in-addr.arpa - в файле /etc/namedb/polyn, описание зоны 192.206.144.in-addr.arpa - в файле /etc/namedb/quest. Кроме этого, после запуска, данный сервер опрашивает primary сервер зоны vega.ru и копирует с него зоны vega.ru и 43.226.194.in-addr.arpa. Первую в файл /etc/namedb/vega.ru, а вторую в файл /etc/namedb/vega.rev. Перейдем теперь к описанию файлов зоны polyn.kiae.su.
; ; Zone -- polyn.kiae.su $ORIGIN kiae.su. polyn IN SOA polyn.net.kiae.su. paul.kiae.su. ( 36 3600 300 9999999 3600 ) ; IN NS polyn.net.kiae.su. IN NS ns.kiae.su. IN A 144.206.160.32 IN MX 0 ns.polyn.kiae.su. IN MX 10 relay.net.kiae.su. $ORIGIN net.kiae.su. polyn IN A 144.206.130.137 $ORIGIN kiae.su. ns IN A 144.206.130.3 $ORIGIN polyn.kiae.su. * IN MX 2 ns.polyn.kiae.su. IN MX 10 relay.net.kiae.su. ; ns IN A 144.206.160.32 www IN CNAME ns.polyn.kiae.su. ftp IN CNAME ns.polyn.kiae.su. ; kurm IN A 144.206.160.50 IN MX 0 kurm.polyn.kiae.su. IN MX 10 polyn.net.kiae.su. IN MX 20 relay.net.kiae.su. driver IN A 144.206.160.51 lebedev IN A 144.206.160.41 ; georg IN A 144.206.192.5 olga IN A 144.206.192.2 IN MX 0 olga.polyn.kiae.su. IN MX 10 polyn.net.kiae.su. IN MX 20 relay.net.kiae.su. nata IN A 144.206.192.3 kaverin IN A 144.206.192.6 temp IN A 144.206.192.254 ; The rest of zone is placed below ........
Данный пример интересен тем, что в нем наглядно продемонстрировано использование "приклеенных" A-записей.
Начинается домен также, как и в предыдущем примере - с записи SOA. В данном случае зона описывается непосредственно командой $ORIGIN. В записи SOA указано имя домена без точки на конце, что означает, что оно будет расширено именем kiae.su. Следующие две записи определяют серверы доменных имен для данного домена. Но эти серверы расположены в другой зоне. В принципе named способен найти их IP-адреса, но из соображений большей надежности эти две записи сопровождаются "приклеенными" записями. При чем для каждого из серверов определяется домен (команда $ORIGIN) и за тем имя и IP-адрес по записи A. Наличие данных блоков записей заставляет администратора снова определить в качестве текущего домена домен polyn.kiae.su. После этого следует блок записей для которых указан в качестве имени символ "*". Дело в том, что в данной подсети существует несколько машин, которые поддерживают почтовые ящики пользователей, поэтому записи MX при этом символе определяют порядок прохождения почтовых сообщений внутрь домена.
Первая машина домена - ns.polyn.kiae.su. Фактически, это тоже "приклеенная" запись, т.к. это имя уже встречалось раньше. В след за ним определено несколько записей CNAME. Исторически сложилось так, что во многих страницах World Wide Web ссылки стоят на polyn.net.kiae.su, поэтому это имя также должно быть сохранено, но в новых редакциях используется синоним www.polyn.kiae.su.
Далее в домене есть две машины, которые являются почтовыми серверами для пользователей этого домена: kurm и olga.
Файлов "обратных" зон в данном случае определено два: 160.206.144.in-addr.arpa и 192.206.144.in-addr.arpa. Сделано это из-за того, что в данном случае домен определен на двух различных подсетях сети класса B. В принципе, если бы в данный домен были выделены машины не всей подсети, а только ее частей, то для адресов 144.206.160.0, 144.206.161.0, 144.206.162.0 и т.д. до 144.206.192.0 следует описывать "обратные" зоны. При этом каждую из них надо прописывать и в домене старшего уровня, которым в данном случае является 206.144.in-addr.arpa. Рассмотрим примеры описания этих доменов:
$ORIGIN 206.144.in-addr.arpa. 160 IN SOA kiae-gw.kiae.su. root.kiae-gw.kiae.su. ( 22 3600 300 9999999 3600 ) IN NS polyn.net.kiae.su. $ORIGIN net.kiae.su. polyn IN A 144.206.160.32 IN A 144.206.130.137 $ORIGIN 206.144.in-addr.arpa. 160 IN NS ns.kiae.su. $ORIGIN kiae.su. ns IN A 144.206.130.3 $ORIGIN 160.206.144.in-addr.arpa. 53 IN PTR lenya.polyn.kiae.su. 40 IN PTR apollo.polyn.kiae.su. 54 IN PTR kagan.polyn.kiae.su. ; The rest of the domain should be placed below
Данный файл начинается также, как и описание "прямой" зоны, в нем присутствуют те же "приклеенные" записи для описания серверов доменных имен. Это обстоятельство заставляет снова вводить команды $ORIGIN. Весь остаток файла состоит только из записей типа PTR.
Аналогично выглядит и файл 192.206.144.in-addr.arpa:
$ORIGIN 206.144.in-addr.arpa. 192 IN SOA kiae-gw.kiae.su. root.kiae-gw.kiae.su. ( 23 3600 300 9999999 3600 ) IN NS polyn.net.kiae.su. $ORIGIN net.kiae.su. polyn IN A 144.206.160.32 IN A 144.206.130.137 $ORIGIN 206.144.in-addr.arpa. 192 IN NS ns.kiae.su. $ORIGIN kiae.su. ns IN A 144.206.130.3 $ORIGIN 192.206.144.in-addr.arpa. 6 IN PTR kaverin.polyn.kiae.su. 7 IN PTR kost.polyn.kiae.su. 1 IN PTR quest.polyn.kiae.su. 33 IN PTR vovka.polyn.kiae.su. 2 IN PTR olga.polyn.kiae.su. 34 IN PTR paul.polyn.kiae.su. 3 IN PTR nata.polyn.kiae.su. 254 IN PTR temp.polyn.kiae.su. 4 IN PTR demin.polyn.kiae.su. 5 IN PTR georg.polyn.kiae.su.
Как видно из этого примера, записи вовсе не обязательно располагать в порядке нумерации, хотя это и более удобно. Более того, в файле "прямой" зоны также не надо соблюдать порядок или группировать записи по подсетям. Однако, такое группирование облегчает администратору чтение своего файла описания зоны. Важно еще посоветовать чаще использовать комментарии. Особенно если сеть распределена по различным зданиям и администратору необходимо связываться с ответственными за сеть в каждом из этих зданий. Включение телефонов, имен, отчеств и фамилий этих людей в комментарии поможет легко их найти.
Поле типа содержания тела почтового сообщения (Content-Type)
Поле типа используется для описания типа данных, которые содержатся в теле почтового сообщения. Это поле сообщает программе чтения почты, какого сорта преобразования необходимы для того, чтобы сообщение правильно проинтерпретировать. Эта же информация используется и программой рассылки при кодировании/декодировании почты. Стандарт MIME определяет семь типов данных, которые можно передавать в теле письма:
текст (text); смешанный тип (multipart); почтовое сообщение (message); графический образ (image); аудио-информация (audio); фильм или видео (video); приложение (application).
Общая форма записи поля выглядит в записи Бекуса-Наура следующим образом:
Content-Type := type "/" subtype *[";" parameter] type := "application" / "audio" / "image" / "message" / "multipart" / "text" / "video" / x-token x-token := <Два символа "X-", за которыми без пробела следует последовательность любых символов> subtype := token parameter := attribute "=" value attribute := token value := token / quoted-string token := 1*<любой символ кроме пробела и управляющего символа, или tspecials> tspecials := "(" / ")" / "<" / ">" / "@" ; Обязательно / "," / ";" / ":" / "\" / <"> ; должны быть, / "/" / "[" / "]" / "?" / "." ; заключены в / "=" ; кавычки.
Остановимся подробнее на каждом из типов, разрешенных стандартом MIME.
Практика применения скриптов CGI
Применение скриптов широко практикуется в WWW. При их помощи, например, реализованы стеки графических гипертекстовых ссылок, встраивание даты в текст документов, встраивание ответов службы finger, доступ к базам данных и многое другое. Мы рассмотрим простейшие скрипты для распечатки параметров, передаваемых сервером, скрипты по обращению к shell, С скрипты, скрипты доступа к системе управления базами данных ingres и скрипт imagemap.
Простейшие скрипты и преобразование информации. Обсуждение начнем со скриптов, написанных на командном языке SHELL. Самый простой из них будет выглядеть как:
#!/bin/sh echo Content-type: text/plain echo echo This is the result of script execution. #The end of script
Первая строка определяет, что в качестве интерпретатора скрипта будет использован shell, вторая строка открывает заголовок сообщения, передаваемого скриптом серверу, и определяет тип передаваемой информации как обычный текст. Третья строка отделяет тело сообщения от его заголовка. В теле сообщения передается фраза из четвертой строки. Именно она и будет отображаться программой-интерфейсом пользователя.
В качестве следующего примера приведем скрипт, который отображает значения переменных окружения:
#!/bin/sh echo Content-type: text/plain echo echo $REQUEST_METHOD echo $QUERY_STRING echo $CONTENT_TYPE echo $CONTENT_LENGTH #The end of script.
В данном скрипте пользователю будут возвращены значения указанных в строках команды echo переменных окружения.
Пользователю можно вернуть не только значения переменных окружения, но и результаты выполнения команд.
#!/bin/sh echo Content-type: text/plain echo finger paul@polyn.kiae.su #The end of script.
В результате выполнения этого скрипта пользователь получит информацию о пользователе paul с машины polyn.kiae.su.
Завершим обзор простейших скриптов небольшой программой на С:
#include <stdlib.h>; #include <sys/types.h>; main() { long i,n,uid; char input_ch[1024]; char *env; env = getenv("CONTENT_LENGTH"); /* Here we recieve a length */ sscanf(env,"%d",&n); /* of input stream and form */ for(i=0;i<;n;i++) /* command line */ { input_ch[i] = getchar(); } input_ch[i] = '\000'; printf("Content-type: text/html\n\n"); /* First message of a CGI Programme */ /* This message must be a first one */ /* in output sream. */ printf("<TITLE> Cgi script.(example#1)</TITLE>\n"); printf("<H3><I> Russian Research Center \"Kurchatov Institute\"<I></H3>\n"); c_uid = -1; sscanf(input_ch,"uid=%ld",&uid); /* Transform input data */ printf("Input Nuber:%ld.<BR><HR>",uid); exit(0); }
В приведенном выше примере программа получает данные через стандартный ввод. Это значит, что используется метод доступа POST. Число получаемых байтов указывается в переменной окружения CONTENT_LENGTH. Следует обратить внимание на то, что первой строкой записи в стандартный вывод является строка, определяющая тип информации. В данном случае он определен как текст HTML. Важно также отметить, что в этом операторе вывод завершается двумя переводами на новую строку, т.к. пустая строка должна разделять заголовок и тело сообщения, возвращаемого серверу. Остальные операторы выводят данные в виде HTML-предложений, формируя HTML-документ.
При написании скриптов следует учитывать то, что сервер обычно стартует в момент, когда не все пути могут быть определены, поэтому при обращении к ресурсам следует указывать полные пути для этих ресурсов.
Принципы построения и интерпретации HTML
Таговая модель описывает документ как совокупность элементов, каждый из которых окружен тагами. По своему значению таги близки к понятию скобок "begin/end" в универсальных языках программирования, которые задают области действия имен локальных переменных и т. п. Таги определяют область действия правил интерпретации текстовых элементов документа. Типичным примером такого рода является таг стиля Italic, который определяет область отображения курсива.
Программа-клиент (telnet)
Telnet - это интерфейс пользователя для работы по протоколу TELNET. Программа работает в двух режимах: в режиме командной строки (command mode) и в режиме удаленного терминала (input mode).
При работе в режиме удаленного терминала telnet позволяет работать с буферизацией (line-by-line) или без нее (character-at-a-time). При работе без буферизации каждый введенный символ немедленно отправляется на удаленную машину, откуда приходит "эхо". При буферизованном обмене введенные символы накапливаются в локальном буфере и отправляются на удаленную машину пакетом. "Эхо" в последнем случае также локальное.
Для переключения между режимом командной строки и режимом терминала используют последовательность Ctrl+], которая может быть изменена командами telnet (таблица 3.2).
Таблица 3.2, Основные команды режима командной строки telnet
| Команда | Назначение |
| open host [port] | Начать telnet-сессию с машиной host по порту port. Адрес машины можно задавать как в форме IP-адреса, так и в форме доменного адреса |
| close | Завершить telnet-сессию и вернуться в командный режим. Однако в некоторых системах, если telnet был вызван с аргументом, close приведет к завершению работы telnet |
| quit | Завершить работу telnet |
| z | "Заморозить" telnet сессию и перейти в режим интерпретатора команд локальной системы. Из этого режима можно выйти по команде Exit |
| mode type | Если значение type line, то используется буферизованный обмен данными, если character - то обмен не буферизованный |
| ? [command] help [command] | Список команд или описание конкретной команды |
| send argument | Данная команда используется для ввода команд и сигналов протокола TELNET, которые указываются в качестве аргумента. Например: send ao - посылает команду прервать выдачу на принтер NVT |
Программу telnet можно использовать не только для работы по протоколу TELNET, но и для тестирования других протоколов, например SMTP:
telnet host.domain.org 25
После установки соединения можно обмениваться командами протокола SMTP c сервером этого протокола.
В настоящее время часто доступ к удаленной машине Internet осуществляется не прямо, а через промежуточный сервер. Например, пользователь использует программу дозвона (dial-in) на персональном компьютере для доступа к Unix-машине, а затем telnet для доступа к другому компьютеру, подключенному к Internet. В этом случае также возможны несоответствия. Например, программа term90 из набора Norton Commander имеет экран не 24_80, а только 23_80. При эмуляции терминала vt100 это следует учитывать, т.к. в базе данных termcap для этого терминала определены значения 24_80. Дело в том, что при доступе по telnet две Unix-машины согласовывают свои возможности, а DOS-компьютер из этого процесса исключен. Для обеспечения правильной работы в базе данных termcap следует прописать терминал для такого доступа.
Редакторы HTML-документов
Самое простое решение проблемы создания HTML-документов - это использование простого текстового редактора, который вообще не ориентирован на разработку HTML-документов. Именно эта возможность и обеспечила первичную популярность World Wide Web. Многие ветераны до сих пор считают, что это наиболее гибкий способ разработки документов, т.к. специализированные редакторы не реализуют всех возможностей HTML или реализуют их крайне неэффективно. однако, если производство документов необходимо поставить на поток, и при этом разрабатывать их будет неискушенный в языке оператор, то подбор редактора, который автоматизирует ряд процедур разработки документа, становится актуальной задачей.
Любопытно, что большинство систем разметки гипертекстовых документов в настоящее время реализованы для персональных компьютеров с операционными системами Windows 3.x или Windows`95. Из прочих операционных сред можно выделить только IRIX, в рамках которого SGI предложила несколько типовых решений для организации как Website, так и рабочего места разработчика Website.
Все программы подготовки страниц можно разбить на следующие группы:
специализированные редакторы HTML, дополнения к существующим текстовым редакторам для расширения их возможностей, программы конверторы из/в HTML и специализированные средства разработки отдельных компонент страниц или специальных страниц (графические редакторы, мультипликаторы, аудио рекордеры и т.п.).
В последнее время стали появляться не просто коммерческие средства подготовки HTML-страниц, а завершенные программные комплексы, оптимизированные под определенную платформу, как, например, система WebMagic Author, которая входит в комплект WebForce компании Silicon Graphic. Начнем обзор средств подготовки Web-страниц c редакторов HTML. Все редакторы можно разделить на коммерческие и свободно-распространяемые, а также на обычные и WYSIWYG.
Коммерческие редакторы продаются и стоят около 100$ за одну установку. Как правило, можно скопировать редактор по Internet и пользоваться им в течении 30 дней бесплатно, а за тем уже решать вопрос о его приобретении. Готовя этот обзор, я воспользовался этой возможностью и поработал с HotDog, HotMеtal, HTMLedit Pro, HTML Writer и рядом других редакторов, для того, чтобы составить свое собственное мнение о возможностях современных средств подготовки HTML-документов, которые занимают первые места в рейтингах иностранных компьютерных журналов и в периодических опросах авторов Web-страниц. В своей повседневной работе я пользуюсь свободно-распространяемой версией HTMLed 1.2 и вполне ей доволен, но признаю, что коммерческие продукты обладают рядом неоспоримых преимуществ, особенно, с точки зрения начинающих пользователей, о чем будет сказано чуть позже. Свободно-распространяемые программы - это то, что осталось с тех времен, когда Internet не погрузилась в пучину коммерциализации ее информационных ресурсов. До сих пор существуют добрые люди, которые пишут хорошие программы и раздают их всем желающим. К сожалению их становится все меньше. Среди этих программ следует выделить HTML Writer, HTMLed 1.2e, Web Wizard 16-bit и HotMetal Free.
Магическое слово "WYSIWYG" - означает "What You See Is What You Get", т.е., "Видишь то, что получишь". С этой концепцией построения редакторов текста все пользователи персональных компьютеров знакомы по работе с MS-Word for Windows. Среди HTML-редакторов также есть WYSIWYG редакторы, например, HotDog или TkWWW.
При сравнении различных редакторов зарубежные авторы принимают в расчет обычно следующие показатели: поддержка различных стандартов языка (HTML 3, Netscape Extensions, Microsoft Extensions), наличие специальных средств разработки таблиц, форм и графических стеков гипертекстовых ссылок (imagemap), наличие программ проверки синтаксиса HTML и национальных языков, размер редактируемого файла, наличие режима WYSIWYG, и удобства разработки, в которые включают внешний вид, наличие икон, определяемые пользователем последовательности HTML тегов и т. п. Если первые показатели не вызывают никаких сомнений, то показатель удобства выглядит в этом ряду несколько странно. На мой взгляд, это все ровно, что убеждать эскимоса в том, что рыбу надо есть свежевыловленной, а не с душком. Последнее замечание я сделал только потому, что был чрезвычайно удивлен тем обстоятельством, что первой во всех рейтингах значится коммерческая версия редактора HotDog. Действительно, это очень неплохой редактор, но по количеству действительно полезных функций в тех же рейтингах он уступает, например, редактору HotMetal. Так HotDog не поддерживает контроль синтаксиса HTML, хотя официально заявлено обратное. Для реализации этой возможности требуется загружать дополнительные файлы, которые в дистрибутиве не поставляются. То, что в рейтинге Карла Девиса (Carl Davis, http://www.ccs.org/htmledit/comparetable.html) HotDog и HotMetal соседствуют, можно объяснить вкусом автора рейтинга, однако Строуд (Forrest H. Stroud, http://cws.wilmington.net/html.html) назначил HotMetal три звезды против пяти у HotDog и поставил его на десятое место в общем списке HTML-редакторов после, например, свободно распространяемого редактора HTML Writer, что объяснить объективными показателями сравнения программ просто невозможно. В вину HotMetal вменяется, то что он проверяет синтаксис HTML, а так как HTML 3.0 и другие расширения языка не поддерживаются в качестве стандарта, то редактор терроризирует пользователя предложениями о коррекции ошибок при применении новых тегов. Но если проверка столь назойлива, ее всегда можно отключить и получить обычный редактор. Поэтому я не буду делать выводы о том, что лучше или хуже, а просто постараюсь выделить общие свойства различных редакторов и проиллюстрировать эти возможности примерами.
Прежде, чем говорить о способах редактирования HTML-документов и их реализации в различных редакторах, договоримся о том, что понимается под такого рода редактированием. Создание HTML-документа - это просто набор текста и расстановка внутри него тегов языка HTML. Собственно, набор текста и расстановку тегов можно производить в обычном текстовом редакторе вручную. В этом смысле все HTML-редакторы ни чем не отличаются от MS-Write или Notepad, например. Их особенность как HTML-редакторов заключается в способности автоматизировать процесс разметки, т.е. вставки в текст документа тегов языка HTML. Практически все редакторы позволяют запускать внешнюю программу просмотра, например, Netscape, для тестирования набранного документа, а некоторые из них синхронно отображают набираемый текст и графику, демонстрируя страницу Web в том виде, как ее увидят пользователи World Wide Web на экранах своих компьютеров.
Начнем с очевидных вещей - поддержки HTML тегов и встраивания гипертекстовых ссылок. Эти возможности поддерживаются любым HTML-редактором, будь он коммерческий или свободно-распространяемый. Вся разница состоит только в том как широк этот набор. Практически, все редакторы поддерживают стандарт HTML 1.0, только очень старые редакторы, чьи коды были написаны в 1994 году, не поддерживают стандарт HTML 2.0, а вот новые стандарты и их вариации не поддерживаются многими редакторами. Так HTML 3.0 и Netscape Extensions не поддерживают HTML Assistant, HTMLed, HTML Writer, TkWWW, Phoenix и многие другие. Правда, следует заметить, что это не такая уж и большая беда. В понятие поддержки возможностей того или иного стандарта языка, обычно, вкладывается наличие специальных позиций в меню редактора, выбирая которые, можно вставлять в текст соответствующие теги. Многие редакторы позволяют организовывать пользовательские списки тегов, а это значит, что автор сам может расширить возможности своего редактора. С гипертекстовыми ссылками ситуация такая же как и с тегами. Авторы обзоров часто относят к достоинству редактора наличие списка ссылок на наиболее популярные страницы Web, который поставляется вместе с программой. Это конечно удобно. Но если автор давно работает с "паутиной", и круг его профессиональных интересов определился, то существуют еще две возможности создания таких списков: конвертирование в формат редактора списка закладок программы просмотра, которой пользуется автор, или свой собственный список, который накопился за время разработки страниц Web. Даже свободно-распространяемая версия HTMLed 1.2e позволяет реализовать оба способа. Графика вставляется в документы аналогично гипертекстовым ссылкам, поэтому отдельно на ее использовании в качестве элемента HTML-разметки останавливаться не будем.
Следующим важным свойством гипертекстовой разметки является разметка таблиц. Таблица довольно сложный объект и от автора требуется достаточно высокая квалификация, чтобы ее реализовать в HTML-документе. Важность таблиц во многом определяется тем, что кроме использования их как собственно таблиц, многие авторы организуют с их помощью многоколоночную разметку, блочную разметку, позиционирование графики относительно текста и ряд других эффектов, которые обычными средствами языка сделать трудно. Для примера можно посмотреть домашние страницы компании Demos (http://www.demos.su/), чтобы убедится насколько эффективным может быть использование таблиц. Свободно-распространяемые редакторы разметку таблиц не поддерживают, поэтому следует обратится к коммерческим продуктам. Честно говоря, ничего подобного, скажем, таблицам MS-Word ни в одном из HTML-редакторов нет. Правда здесь надо оговориться, что проверить системы типа WebForce у меня возможности не было, а описание WebMagic Author на домашних страницах Silicon Graphic Inc. представления о реализации поддержки таблиц в этой программе не дает. В других же редакторах поддержка таблиц подразумевает вставку в текст документа-шаблона, состоящего из тегов элементов таблицы, которые потом надо заполнять вручную. Если таблица маленькая или ее элементы небольшие, то вся ее структура хорошо видна на экране, и работать с ней достаточно удобно, но если надо организовать многоколоночный текст, то наглядность мишени, которую выдал редактор быстро теряется, создание таблицы с использованием средств редактора практически не отличается от ручной разметки.
Кроме таблиц важнейшим элементом интерактивных страниц Web являются страницы с формами. Тестируя коммерческие продукты, я ожидал увидеть возможность интерактивного программирования формы, как это давно принято в системах управления базами данных, и с чем впервые познакомился еще при работе с ADABAS NATURAL. Однако ни один из первой пятерки лучших редакторов World Wide Web такой возможностью на настоящий момент не обладает. Все, что можно реально получить - это отдельные элементы формы, которые вставляются в текст документа при выборе соответствующей позиции меню.
Теперь настало время поговорить о возможностях WYSIWYG редактирования. Первым редактором этого типа была программа TkWWW. Она совмещала в себе сразу и редактор и программу просмотра. Таковой она осталась до сих пор. TkWWW исповедует принцип "Что видишь, то и будет" в классическом смысле этого слова, т.е. так как это делает MS-Word. При наборе текст HTML-документа сразу отображается так, как будто его просматривают программой Mosaic. Но как только необходимо вставить картинку, так сразу становится понятным, что программа не способна в режиме редактирования документа вставлять в него графику. Все картинки заменяются на текст IMAGE, не говоря уже о таблицах и формах. Вообще говоря, классический WYSIWYG не типичен для HTML-редакторов. Обычно программы открывают дополнительное окно, в котором и отображается результат интерпретации HTML-документа, который в данный момент редактируется. Таким образом на экране одновременно отображаются исходный текст документа, в который автор вносит изменения и его образ после интерпретации программой просмотра. При чем интерпретация происходит синхронно, т.е. при наборе символов в рабочем окне они немедленно появляются в окне отображения. То же самое происходит и с графикой, и с другими элементами документа. Однако, применяя такие встроенные в редактор программы просмотра, всегда следует помнить о том, что другие программы Web, могут отображать документ несколько иначе. Для того, чтобы быть уверенным что 85% всех пользователей Web увидят документ в том же виде, как его видит автор, следует всегда обращаться к услугам внешней программы просмотра, а именно Netscape Navigator. Практически все редакторы эту возможность поддерживают.
Если рассматривать HTML-редактор не только как средство подготовки страниц Web квалифицированным автором, но еще и как средство обучения персонала, то единственным редактором, который полностью поддерживает не только описание себя самого, но и описание различных стандартов языка и приемов разработки страниц является HotDog. В интерактивном руководстве по этому редактору есть не только подробное описание HTML 2.0, HTML 3.0, Netscape Extensions для HTML 2.0 и предложения Netscape в стандарт HTML 3.0, но и описание Microsoft Extensions. Надо отметить, что эти описания составлены гораздо понятнее, чем описания самих разработчиков. Так, например, описание автоматического обновления документов с использованием механизма Refresh, который реализуется не сервером, а документом через конструкцию <META HTTP-EQUIV="Refresh" ...> в контейнере HEAD документа, сопровождается достаточно ясными примерами, и гораздо прозрачнее для понимания описания этой возможности на домашних страницах Netscape Communication, которая придумала и реализовала эту конструкцию в своей программе просмотра.
Рассматривая различные HTML-редакторы, нельзя не обратить внимание, что подавляющее большинство их разработано для Microsoft Windows. Так один из наиболее представительных списков HTML который опубликован в руководстве "THE WEB DESIGNER", насчитывает 40 редакторов для Windows, 26 - для Macintosh, 28 для всех остальных платформ, в том числе 16 для X-Window. Коммерческая информационная служба Yahoo поддерживает отдельный список HTML-редакторов для Windows. В принципе, эта тенденция понятна. Администраторы серверов, среди которых подавляющее большинство составляют Unix рабочие станции, вообще не используют HTML редакторы, а обходятся обычными текстовыми. Число специализированных рабочих мест типа WebForce еще невелико, да и затраты на полный комплект, включающий рабочую станцию Indy и программное обеспечение, не сравнимы с затратами на персональный компьютер. Таким образом, если и нужно какое-либо специализированное программное обеспечение для разработки Web-страниц широкими слоями общественности Internet, то его место на персональном компьютере с Windows. В связи с этим интересно отметить еще одну тенденцию, которая связана с внедрением операционной системы Windows-95. Многие специалисты на западе наперебой обсуждают внедрение в Netscape Navigator возможностей интерпретатора языка Java, которое по их мнению произведет новую революцию в технологии World Wide Web. Может быть так оно и будет, но разработка страниц, содержащих Java applets - мобильный код языка Java, не такое простое дело, как набор текстовых документов и требует навыков настоящего программирования. В этом свете разработка Microsoft Extensions, в частности BGSOUND, выглядит хоть робкой, но очевидной попыткой дать более простые средства разработки мультимедийных страниц, чем это возможно при использовании Java. Netscape в настоящее время - лидер не только разработки программ просмотра страниц Web, но и законодатель моды в разработке самого языка HTML. Собственно, последнее обстоятельство и определяет лидерство Netscape в разработке программ. Но эта ситуация будет продолжаться только до тех пор, пока язык не сложился. Как только HTML перестанет меняться со скоростью 50% новых тегов в год, у Microsoft появится реальная возможность вытеснить Netscape c платформ, которые используют ее операционные системы. Пока же, то что поставляется с Windows-95 скорее прототип, чем промышленная программа.
На этом можно было бы и поставить точку в нашем обзоре специализированных HTML-редакторов, но мы рассматриваем эти программы с точки зрения разработчика HTML-страниц, и в этом случае наш обзор будет несколько односторонним. Дело в том, что содержание документа интерпретируется не только программой просмотра страницы. В настоящее время довольно большой объем работы выполняется сервером. И здесь мы сталкиваемся с характерной для архитектуры "клиент-сервер" проблемой, которая коротко характеризуется сочетанием "толстый и тонкий". В настоящее время явно доминирует тенденция сделать "толстым" клиента. Собственно все расширения HTML направлены на внедрение новых возможностей, которые должен реализовывать клиент. Но к чему это приводит, видно по тем же редакторам HTML документов. Например, работа с лучшим из них, HotDog, в режиме WYSIWYG на PC486/100 с 16Mb оперативной памяти выглядит крайне непривлекательно. Обновление документа в контрольном окне явно не успевает за изменениями в окне редактирования и просто тормозит весь процесс подготовки документа. Реально, приходится набирать документ вслепую. Тот же эффект наблюдается и у HotMetal, и у <Live Markup>. Да это и не удивительно, если размер HotMetal, например, превышает 2Mb. Отключение режима WYSIWYG не решает этой проблемы - размер Netscape или Mosaic, которые можно использовать для тестирования страниц, также находятся около магической цифры 2Mb. Таким образом для разработки Web-страниц требуется машина, сравнимая по своим возможностям с той, на которую ставится сервер HTTP. В этом случае совершенно логичным является включение сервера в комплект инструментов разработки страниц Web. Если рассматривать эту проблему с другой точки зрения, то появления тагов типа BANNER или фреймов - это прямая альтернатива вставкам, которые осуществляет сервер в процессе подготовки документов (server site includes). В данном случае я рассматриваю фреймы только в этом смысле, хотя у этой конструкции языка есть множество других полезных применений. Но если сервер делает свою работу, не нагружая сети, то все выше указанные расширения языка только увеличивают трафик. Кроме того, используя обычный редактор, нельзя проверить работу через формы со скриптами CGI и стеками гипертекстовых ссылок - image-map. Поэтому, некоторые фирмы предлагают в своих комплектах не только средства редактирования документов, но и серверы, например, Hype IT 1000, FrontPage, WebForce. Вообще, с появлением возможности динамического обновления страниц как со стороны сервера, так и со стороны клиента, делает такие связки достаточно эффективными. Это тот же принцип WYSIWYG, но не модельный как в HotDog с использованием специальных компонентов, а реальный, где применяется настоящий сервер и настоящий клиент. При этом в качестве средства набора страниц можно использовать любой HTML-редактор. При изучении документации по HTML, может сложиться впечатление, что HTML развиваются только путем добавления новых контейнеров, которые должны интерпретироваться клиентом. Это не так. В настоящее время, многие серверы стали поддерживать очень похожие возможности предварительной обработки документов перед их отсылкой клиенту. Если год назад, реально, это были только вставки, то теперь этот набор расширен до условных вставок и условной генерации. Некоторые разработчики пошли еще дальше и стали внедрять в HTML таги, которые интерпретируются только сервером. Типичным примером может служить HtmlScript. Отличие этого подхода в том, что если раньше предварительная обработка базировалась только на использовании комментариев HTML, то в HtmlScript язык дополнен новыми контейнерами, которые позволяют манипулировать содержанием документа-макета, который в результате этих манипуляций "на лету" превращается в обычный HTML-документ перед отправкой программе просмотра. Для подготовки такого сорта документов пока вообще нет специальных средств.
И последнее, о чем хочется сказать, - это о стиле подготовки документа. До сих пор для этой цели используется обычный набор текста, который производится в той же манере, что и в обычном текстовом редакторе. Но еще на заре гипертекстовых систем, многие теоретики говорили о том, что для нелинейного текста следует применять и нелинейные процедуры его подготовки. Кажется, что некоторые разработчики HTML-редакторов наконец прониклись этой идеей и решили создать нечто, что отличалось бы от обычного редактора. Первой ласточкой этого направления можно считать программу InContext Spider. Концепция этой программы достаточно прозрачна, но непривычна. В ее основу положен принцип визуализации контейнеров HTML и их связей между друг другом. Контейнеры помечаются соответствующими иконками и автор может работать с каждым контейнером независимо от других. Для их взаимосвязи контейнеров используются деревья, сети и т.п. Такой стиль работ похож на разработку встроенных в текст картинок в Word 6.0 for Windows.
Во-первых, - это обзор "HTML EDITORS" (Forrest H.Stroud, http://cws.wilmington.net/ html.html), во-вторых, руководство "THE WEB DESIGNER" (N.Laviolette, http:// www.kosone.com/people/nelsonl.nl.html, в-третьих "HTML Editor Reviews" (Carl Davis, http://www.ccs.org/htmledit/). На этих страницах можно найти обширные списки редакторов с их кратким описанием и оценками авторов обзоров. Надеюсь, что эта информация поможет читателям в их повседневной работе.
Схемы адресации ресурсов Internet
В RFC-1630 рассмотрено 8 схем адресации ресурсов Internet и указаны две, синтаксис которых находится в стадии обсуждения.
Запись "Start Of Authority"
Перейдем теперь к описанию форматов записей описания ресурсов. Такое описание по традиции начинают с записи SOA (Start Of Authority). Запись SOA отмечает начало описания зоны. Обычно, это первая запись описания зоны. Некоторые авторы, в частности, упоминавшийся ранее Kavli, рекомендуют наличие одной и только одной записи типа SOA в каждом файле, который указан в записи primary файла named.boot.
Формат записи SOA можно представить как:
[zone] [ttl] IN SOA origin contact ( serial refresh retry expire minimum )
В этой записи каждое из полей обозначает следующее:
Поле zone - имя зоны. Если речь идет о зоне, описанной в записи primary файла named.boot, то в качестве имени употребляется символ коммерческого эй - "@". В этом случае в качестве имени текущей зоны берется имя, указанное в качестве первого аргумента команды primary из файла named.boot. Поле зоны обязательно должно быть указано. Иначе named не сможет привязать следующие за данной записью описания к имени зоны. Пустое имя зоны не является допустимым.
Поле ttl в записи SOA всегда пустое. Дело в том, что время кэширования для записей описания зоны задается последним аргументом данных записи SOA.
Поле origin - это доменное имя primary сервера зоны. В случае описания зоны vega.ru в качестве сервера используется машина vega-gw.vega.ru. Данное доменное имя и должно быть указано в поле origin. Очень часто в этом поле можно встретить имена, которые начинаются с "ns", например, ns.kiae.su или ns.relarn.ru. В данном случае это означает только то, в данных зонах существуют машины с именем "ns", и на них размещены primary серверы этих зон. Никакого специального зарезервированного имени для указания в поле origin нет. Использование, указанных выше имен обосновано тем, что их просто легче запомнить, т.к. "ns" означает "name server".
Поле contact определяет почтовый адрес лица, осуществляющего администрирование зоны. Данный адрес должен совпадать со значением адреса указанным в заявке на домен в поле "zone-c:". Есть, однако, одна особенность при указании этого адреса. Так как символ "@" имеет особый смысл при описании зоны, то вместо этого символа в почтовом адресе используется символ ".". Например, если ваш покорный слуга выступает администратором домена, то в поле contact следует писать не paul@kiae.su, а paul.kiae.su. Если в имени пользователя есть какие-либо особые символы, имеющие специальные значения при описании зоны, то они должны маскироваться символом обратного слэша - "\". Типичный пример - почтовый адрес типа user.name@kuku.ru. В этом случае точку следует замаскировать и написать в поле contact: user\.name.kuku.ru. Поступая таким образом мы исключили особое значение точки как разделителя поддоменов и обеспечили интерпретацию имени как единой символьной строки.
Поле данных в записи SOA разбито на аргументы, которые определяют порядок работы сервера с записями описания зоны. Как правило все аргументы располагают на другой строке или, для лучшего отображения каждый на своей строке, что заставляет записывать их внутри скобок.
Атрибут serial - определяет серийный номер файла зоны. Если говорить проще, то в этом поле ведется учет изменений файла описания зоны. Поле может состоять из восьми десятичных цифр. В принципе это могут быть любые числа, но чаще всего администраторы используют в качестве серийного номера год, месяц и день внесения изменений в файл описания зоны. Честно говоря, я предпочитаю просто порядковые имена. Во-первых, не будет проблемы 2000 года, о которой так много сейчас говорят, а во-вторых, в данный момент наша сеть довольно интенсивно растет, что заставляет делать изменения по нескольку раз на дню. Простое увеличение номера решает все эти проблемы. Важность серийного номера определяется тем, что когда вторичный (secondary) сервер обращается к первичному (primary) серверу для обновления информации о зоне, то он сравнивает серийный номер из своего кэша с серийным номером из базы данных первичного сервера. Если серийный номер из primary сервер больше, то secondary сервер обращается к primary и копирует описание всей зоны целиком, если нет, то он не вносит изменений в свою базу данных. Таким образом, когда производятся изменения в базе данных primary сервера, то значение атрибута serial в поле данных записи SOA для зоны, описание которой было изменено, должно быть увеличено. Неизменение номера - это типичная ошибка, на которой автор не раз себя ловил.
Атрибут refresh определяет интервал времени после которого secondary сервер обязан обратиться к primary серверу с запросом на верификацию своего описания зоны. Как уже ранее было сказано при этом проверяется серийный номер описания зоны. Описание зоны загружается secondary сервером каждый раз когда он стартует или перегружается. Однако, при стабильной работе может пройти достаточно большой интервал времени, пока эти события не произойдут в действительности. Кроме того, большинство систем, которые поддерживают сервис доменных имен, работают круглосуточно. Следовательно, необходим механизм синхронизации баз данных primary и secondary серверов. Поле refresh задает интервал после которого эта синхронизация автоматически выполняется. Длительность интервала указывается в секундах. В поле refresh можно указать до восьми цифр. Указание маленькой цифры приведет к неоправданной загрузке сети, ведь в большинстве случае описание зон довольно стабильно, но в ряде случаев, когда зона только организуется, можно указать и небольшой интервал. Наиболее типичным является синхронизация состояния описания зон один (86400) - два (43200) раза в сутки.
Атрибут retry начинает играть роль тогда, когда primary сервер по какой-либо причине не способен удовлетворить запрос secondary сервера за время определенное атрибутом refresh. А точнее, в момент наступления времени синхронизации описания зоны, primary сервер не отвечает на запросы secondary сервера. Атрибут retry определяет интервал времени после которого secondary сервер должен повторить попытку синхронизовать описание зоны с primary сервером. Значение этого атрибута также может состоять максимум из восьми цифр. При установке этого значения во внимание следует принимать несколько факторов. Во-первых, если primary сервер не отвечает, то, скорее всего произошло что-то серьезное (отделочники вырезали часть сети, т.к. мешала красить стены, экскаватор перекопал магистраль или отключили питание в сети). Такая причина не может быть быстро устранена, поэтому установка слишком малого времени опроса просто зря нагружает сеть. Во-вторых, если на primary сервер прописано много зон, и он обслуживает большое количество запросов, то он может просто не успеть ответить на запрос, а очень частые запросы от secondary сервера просто "подливают масло в огонь" ухудшая и так медленную работу сервера. Обычно значение этого атрибута устанавливают равным одному часу (3600).
Атрибут expire определяет интервал времени, после которого secondary должен прекратить обслуживание запросов к зоне, если он не смог в течении этого времени верифицировать описание зоны, используя информацию с primary сервера. Обычно это интервал делают достаточно большим, скажем полтора месяца (3888000). Если сделать маленький интервал, то какой смысл в secondary сервере, если он скоропостижно скончается после отключения primary сервера. В течении всего этого времени secondary сервер будет пытаться установить контакт c primary сервером и обслуживать запросы к зоне. Правда все эти соображения хороши для случая, когда просто отключится или ломается машина, на которой стоит primary сервер. Если же отключится вся сеть, которая описана в зоне, а для большинства организаций так оно и есть, то secondary сервер становится подобным космическому аппарату "Пионер", который путешествует во Вселенной, давно потеряв всякую связь с Землей.
Последний атрибут из поля данных записи SOA - minimum. Он определяет время хранения записи описания ресурса в кэше удаленной машины, т.е. значение поля ttl по умолчанию для всех записей описания зоны. Именно по этой причине поле ttl в записи SOA остается пустым. Данное поле влияет на то, как часто удаленные серверы будут обращаться к серверу описания зоны за информацией. Хорошим тоном считается установка значения в этом поле не меньше, чем значения в поле expire. Иногда указывают вообще максимально возможное значение - 99999999. Маленькое значение будет приводить к непроизводительной загрузке сети - ведь соответствия межу IP-адресами меняются очень редко.
Обратите внимание на то, что все атрибуты записи SOA определяют порядок взаимодействия primary сервера и secondary серверов. Исключение составляет только атрибут minimum. В данном случае речь идет о кэшировании адресов не сервером, а системой resolver. Однако, в большинстве случаев эта разница не проявляется. Дело в том, что в качестве resolver на локальной вычислительной установке выступают функции из стандартной библиотеки, которые направляют запросы к локальному серверу доменных имен и сами не осуществляют кэширования соответствий между именами и IP-адресами. В этом случае кэширование осуществляется локальным сервером доменных имен. В том случае когда на машине запускается свой кэширующий сервер, который не описывает никакой зоны, а используется только для обслуживания запросов к сервису доменных имен, именно он и является той частью resolver, которая кэширует соответствия.
Таким образом, когда речь идет об атрибуте minimum, то чаще всего его описывают в контексте программы named, которая может использоваться не только как primary или secondary сервер, но и как кэширующий сервер. В этом случае поле ttl записи описания ресурса и атрибут minimum задают время хранения записи описания ресурса в кэше.
Приведем пример записи типа SOA:
@ IN SOA vega-gw.vega.ru paul.kiae.su ( 101 ; serial number 86400 ; refresh within a day 3600 ; retry every hour 3888000 ; expire after 45 days 99999999 ) ; default ttl is set to maximum value
В данном примере имя зоны берется из записи primary файла named.boot, поэтому в поле имени зоны указан символ "@". В качестве сервера для зоны используется машина с именем vega-gw.vega.ru. Почтовый адрес ответственного за зону - paul@kiae.su. Открывающаяся скобка говорит о том, что описание записи SOA будет продолжено на следующих строках. Каждая из последующих строк описывает один атрибут из поля данных записи SOA. При этом обратите внимание на то, что символ ";" маскирует весь остаток строки для интерпретации программой named, т.е. комментарий начинается с символа ";" и заканчивается символом перехода на новую строку. Атрибут serial определяет данную 101-ю версию описания зоны, атрибут refresh устанавливает периодичность опроса primary сервера secondary сервером как один раз в сутки, в случае неудачи secondary сервер начинает опрашивать primary сервер каждый час и, если восстановить взаимодействие не удается, то через 45 дней secondary сервер перестает обслуживать запросы к данной зоне. Информация о соответствии доменных имен IP-адресам должна храниться в кэше resolver или удаленного сервера максимально возможное время.
Делегирование поддомена внутри домена
Рассмотрим последний пример - делегирование поддомена внутри домена. Данная ситуация возникает в том случае, когда организация растет и обслуживание всего домена становится довольно трудоемкой задачей. Собственно, проблема возникает как с администрированием - слишком много машин и пользователей, так и со скоростью ответа на запросы - слишком много запросов к одному серверу, что плохо сказывается на его реактивности.
При делегировании домена определяется машина, на которой будет установлен primary сервер для нового поддомена, определяется место размещения secondary сервера и делаются соответствующие изменения в файле настроек primary сервера вышестоящего домена.
Рассмотрим такое делегирование на следующем примере: в домене kiae.su делегируется зона kiae.su. Пример описания этой зоны мы рассматривали в предыдущем примере. Поэтому в данном примере мы рассмотрим только описание зоны kiae.su и только записи касающиеся поддомена polyn.kiae.su, т.к. полное описание домена будет занимать 23 страницы.
Пример делегирования зоны:
$ORIGIN su. kiae IN SOA ns.kiae.su. noc.relcom.eu.net. ( 3000302 28800 3600 3600000 86400 ) IN NS ns.kiae.su. ; List of NS records and MX records for domen kiae.su. ...... $ORIGIN kiae.su. hytelnet IN A 193.125.152.10 gopher IN A 193.125.152.10 archie IN A 193.125.152.10 $ORIGIN net.kiae.su. polyn IN A 144.206.130.137 IN A 144.206.160.32 ; Other records ... polyn IN NS polyn.net.kiae.su. ; The rest of the description of the descriptionkiae.su zone. .....
В данном примере следует обратить внимание на следующие особенности описания. Во-первых, при описании сервисов hytelnet, goher и archie не используется записи типа CNAME. Для всех этих доменных имен указан один и тот же IP-адрес. Во-второых, при описании делегированной зоны сначала указана запись типа A для машины polyn.net.kiae.su. Это primary сервер зоны polyn.kiae.su. Для этой же зоны могут быть также указаны и secondary серверы данной зоны. Как видно из описания машины polyn.net.kiae.su, ей соответствует два IP-адреса. В данном случае это не адреса синонимы на одном и том же порте, а адреса разных интерфейсов данной машины, т.к. она является шлюзом локальной подсети.
Приведенного выше описания достаточно для того, чтобы при помощи нерекурсивных опросов серверов, resolver или сервер нашли нужный IP-адрес.
"Обратная" зона прописывается точно также. Это значит, что зона 160.206.144.in-addr.arpa должна быть прописана в зоне 206.144.in-addr.arpa. Термин "прописать" означает выполнение следующих операций: в зоне должна быть определена подзона и машина-сервер этой подзоны, т.е. указана "приклеенная" запись для этой машины, в зоне должна быть указана запись типа NS для выделяемой подзоны.
В домене vega.ru сервер зоны определялся в самой зоне vega.ru, в случае с зоной polyn.kiae.su, сервер расположен в другом домене - net.kiae.su. Однако это не мешает управлять зоной. В принципе, используя команды $ORIGIN можно опредлить зоны внутри домена и в том же файле, что и описание самого домена. Собственно в нашем примере так оно и сделано: домен net.kiae.su определен в файле описания домена kiae.su.
Теперь от примеров описания зон перейдем к средствам контроля за размещенными зонами.
Графические редакторы и их особенности
Главное особенностью графических редакторов является требование поддержки форматов GIF87, GIF89A и JPEG. Такое требование определяется тем, что только эти форматы поддерживаются программами клиентами World Wide Web, точнее большинством программ просмотра Website. Такие программы как Netscape Navigator и Internet Explorer позволяют просматривать картинки этих форматов внутри документов или как самостоятельные страницы Website.
Коммерческими программами, которые поставляются вместе со сканерами (обычно это Foto-Shop различных версий, продукты Adobe различных версий и др.) данные форматы поддерживаются. Единственным исключением является многокадровый GIF89A, для которого необходима отдельная программа подготовки документов.
Из свободно распространяемых программ наиболее популярны Lview (Windows), как коммерческая версия так и рекламная бета-версия, и X-Paint (X-Window). Если говорить более точно, то Lview - это интерактивный конвертор графических файлов из одного формата в другие.
Рис. 3.32. Графический конвертор Lview
Lview способен преобразовывать графические фалы из/в форматы: JPEG, BMP, GIF78A, GOF89A, TARGA, PCX, PPM, TIFF.
Программа X-PAINT для X-Window - это полноценный графический редактор, который способен сохранять документы в форматах GIF и JPEG. Его также довольно часто используют для конвертирования файлов из формата PCX.
В последнее время довольно широко при разработке страниц стали применяться многокадровые графические файлы формата GIF89A. Большинство небольших движущихся картинок в World Wide Web реализованы именно в этом стандарте, а не в виде Java-applet'ов. Принцип разработки таких объектов тот же, что и при производстве мультфильмов. Сначала создают последовательность из нескольких картинок, а потом их объединяют в единый файл. В заголовке файла содержаться правила его просмотра: число кадров, промежутки между кадрами и команды начала и остановки просмотра.
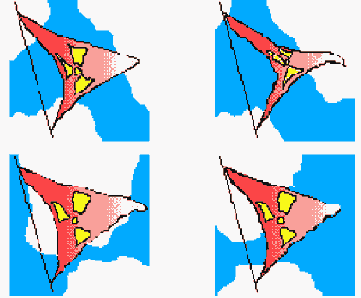
Рис. 3.33. Пример создания файла формата GIF89A
После того, как такая картинка вставлена в текст HTML-документа, она может быть отображена в виде небольшого мультфильма программой просмотра страниц World Wide Web. Такие программы просмотра как Netscape Navigator и Internet Explorer прекрасно отображают эти картинки. Если программа-клиент не способна отобразить файл формата GIF89A, то тогда просто отображается первый кадр. Так поступают, например, такие программы как Arena и Chimera.
Составление документа из нескольких файлов основано на механизме подстановок (server site includes), которые сервер осуществляет перед отправкой указанных в запросе клиента данных. Требование на подстановку включается в тело документа в виде строки комментария.
Ответ сервера
Ответ сервера может быть, как и запрос, упрощенным или полным. При упрощенном ответе сервер возвращает только тело ресурса (например, текст HTML-документа). При полном ответе клиенту возвращается строка состояния (Status-Line), общий заголовок, заголовок ответа, заголовок ресурса и тело ресурса. В форме Бекуса-Наура полный ответ представляется следующим образом:
<Полный ответ> := <Строка состояния> (<Общий заголовок>|<Заголовок ответа>|<Заголовок ресурса>) <символ новой строки>[<тело ресурса>]
Строка состояния состоит из версии протокола, кода возврата и краткого описания этого кода. Например, она может выглядеть так:
"HTTP/1.0 200 Success".
Заголовок ответа сервера может состоять из адреса URI запрашиваемого ресурса, и/или наименования программы сервера, и/или кода идентификации для работы в защищенном режиме. Состав полей заголовка ресурса является общим и для запроса клиента и для ответа сервера, и состоит из разрешения на метод доступа, типа кодировки тела ресурса (содержания ресурса), длины тела ресурса, типа ресурса, время действия данной копии ресурса, времени последнего изменения ресурса и расширения заголовка.
Рассмотрим более подробно поля заголовка, обращая внимание на реальное применение каждого из них и возможность проявления ошибок при обработке этих полей разными программами (серверами и клиентами).
Если в заголовке ответа сервера указано предложение Location, то это значит, что требуемый ресурс находится по другому адресу и его надо запросить заново. Такая процедура называется перенаправлением. Перенаправление в заголовке будет выглядеть как:
Location: http://apollo.polyn.kiae.su/risk/riskform.html
Имя и версия сервера указываются в поле Server. При использовании сервера Церн данное поле будет выглядеть как:
Server: CERN/3.0 libwww/2.17
В заголовке может встречаться и поле контроля доступа WWW-Authenticate, которое определяет способ доступа к закрытым ресурсам. Например, это поле может выглядеть как: WWW-Athenticate: Basic realm="WallyWorld"
Кроме рассмотренных выше полей, в заголовке могут встретиться и другие поля, которые определяют содержание тела передаваемого ресурса. Эти поля относятся к заголовку ресурса, но в ответе сервера они встречаются вперемешку с общими полями. Поле Allow определяет разрешенные методы доступа к ресурсу:
Allow: GET,HEAD
Поле Сontent-Encoding определяет тип кодирования передаваемого ресурса:
Content-Encoding: x-gzip
В данном случае указывается, что ресурс является заархивированным файлом в формате zip. Обычно ресурсы хранятся в виде, указанном в данном поле, и при их получении клиент должен обеспечить их преобразование в приемлемый для отображения вид. Это своего рода предобработка данных, которая базируется обычно на MIME типах. В машинах, где недостаточно памяти на видео-адаптерах, используют предобработку для преобразования изображений в приемлемый для отображения вид. Так, например, для персональных компьютеров с 512 КБ памяти на видеоадаптере используют предобработку для преобразования 256-цветных картинок в 16-цветные. Если этого не делать, то можно наблюдать интересный эффект: в Unix-системах при работе с программами Chimera и Mosaic 256-цветные картинки удваиваются, т.е. вместо одной на экране отображаются последовательно две картинки. Это связано с тем, что для 256 цветов нужно ровно в два раза больше памяти, чем для 16. Для того, чтобы избежать двойного отображения встроенных в текст картинок, их следует преобразовать.
Другим полем, которое проявляет себя при работе в сети, порождая ошибки отображения ранними версиями программ просмотра или ранним версиями программ серверов, является поле Content-Length. Поле Content-Length указывает размер (количество байтов) передаваемого ресурса. Это поле указывается как клиентом при работе по методу POST, так и сервером при ответе на запросы клиентов. При этом в ранних версиях программ-серверов может порождаться ошибка, вызванная возможностью вставки сервером некоторой информации в текст ресурса. Например, сервер NCSA (1.3) позволяет вставлять в текст HTML-документов фрагменты текста из других файлов при помощи выражения типа:
<!--#includes virtual="/include/commonheader.html" -->
В данном случае речь идет об общей заставке для всех документов некоторого раздела. На сервере в директории документов хранится файл одного размера, но после выполнения подстановки размер файла увеличивается, однако, сервер сообщает клиенту старый размер файла. Новые программы-клиенты (Netscape, Mosaic) неправильно обрабатывают такой ответ и информация не отображается.
Поле Content-Type определяет тип информации, передаваемой сервером. Наиболее часто используются типы text/play - простой тест и text/html - документ в формате HTML. Для сокращения трафика по сети существует несколько полей, связанных со временем передачи информации и периодичностью ее изменения на серверах. Поле Date определяет время отправки сообщения. Информация из данного поля сохраняется в файле статистики сервера и может быть использована для анализа доступа к ресурсам сервера из сети.
Поле Expires определяет время годности ресурса для использования. Если время использования вышло, то ресурс не должен передаваться. Точнее, его не следует передавать и принимать. О поле if-Modified-Sience уже упоминалось. Оно предназначено для того, чтобы не передавать имеющиеся у клиента копии ресурса, если не были произведены его изменения. Поле Pragma используется при передаче сообщений с сервера на сервер. Реально известно только одно значение данного поля: no-cache, которое запрещает запоминать в буфере данные для последующего использования.
Поле Referer используется для того, чтобы указать, из какого ресурса была осуществлена ссылка на ресурс. Данное поле - это мечта любого администратора базы данных сети. При помощи информации из этого поля можно определить, в каких WWW-страницах прописан конкретный сервер. От этого зависит количество обращений к серверу, "качество" пользователей, время отклика на информацию, размещаемую на сервере. При необходимости можно связаться с администратором этого сервера и уведомить его об изменениях на вашем сервере.
Поле типа кодирования почтового сообщения (Content-Transfer-Encoding)
Многие данные передаются по почте в их исходном виде. Это могут быть 7bit символы, 8bit символы, 64base символы и т.п. Однако, при работе в разнородных почтовых средах необходимо определить механизм их представления в стандартном виде - US-ASCII. Для этого существуют процедуры кодирования такого сорта данных. Наиболее широко применяемая - uuencode. Для того, чтобы при получении данные были бы правильно распакованы, в стандарт введено поле "Сontent-Transfer-Encoding". Синтаксис этого поля следующий:
Content-Transfer-Encoding := "BASE64" / "QUOTED-PRINTABLE" / "8BIT" / "7BIT" / "BINARY" / x-token
Каждая из альтернатив применяется в своем подходящем случае. Альтернативы "8bit", "7bit", "BI-NARY" реально никакого преобразования не требуют, так как почта передается байтами и SMTP не делает различия между ними. Однако они введены для строгости описания типов. "BASE64" обычно используется в связке с типом "text/ISO-8859-1". Элемент "x-token" позволяет пользователю описать свою процедуру преобразования.
Запись "Name Server"
Запись NS используется для обозначения сервера, который поддерживает описание зоны. Эта запись позволяет делегировать поддомены, поддерживая тем самым иерархию доменов системы доменных имен Internet. Для того, чтобы домен был виден в сети в зоне описания домена старшего уровня должна быть указана запись типа NS для этого поддомена. Формат записи NS можно записать в виде:
[domain][ttl] IN NS [server]
В поле domain указывается имя домена, для которого сервер, указанный последним аргументом записи NS поддерживает описание зоны. Значение поля ttl обычно оставляют пустым, тем самым заставляя named устанавливать значение по умолчанию (поле minimum из записи SOA для данной зоны). При указании имени сервера следует иметь в виду следующие обстоятельства: если в качестве сервера указывается сервер из текущей зоны, то можно обойтись только именем машины, не указывая полное доменное имя этого компьютера, т.к. имя может быть расширено именем домена, но это скорее исключение, чем правило. В записях NS указываются как primary, так и secondary серверы. Последние же скорее всего принадлежат другим зонам, и для них следует указывать полное доменное имя сервера с указанием имени машины и имени зоны. Например, для сервера из домена polyn.kiae.su c именем ns следует писать полностью ns.polyn.kiae.su. Для того, чтобы придерживаться какого-то единого стиля и во избежание ошибок рекомендуется писать всегда полное имя сервера.
Приведем пример записи описывающей делегирование поддомена:
$ORIGIN vega.ru. zone1 IN NS ns.zone1.vega.ru.
В данном примере в качестве первой строки используется команда $ORIGIN, которая определяет имя текущей зоны. Об этой команде поговорим несколько позже. Здесь она введена только для того, чтобы определить текущую зону. В поле имени зоны указано имя zone1 без точки на конце. В данном контексте это означает делегирование зоны в домене vega.ru, полное имя которой будет zone1.vega.ru. В качестве имени сервера, который управляет делегированной зоной указано имя ns.zone.vega.ru, т.е. полное имя машины в делегированном домене. В принципе, в данном случае можно было бы написать и по другому:
$ORIGIN vega.ru. zone1 IN NS ns.zone1
т.к. имя принадлежит текущему домену и может быть расширено его именем.
Адресная запись "Address"
Основное назначение адресной записи - установить соответствие между доменным именем машины и IP-адресом. В принципе для разных имен можно установить один и тот же адрес. Адресная запись - это основа файла описания "прямой" зоны. Запись имеет следующий формат:
[host][ttl] IN A [address]
Поле host определяет доменное имя машины. Чаще всего это имя указывается относительно имени текущей зоны, поэтому на конце имени не проставляется символ ".". Если же надо описать машину из другой зоны, то следует указать ее полное доменное имя и не забыть в конце этого имени символ ".". Например, "quest.polyn.kiae.su.", указанное в поле host ссылается на машину с именем quest.polyn.kiae.su. Поле ttl обычно оставляют пустым, а в поле address указывают IP-адрес машины. В этом адресе точку на конце ставить не надо. При делегировании доменов и в самом начале описания зоны возникает проблема описания серверов, поддерживающих базы данных описания зоны и поддоменов. Ведь реально при маршрутизации пакетов по сети нужно знать только IP-адреса, а их-то как раз и не хватает для обращения к серверам поддоменов и к серверу зоны, если он расположен в той же зоне. Для решения этой проблемы используются "приклеенные" (буквально "glue") записи типа "А". При этом вообще-то нет разницы что будет указано раньше использование доменного имени или определение соответствия этого имени IP-адресу.
Приведем пример записи типа A и использование "приклеенных" адресных записей. Во-первых, рассмотрим простую запись типа A:
$ORIGIN vega.ru. vega-gw IN A 194.226.43.1
В данном случае в зоне vega.ru определяется доменное имя для машины с IP-адресом 194.226.43.1. Для каждой машины зоны будет указана такая же запись.
Теперь рассмотрим возможность назначения "приклеенной" записи для сервера зоны для обращений по имени зоны, а не конкретной машины, что бывает полезно при настройке электронной почты.
$ORIGIN vega.ru. @ IN SOA vega-gw.vega.ru paul.kiae.su ( 101 ; serial number 86400 ; refresh within a day 3600 ; retry every hour 3888000 ; expire after 45 days 99999999 ) ; default ttl is set to maximum value IN NS vega-gw.vega.ru. IN A 194.226.43.1 ; vega-gw IN A 194.226.43.1
В данном примере при назначении сервера зоны в записи NS IP-адрес этого сервера еще не определен, но это и не суть важно, главное, чтобы он был определен далее в одной из адресных записей определения. Кроме этого, для обслуживания типа:
/usr/paul>mail paul@vega.ru
"приклеена" еще одна адресная запись, которая назначает текущему домену IP-адрес 194.226.43.1. Формально эта запись определяет адрес для, так называемых, запросов по неполному имени. В данном случае для всех запросов, которые используют имя зоны, определен адрес шлюза, на котором установлено обслуживание всех сервисов, например, http://vega.ru/ или gopher://vega.ru/. Обычно такой подход используют в маленьких сетях для упрощения работы с сервисами этих сетей [Tom Yager].
Другим примером "приклеенной" записи может служить делегирование зон внутри домена. Пусть мы создаем два поддомена zone1 и zone2, серверы которых также расположены в этих же поддоменах:
$ORIGIN vega.ru. @ IN SOA vega-gw.vega.ru paul.kiae.su ( 101 ; serial number 86400 ; refresh within a day 3600 ; retry every hour 3888000 ; expire after 45 days 99999999 ) ; default ttl is set to maximum value IN NS vega-gw.vega.ru. IN A 194.226.43.1 ; vega-gw IN A 194.226.43.1 ......... ; Glue address records. zone1-gw.zone1 IN A 194.226.43.2 zone2-gw.zone2 IN A 194.226.43.3 ; Subdomain delegation. zone1 IN NS zone1-gw.zone1.vega.ru. zone2 IN NS zone2-gw.zone2.vega.ru.
Данный пример - это расширение предыдущего примера. Сначала мы определили IP-адреса серверов поддоменов в рамках текущего домена, а потом определили их в качестве серверов соответствующих зон нашего домена. При разбиении домена на зоны не следует увлекаться. Запоминать и набивать длинные имена также трудно, как и числа IP-адреса.
Дополнительные необязательные поля
Как уже говорилось ранее, стандарт определяет еще два дополнительных поля: "Content-ID" и "Content-Description". Первое поле определяет уникальный идентификатор содержания, а второе служит для комментария содержания. Ни то, ни другое программами просмотра, обычно, не отображаются.
В заключении обсуждения стандарта MIME приведем комплексный пример без комментариев:
MIME-Version: 1.0 From: Nathaniel Borenstein <nsb@bellcore.com> Subject: A multipart example Content-Type: multipart/mixed; boundary=unique-boundary-1 This is the preamble area of a multipart message. Mail readers that understand multipart format should ignore this preamble. If you are reading this text, you might want to consider changing to a mail reader thatunderstands how to properly display multipart messages. --unique-boundary-1 ...Some text appears here... [Note that the preceding blank line means no header fields were given and this is text, with charset US ASCII. It could have been done with explicit typing as in the next part.] --unique-boundary-1 Content-type: text/plain; charset=US-ASCII This could have been part of the previous part, but illustrates explicit versus implicit typing of body parts. --unique-boundary-1 Content-Type: multipart/parallel; boundary=unique-boundary-2 --unique-boundary-2 Content-Type: audio/basic Content-Transfer-Encoding: base64 ... base64-encoded 8000 Hz single-channel u-law-format audio data goes here.... --unique-boundary-2 Content-Type: image/gif Content-Transfer-Encoding: Base64 ... base64-encoded image data goes here.... --unique-boundary-2-- --unique-boundary-1 Content-type: text/richtext This is <bold><italic>richtext.</italic></bold> <nl><nl>Isn't it <bigger><bigger>cool?</bigger></bigger> --unique-boundary-1 Content-Type: message/rfc822 From: (name in US-ASCII) Subject: (subject in US-ASCII) Content-Type: Text/plain; charset=ISO-8859-1 Content-Transfer-Encoding: Quoted-printable ... Additional text in ISO-8859-1 goes here ... --unique-boundary-1--
Подводя итоги обсуждения, еще раз следует отметить, что стандарт MIME позволяет расширить область применения электронной почты, обеспечить доступ к другим информационным ресурсам сети в стандартных форматах.
Серверы протокола HTTP
Сервер протокола http - это сердце Website. От того, насколько эффективно работает программа-сервер, зависят характеристики всего аппаратно-программного комплекса, реализующего Website.
Если проанализировать существующие программы этого типа, то можно легко убедиться в том, что основой большинства коммерческих и свободно распространяемых серверов является сервер NCSA 1.3R. На основе этого сервера разработаны такие популярные программы, как Netscape Enterprise Server, Internet Information Server (Microsoft), Apache и ряд других. Такая популярность NCSA httpd объясняется его функциональной полнотой и прозрачностью кода. Все изменения в этой программе были направлены на повышение эффективности кода, исправлению ошибок и повышению безопасности обмена данными.
Другой традиционный соперник NCSA - это сервер CERN. От этого сервера современные программы унаследовали возможность расширения за счет редактирования с ядром, т.е. модульную архитектуру, и возможность работы в режиме посредника и кэширующего сервера.
Рас уж речь зашла о свойствах серверов, то в настоящее время следует выделить три основных типа серверов:
простые, классические, серверы, серверы посредники, кэширующие серверы.
Защита сервера от несанкционированного доступа
Отдельное место при обсуждении протокола занимают вопросы, связанные с обеспечением защиты ресурсов сервера от несанкционированного доступа. Как было отмечено в предыдущих разделах, первоначально разработка защищенных способов обмена данными в системе World Wide Web не предполагалась. Однако быстрое развитие популярности системы привело к тому, что многие коммерческие организации стали устанавливать серверы HTTP на свои машины. Кроме этого, конфиденциальной информации много и в научно-исследовательских государственных организациях. Таким образом, возникла необходимость в разработке механизмов защиты информации для системы WWW.
Проблема защиты информации на Internet - это отдельная большая тема. В данном разделе мы рассмотрим только обеспечение безопасности при использовании серверов HTTP.
При обсуждении этой проблемы полезно вспомнить схему WWW-технологии (рисунок 3.26). Из этой схемы видно, что в этой технологии имеется как минимум две потенциальные "дыры" .
Первая связана с чтением защищенных текстовых файлов. Для решения этой задачи имеется достаточно много традиционных механизмов, встроенных в операционные системы. Проблема возникает, если администратор системы решит использовать для размещения WWW-файлов и FTP-архива одно и тоже дисковое пространство. В этом случае защищенные WWW-файлы окажутся доступными для "анонимного" FTP-доступа. Многие серверы разрешают создавать в дереве поддерживаемых ими документов "домашние" страницы пользователей с помощью методов POST и GET. Это значит, что пользователи могут изменять информацию на компьютере сервера. Данные, вводимые пользователем, передаются как тело ресурса при методе POST через стандартный ввод, а методе GET через переменные окружения. Естественно, что разрешение создания файлов на сервере протокола HTTP создает потенциальную опасность доступа к защищенной информации лиц, не имеющих права доступа к ней. Решается эта проблема путем создания специальных файлов прав пользователей сервера WWW.
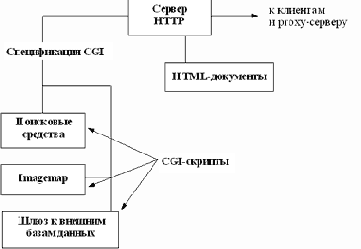
Рис. 3.28. Схема управления ресурсов сервером HTTP
Вторая возможность проникновения в компьютерную систему через сервер WWW связана с CGI-скриптами. CGI-скрипт - это программа, которую сервер HTTP может запускать для реализации механизмов, не предусмотренных в протоколе. Многие достаточно мощные информационные механизмы WWW реализованы посредством CGI-скриптов. К ним относятся: программы поиска по ключевым словам, программы реализации графических гипертекстовых ссылок - imagemap, программы сопряжения с системами управления базами данных и т.п. Естественно, что при этом появляется возможность получить доступ к системным ресурсам. Обычно внешняя программа запускается с идентификатором пользователя, отличным от идентификатора сервера. Данный идентификатор указывается при конфигурировании сервера. Наиболее безопасным здесь является идентификатор пользователя nobody (65534). Основная опасность скриптов заключена в том, что данные в скрипт посылаются программой-клиентом. Для того, чтобы в качестве параметров не передавали "подозрительных" данных, многие серверы производят проверку параметров на наличие допустимых символов. Особенно опасны скрипты для тех, кто использует сервер на персональном компьютере с MS-Windows 3.1. В этом случае файловая система практически не защищена. Одной из характерных для скриптов проблем является размер входных данных. Многие "умные" серверы обрезают слишком большие входные потоки и тем самым защищают скрипты от "поломки". Кроме перечисленных выше опасностей, порождаемых природой сети и системы WWW, существует еще одна, связанная с такой экзотикой, как мобильные коды. Мобильный код - это программа, которая может передаваться по сети для выполнения ее клиентом. Код встраивается в WWW-страницу при помощи тага <APP ...> - application. Например, Sun выпустила WWW-клиента HotJava, который позволяет интерпретировать язык Java. Существуют клиенты и для других языков, Safe-Tcl для Tcl, например. Главное назначение таких средств - реализация мультимедийных страниц и реализация работы в rеal-time. Опасность применения такого сорта страниц очевидна, так как повторяет способ распространения различного сорта вирусов. Однако пока речи о защите от такого сорта "взломов" не идет, видимо в силу довольно ограниченного применения данной возможности в сети.
Практически любой сервер имеет механизм назначения паролей и прав доступа для различных пользователей, который базируется на схеме идентификации протокола HTTP 1.0. Данная схема предполагает, что программа-клиент посылает серверу идентификатор пользователя и пароль. Понятно, что такой механизм не обеспечивает защиты передаваемой по сети информации, и она может стать легкой добычей злоумышленников.
Для того, чтобы этого не происходило, в рамках WWW ведется разработка других схем защиты. Они строятся на двух широко известных принципах: контроль доступа по IP-адресам и шифрация. Первый принцип реализован в программе типа "стена" (Firewall). Сервер разрешает обращаться к себе только с определенных IP-адресов и выполнять только определенные операции. Слабое место такого подхода с точки зрения WWW заключается в том, что обратиться могут через сервер-посредник, которому разрешен доступ к ресурсам защищенного первичного сервера. Поэтому применяют шифрование паролей и идентификаторов по аналогии с системой "Керберос". На принципе шифрования построен новый протокол SHTTP, который реализован в серверах Netsite (последние версии), Apachie и в новых серверах CERN и NCSA. Однако реально широкого применения это программное обеспечение еще не нашло и находится в стадии развития, а потому содержит достаточно большое количество ошибок.
Завершая обсуждение протокола HTTP и способов его реализации, нужно отметить, что в качестве широко доступного информационного ресурса WWW уже состоялась, следующий шаг - серьезные коммерческие применения. Но для этого необходимо еще внедрить в практику защищенные протоколы обмена, базирующиеся на HTTP. В последнее время появилось много новых программ, реализующих протокол HTTP. Это серверы и клиенты, написанные как для новых компьютерных платформ, так и для возможностей SHTTP. Реальную возможность попробовать свои силы в разработке различных WWW-приложений имеют и отечественные программисты.
Выбор, установка и настройка сервера
Если Website организуется на базе специально разработанной для этой цели платформы, то выбирать, что называется, не приходится. Чаще всего это будет либо Netscape Enterprise Server или Netscape Fastrack. Если речь идет об Windows NT, то в этом случае кроме продуктов Net-scape имеет смысл рассмотреть и IIS от Microsoft. В принципе это почти одно и то же.
Если же система устанавливается на произвольной платформе, то здесь выбор также не очень большой: сервер WN или Apache. WN - это самостоятельный продукт, который не использует код NCSA. До середины 1996 года это был пожалуй наилучший сервер. Однако, в настоящее время предпочтение следует все-таки отдать серверу Apache, который является развитием NCSA 1.3R в сторону построения модульной структуры и повышения безопасности обмена данными.
Тем не менее при рассмотрении установок и настроек мы будем параллельно описывать как тот, так и другой серверы.
Найти ftp-архив с дистрибутивом сервера не сложно. Для этого следует обратиться в каталог Yahoo (http://www.yahoo.com/) и там в разделе программного обеспечения серверов World Wide Web, можно найти адреса первоисточников. Если по каким-то причинам передача данных с сервера первоисточника происходит недостаточно быстро, то можно воспользоваться "зеркалами", которые расположены в пределах родного отечества. Ссылка на эти зеркала находится на домашней странице каждого сервера. Apache и WN имеются также и в ftp-архивах ftp.kiae.su и ftp.demos.su(ftp.ru).
После того как дистрибутив получен, его следует разархивировать и внимательно причитать файлы README, INSTALLATION, TODO. Как правило в составе дистрибутива есть скрипт configure( необходимо установить perl), который создает make-файл для компиляции и сборки сервера. Если в системе нет perl, и заниматься его установкой нет желания, то в этом случае надо отредактировать make-файл-источник для скрипта в соответствии с особенностями своей операционной системы. В данном случае имеется в виду Unix, т.к. для NT лучше воспользоваться уже собранным кодом.
В ряде случаев компилировать и собирать ничего не надо. Выполняемые модули для наиболее популярных платформ, как правило, уже есть в ftp-архиве. В этом случае надо только скопировать эти модули и документацию.
После того, как сервер собран или переписан, его устанавливают в то место файловой системы, где администратор предполагает его использовать. Наиболее популярное место - это директория /usr/local/etc/httpd. Но администратор может разместить сервер и в другом месте.
При размещении сервера в другом месте, следует отредактировать Makefile, если вы сами собирали сервер. В Makefile'е обычно есть переменная, которая определяет место расположения сервера и его служебных файлов. Кроме того, что эта переменная влияет на результат выполнения команды make install , по которой программное обеспечение сервера копируется в корневую директорию сервера, она же используется и для установки директории по умолчанию. В исполняемых модулях, которые получают по сети, именно /usr/local/etc/httpd указана в качестве такой директории по умолчанию.
Домашнюю директорию можно изменить не только при перекомпиляции, но и при запуске сервера. У сервера WN эта директория указывается в качестве последнего аргумента в командной строке:
/usr/paul>swn -p port [other options] /path/to/wn_root
При запуске apachie также можно указать корневую директорию:
/usr/paul>httpd -d /users/etc/httpd
Кроме сервера в корневой директории сервера могут располагаться еще служебные фалы и директории. Если для WN это условие не является обязательным, то при работе с Apache, для согласования его структур данных с сервером NCSA, надо создать еще несколько поддиректорий:
drwxr-xr-x 2 root wheel 512 Oct 11 07:01 cgi-bin drwxr-xr-x 2 root wheel 512 Oct 11 07:02 conf drwxr-xr-x 14 root wheel 1024 Oct 12 06:13 htdocs -rwxr-xr-x 1 paul wheel 21739520 Oct 11 07:37 htdocs.tar -rwxr-xr-x 1 root wheel 162003 Oct 11 07:16 httpd drwxr-xr-x 2 root wheel 2048 Oct 11 07:01 icons drwxr-xr-x 2 root wheel 512 Oct 11 07:19 logs drwxr-xr-x 2 root wheel 2560 Oct 11 07:01 src drwxr-xr-x 2 root wheel 512 Oct 11 07:01 support
Как видно из приведенного списка, это:
cgi-bin - для размещения скриптов SGI; conf - для размещения конфигурации сервера; htdocs - корень дерева website; icons - место размещения иконок; logs - место размещения журналов контроля доступа.
Другие файлы и директории не являются обязательными и могут быть опущены. При анализе листинга, указанного выше, обратите внимание на флаги прав доступа к файлам и директориям. Обязательным условием функционирования обоих серверов является наличие флагов "чтения" и "выполнения" для всех файлов и директорий, к которым сервер будет обращаться( "r-x"). Если файл выполнения не будет установлен, то это заблокирует ряд функций сервера, например, команды cd в рамках текущей директории, что приведет к отказам на обслуживание.
Запуск сервера из командной строки - это только один из двух способов его запуска. И сервер WN и сервер Apache можно запускать из сервиса inetd. Для этого в файл /etc/services следует внести следующую запись:
wn 80/tcp
А в файл настроек inetd (inetd.conf) следует внести строчку:
wn stream tcp nowait nobody /full/path/to/wn wn
Аналогичные изменения можно произвести и для Apache.
Если при установке сервера, не предполагается, что к нему будут обращаться по миллиону раз за сутки, то сервер можно запускать через inetd. Однако, этот способ не является распространенным. Чаще всего сервер запускают в режиме stand alone, т.е. просто в качестве демона, который обслуживает запросы от клиентов.
Если у сервера WN все параметры задаются, как правило, в командной строке, то Apache настраивается при помощи файлов настройки. Всего этих файлов три: httpd.conf, srm.conf, access.conf. Существует еще один файл - mime.conf, который определяет обработку файлов других форматов, отличных от текстовых файлов с HTML-документами.
Разберем содержание файла httpd.conf. Начинается файл с определения типа запуска сервера:
ServerType standalone
Опция ServerType в данном случае установлена в значение standalone, т.е. сервер запускается как демон.
Вслед за этим определяется номер TCP-порта, на котором сервер осуществляет обслуживание. Стандартным портом является 80 порт TCP. Однако, обслуживание можно заказать и на другом порте: Port 80
За этим определяется режим запроса имени хоста или IP-адреса, с которого осуществляется запрос к website: HostnameLookups on
Вслед за этой опцией определяется идентификатор пользователя и идентификатор группы, под которыми сервер осуществляет обслуживание запроса:
User nobody Group #-1
Здесь следует сделать небольшое пояснение. Дело в том, что для обслуживания каждого запроса сервер порождает процесс или поток (в зависимости от версии, производителя и операционной системы). При этом сам сервер стартует в момент запуска ОС и, следовательно, в этот момент имеет права администратора системы. Для того, чтобы эти права не получил обычный пользователь, в момент обслуживания запросов клиентов на каждый запрос порождается новый сервер, и уже этот сервер имеет права, которые определяются параметром User. Типичным пользователем, права которого доступны пользователю при доступе к Web-site, является пользователь nobody.
В файле конфигурации указывается и почтовый адрес администратора:
ServerAdmin paul@kiae.su
Этот адрес используется в сообщениях об ошибках, если ошибки происходят по вине администратора сервера или в сообщениях о перенаправлении запросов.
За почтовым адресом обычно следует определение корня Website. На этот корень будут опираться относительные адреса программного обеспечения. Данный адрес не надо путать с адресом корня страниц Website, который указывается далее:
ServerRoot /users/etc/httpd DocumentRoot /users/etc/httpd/htdocs
Далее определяется местоположение файлов сообщений об ошибках:
ErrorLog logs/error_log TransferLog logs/access_log PidFile logs/httpd.pid ScoreBoardFile logs/apache_status AccessConfig conf/access.conf ResourceConfig conf/srm.conf
Здесь же определяется параметр, по которому прекращается ожидание запроса от клиента:
Timeout 400
При стандартных настройках сервера ничего больше менять в файлах настройки не надо. Из всех параметров, которые еще могут быть указаны серверу важны только те, что определяют число запросов, которые может обслужить сервер-потомок, т.е. тот, который порождается на запрос пользователя, длительность сессии и виртуальные серверы, там же указываются параметры кэша и режим proxy(посредника). Ниже представлен фрагмент описания параметров кэш-сервера и сервера-посредника:
# Proxy Server directives. Uncomment the following line to # enable the proxy server: ProxyRequests On # To enable the cache as well, edit and uncomment the following lines: CacheRoot /users/etc/httpd/proxy СacheSize 5 CacheGcInterval 4 CacheMaxExpire 24 CacheLastModifiedFactor 0.1 CacheDefaultExpire 1 #NoCache olga.polyn.kiae.su
Далее в файле настроек можно определить дополнительные порты и IP-адреса сервера:
# Listen: Allows you to bind Apache to specific IP addresses and/or # ports, in addition to the default. See also the VirtualHost command Listen 3000 Listen 12.34.56.78:80
Кроме этого при организации сервера можно использовать так называемые hardware и software виртуальные-серверы:
# VirtualHost: Allows the daemon to respond to requests for more than one # server address, if your server machine is configured to accept IP packets # for multiple addresses. This can be accomplished with the ifconfig # alias flag, or through kernel patches like VIF. # Any httpd.conf or srm.conf directive may go into a VirtualHost command. # See alto the BindAddress entry. <VirtualHost host.foo.com> ServerAdmin webmaster@host.foo.com DocumentRoot /www/docs/host.foo.com ServerName host.foo.com ErrorLog logs/host.foo.com-error_log TransferLog logs/host.foo.com-access_log </VirtualHost>
При определении виртуальных серверов можно указывать любые команды, которые могут быть указаны и для описания главной базы данных. Вообще говоря, описания главной базы данных может и не быть, а могут быть определены только виртуальные серверы.
Следующий файл, который имеет прямое отношение к описанию базы данных -
access.conf: Ix: {13} cat access.conf # access.conf: Global access configuration # This file defines server settings which affect which types of services # are allowed, and in what circumstances. # Each directory to which Apache has access, can be configured with respect # to which services and features are allowed and/or disabled in that # directory (and its subdirectories). Originally by Rob McCool # This should be changed to whatever you set DocumentRoot to. <Directory /> # This may also be "None", "All", or any combination of "Indexes", # "Includes", "FollowSymLinks", "ExecCGI", or "MultiViews". # Note that "MultiViews" must be named *explicitly* --- "Options All" # doesn't give it to you (or at least, not yet). #Options Indexes FollowSymLinks ExecCGI Includes MultiViews Options All # This controls which options the .htaccess files in directories can # override. Can also be "All", or any combination of "Options", "FileInfo", # "AuthConfig", and "Limit" # AllowOverride None # Controls who can get stuff from this server. order allow,deny allow from all </Directory> # /usr/local/etc/httpd/cgi-bin should be changed to whatever your Scrip-tAliased # CGI directory exists, if you have that configured. <Directory /users/etc/httpd/cgi-bin> AllowOverride None Options None </Directory> # Allow server status reports, with the URL of http://servername/status # Change the ".nowhere.com" to match your domain to enable. #<Location /status> #SetHandler server-status #order deny,allow #deny from all #allow from .nowhere.com #</Location> # You may place any other directories or locations you wish to have # access information for after this one.
Данный файл определяет только основные принципы доступа к странице Website и способы работы со скриптами. Для каждой директории могут быть определены свои собственные права доступа и способы генерации страниц. Делается это либо добавлением новых предложений <Directory> и <Location> в данный файл, либо за счет создания в каждой директории файла описания прав доступа. В Apache - это файлы .access, а в WN - это файлы index. При этом принципы описания генерации страниц и доступа к ним в этих двух серверах совершенно разные. К генерации страниц мы вернемся немного позже, пока поговорим еще об одном файле описания настроек Apache - srm.conf. Мы обратим внимание на особенности представления страниц Website:
DocumentRoot /users/etc/httpd/htdocs UserDir public_html DirectoryIndex index.html FancyIndexing on AddIconByEncoding (CMP,/icons/compressed.gif) x-compress x-gzip AddIconByType (TXT,/icons/text.gif) text/* AddIconByType (IMG,/icons/image2.gif) image/* #... здесь определены другие иконы для разных типов файлов DefaultIcon /icons/unknown.gif ReadmeName README HeaderName HEADER # IndexIgnore is a set of filenames which directory indexing should ignore # Format: IndexIgnore name1 name2... IndexIgnore */.??* *~ *# */HEADER* */README* */RCS # AccessFileName: The name of the file to look for in each directory # for access control information. AccessFileName .htaccess # DefaultType is the default MIME type for documents which the server # cannot find the type of from filename extensions. DefaultType text/plain # AddEncoding allows you to have certain browsers (Mosaic/X 2.1+) uncompress # information on the fly. Note: Not all browsers support this. AddEncoding x-compress Z AddEncoding x-gzip gz Alias /icons/ /users/etc/httpd/icons/ ScriptAlias /cgi-bin/ /users/etc/httpd/cgi-bin/ # To use CGI scripts: AddHandler cgi-script .cgi # To use server-parsed HTML files AddType text/html .shtml AddHandler server-parsed .shtml # If you wish to use server-parsed imagemap files, use AddHandler imap-file map # To enable type maps, you might want to use AddHandler type-map var #AddHandler foot-action foot #Action foot-action /cgi-bin/footer # Or to do this for all HTML files, for example, use: #Action text/html /cgi-bin/footer # MetaDir: specifies the name of the directory in which Apache can find # meta information files. These files contain additional HTTP headers # to include when sending the document #MetaDir .web # MetaSuffix: specifies the file name suffix for the file containing the # meta information. #MetaSuffix .meta
В данном фрагменте многие опции остались в виде комментариев. Если их необходимо использовать, то просто надо убрать символ "#" из первой позиции строки.
Как видно из этих опций, в современных версиях серверов пользователю дается возможность выбора между внешними по отношению к серверу реализациям imagemap и модулем сервера, который реализует те же функции. Кроме того, сервер позволяет реализовать стандартные заголовок и окончание документа (header и footer).
В случае, когда для разных частей базы данных нужны заголовки страниц разного типа, пользуются так называемые server-side includes, т.е. вставки в тело документа, которые сервер делает перед тем как отправить документ программе-клиенту. Делается это при помощи HTML-комментариев типа:
<!-- #include file.html -->
При анализе документа, содержащего эту строку, вместо нее будет вставлено содержание файла file.html. Синтаксис таких предложений варьируется от сервера к серверу. Некоторые серверы, например WN, разрешают выполнять условные подстановки типа:
<!-- #if accept ~ "image/jpeg" --> <a href="picture.jpg"> Here is the jpeg version of picture.</a> <!-- #else --> <a href="picture.gif"> Here is the gif version of picture.</a> <!-- endif -->
В данном случае условная подстановка выполняется на основе анализа заголовка запроса программы-клиента, в котором есть список предложений Accept.
Пример заголовка запроса по протоколу HTTP 1.0.
GET /httpddoc/setup/startit.htm HTTP/1.0 Referer: http://144.206.192.101/httpddoc/Overview.htm User-agent: Mozilla/1.1N (Windows; 16bit) Accept: */* Accept: image/gif Accept: image/x-xbitmap Accept: image/jpeg
Последние четыре строки этого примера сообщают серверу форматы графических данных, которые могут быть отображены программой-интерфейсом Mozilla версии 1.1N (Mozilla - 16 разрядный интерфейс Netscape Communication для Windows 3.1).
Существуют и другие способы вставки файла в текст документа. Наиболее интересным из них является создание "скелета" документа, состоящего только из вставок. Необходимость в этом появляется например при создании печатной копии гипертекстовой базы данных.
Возможность ссылаться только на часть файла основана на механизме "зон" (ranges). Для того чтобы этот механизм работал, сервер должен понимать запросы типа: <http://host/dir/file;lines=20-30>. В этом случае в качестве ответа будут получены строки с 20-й по 30-ю, а не весь файл. Обычно, такую ссылку используют для работы с плоским текстом.
Еще одна важная особенность современных серверов - это фильтры, позволяющие выполнять некоторые подготовительные операции над файлом прежде, чем им займется сам сервер. Наиболее часто фильтры применяются для распаковки или преобразования графических файлов.
"Зоны" и фильтры не указываются и не прописываются разработчиком в телах документов базы данных сервера, а обычно настраиваются через файлы конфигурации сервера. Сервер NCSA, например, имеет специально выделенную директорию для своих файлов конфигурации. Аналогичную структуру имеет и популярный сервер для Windows 3.1 и
Windows NT - Winhttpd. Другие серверы, например WN, в каждом каталоге дерева базы данных имеют соответствующий файл конфигурации ресурсов.
Описание файлов со специальным назначением следует начинать с файла index.html, который предназначен для тех случаев, когда пользователь не указывает в своем запросе конкретный файл базы данных, а просто обращается к серверу или к одной из директорий:
http://polyn.net.kiae.su/
или http://www.w3.org/hypertext/
В этом случае по умолчанию обращение происходит к файлу index.html. Вообще говоря, таким файлом может быть любой другой файл, который будет назначен при конфигурировании вместо index.html, но это приведет к необходимости постоянно помнить о том, что на вашем сервере все не так как у всех остальных.
Важным свойством сервера является перенаправление запроса, когда в файле конфигурации появляется указание на другой файл. Все, кто пробовал работать с Line Mode Browser'ом, наверняка сталкивались со следующей ситуацией: на экран выдается странное сообщение "Сервер выполнил перенаправление запроса. Программа-клиент не умеет делать автоматический перевызов ресурса...". После подобной фразы предлагается выбрать одну из ссылок для перехода к требуемой WWW странице. До сих пор с этим приходится сталкиваться при обращении по адресу http://www.w3.org/ или http://info.cern.ch/. В данной ситуации происходит перенаправление запроса на другой ресурс, а так как программа просмотра Line Mode Browser или www не выполняет повторного запроса ресурса с новым адресом, то приходится делать его вручную. Вообще говоря, перенаправление чрезвычайно полезный механизм, при отсутствии которого во время перемещения страниц с одного сервера на другой в сети творилась бы жуткая неразбериха.
Кроме простого перенаправления существует еще одна интересная возможность переадресации запросов, связанная со временем хранения файла в базе данных. В заголовке HTTP существует предложение Refresh, которое заставляет клиента периодически, через определенный промежуток времени, без дополнительного требования со стороны пользователя, обращаться к серверу за новой копией файла. При этом сервер, например WN, имеет возможность перенаправить запрос к другому файлу базы данных. Используя этот механизм, можно организовать цикл из нескольких страниц, которые будут замещать друг друга. Применение такого механизма очевидно: рекламные ролики, галереи картинок, информационные доски. В сочетании с CGI-скриптами такой механизм дает возможность простыми средствами организовать довольно сложные динамические страницы.
Последним, о чем следует упомянуть в связи со структурой базы данных сервера WWW, являются файлы-индексы. Эти файлы не следует путать с index.html, используемым для доступа по укороченному URL. Главное назначение файлов-индексов - обеспечение поиска информации в базе данных WWW сервера по ключевым слова. Такие серверы как CERN httpd или WN имеют специальный модуль, который реализует функции поисковой машины. Сервер NCSA обычно настраивается на использование внешней поисковой машины, например WAIS, а индексный файл - это инвертированный список, где каждому слову ставится в соответствие список документов, где это слово встречается. Часто считают, что поиск по ключевым словам реализует полнотекстовый поиск по базе данных: однако это не так. Реально в файлы-индексы попадают только те слова, которые содержатся в части документа, предназначенной для построения индекса. Так многие серверы позволяют строить индексы по заголовкам документов, по специальным полям пользователя или по спискам ключевых слов, указанных в файле конфигурации. В принципе, существует возможность построения индекса с использованием полного текста документа, но при этом следует учитывать следующее: в полном тексте много общих слов, которые будут занимать место, но не прибавят точности поиску. При создании таких индексов база данных будет фактически продублирована, но только в другом формате.
Все серверы поддерживают возможность запуска внешних программ через спецификацию Common Gateway Interface. Обычно CGI скрипты расположены в специальной директории базы данных сервера. Однако, в ряде случаев, скрипт может храниться и в произвольном месте файловой системы. Сервер распознает скрипт либо по месту хранения, либо по расширению имени скрипта - как правило это "cgi". Как это определяется, мы видели из файлов настройки сервера Apfche.
Запись Mail eXchanger
Данная запись служит для определения адреса почтового сервера. Запись MX может быть определена как для всей зоны, так и для отдельно взятой машины. Запись MX имеет следующий формат:
[name] [ttl] IN MX [prference] [host]
Поле name определяет имя машины или домена, на который может отправляться почта. Это может быть как полностью определенное имя, так и частичное имя машины. Поле ttl обычно оставляют пустым. В поле preference указывается приоритет почтового сервера, указанного последним аргументом в поле данных MX-записи. Запись MX используется следующим образом:
почтовый агент, например, программа sendmail, который умеет работать со службой доменных имен получает от сервера доменных имен в ответ на свой запрос список MX-записей данного домена; в нем он ищет записи, которые позволяют переслать почту на машину, которая содержит почтовый ящик адресата, или на машину, которая знает как переслать почту по данному почтовому адресу; используя эту информацию, sendmail пересылает почту на найденную машину. При передаче, в данном случае, обычно используется протокол SMTP (Simple Mail Transfer Protocol).
Типичными примерами пересылки почты является работа с почтой UUCP и BITNET. Пересылка касается, как правило, уходящей из домена почты, которая не является проблемой данного домена. В файле настройки sendmail прописывается имя соответствующего шлюза и на этом все заканчивается. Но для российских сетей здесь возможны свои проблемы, которые связаны с переходом от старой почты UUCP, которая активно внедрялась сетью Relcom к системе работы по тому же протоколу, но уже через свой собственный домен. Однако более подробно на этой проблеме мы остановимся в разделе описания настроек программы sendmail.
Приведем пример использования записей MX:
$ORIGIN vega.ru. @ IN SOA vega-gw.vega.ru paul.kiae.su ( 101 ; serial number 86400 ; refresh within a day 3600 ; retry every hour 3888000 ; expire after 45 days 99999999 ) ; default ttl is set to maximum value IN NS vega-gw.vega.ru. IN NS ns.relarn.ru. IN NS polyn.net.kiae.su. IN A 194.226.43.1 IN MX 10 vega-gw.vega.ru. IN MX 20 ns.relarn.ru. IN MX 30 relay.relarn.ru. *.vega.ru. IN MX 0 vega-gw.vega.ru. ; vega-gw IN A 194.226.43.1 IN MX 0 vega-gw IN MX 10 ns.relarn.ru. IN MX 20 relay.relarn.ru.
В данном примере мы определили несколько записей типа MX для типов почтовой рассылки.
Записи в описании зоны, сразу после A-записи, следующей за записью SOA, определяют пути поступления почты в данный домен. Самый высокий приоритет здесь имеет прямая отправка почты на шлюз vega-gw.vega.ru. Если отправить почту на эту машину не удастся, то почтовый агент должен попробовать путь через почтовый сервер ns.relarn.ru . Если и этот путь окажется невозможным, то почту можно попытаться отправить на пересыльный пункт relay.relarn.ru . Такой порядок опроса почтовых серверов определяется полем preference - чем меньше значение поля, тем выше приоритет сервера в записи MX.
В нашем домене, который мы используем в качестве примера, большинство почтовых ящиков пользователей расположено на машине vega-gw.vega.ru. Для этой машины также указаны несколько записей MX. Наибольший приоритет среди них имеет запись с именем почтового сервера vega-gw. Обратите внимание на то, что данное имя не оканчивается точкой. Это значит, что оно расширяется именем текущей зоны. Все же другие имена серверов - это полностью определенные доменные имена (fully-qualified).
Кроме описанных MX-записей в нашем примере есть еще одна, которая определяет почтовый шлюз для нашего домена - запись с именем "*.vega.ru.". Данная запись введена для того, чтобы определить шлюз по умолчанию для любой машины из нашего домена, если для нее не определен шлюз в ее собственных MX-записях. Главным в этой записи является использование символа "*", который обозначает все возможные имена машин и поддоменов данного домена.
Обслуживание запросов
Обсудив структуру базы данных сервера, перейдем к обсуждению процедуры обслуживания запросов программ-клиентов World Wide Web. Существует два способа активации сервера: запуск в качестве "демона" или запуск через механизм inetd. В первом случае сервер осуществляет прослушивание 80-го порта TCP и запуск обслуживающей запросы части самостоятельно. При этом сервер может охватить одновременно несколько запросов. Во втором случае сервер инициируется программой обслуживания запросов по мере их поступления. Первый случай предпочтительней при большом количестве обращений со стороны программ-клиентов, второй более экономичный и требует меньшего количества системных ресурсов. После получения запроса сервер принимает запрос и приступает к разбору его заголовка, из которого сервер извлекает информацию о возможностях клиента, например, о его способности работы с графикой, определяет адреса клиента и, если необходимо, протоколы предварительной обработки информации. Эти данные используются сервером для анализа прав данного клиента по доступу и его возможностей по проведению подстановок и кодированию текста документа. После этого сервер выделяет из заголовка запрос на ресурс, определяет метод доступа к ресурсу и тип ресурса. Именно в этом месте принимается решение на запуск скрипта или перенаправление запроса. После выделения запроса на ресурс, сервер активирует программы предварительного преобразования данных (разархивирование, подстановки). После этого сервер начинает формирование ответа на запрос. В заголовке он указывает необходимые инструкции для клиента. Если происходит перенаправление запроса - Locate, если необходимо периодическое обновление - Refresh и т.п. Следует отметить, что результат работы скрипта также проходит обработку на сервере, который не подставляет дополнительной информации в заголовок ответа только в том случае, если скрипт полностью сформировал HTTP.
Вообще говоря, серверы являются относительно небольшими программами по сравнению с клиентами HTTP, например головной модуль сервера WN составляет всего 13911 байт кода на языке Си. Кроме самого сервера в комплект программного обеспечения, необходимого для организации базы данных World Wide Web, входят средства построения индексов и стандартный набор CGI скриптов, главным из которых является imagemap. Следует отметить, что не все серверы обслуживают графические стеки гипертекстовых ссылок через imagemap. Сервер WN, например, имеет встроенный модуль обработки таких ссылок. Данный разнобой осложняет перенос базы данных с одного сервера на другой и здесь затрачиваются основные усилия на модернизацию системы.
В заключение, хотелось бы отметить, что организация своей собственной базы данных WWW не является запредельно сложной задачей - в ftp архивах (ftp.kiae.su, ftp.funet.fi, ftp.sunet.se и др.) можно без труда найти все необходимое программное обеспечение. При этом следует принимать во внимание тот факт, что при запуске серверов часто требуется выполнять привилегированные операции, а это разрешено только администратору системы. Из всех серверов, которые мне пришлось устанавливать из исходных текстов, без дополнительных усилий собрался только WN: NCSA требовал некоторых изменений в Makefile, а CERN требовал установки дополнительной библиотеки общих кодов.
Запись назначения синонима каноническому имени "Canonical Name"
Запись CNAME определяет синонимы для реального доменного имени машины, которое определено в записи типа A. Имя в записи типа A называют каноническим именем машины. Формат записи CNAME можно определить следующим образом:
[nickname] [ttl] IN CNAME [host]
Поле nickname определяет синоним для канонического имени, которое задается в поле host.
Запись CNAME чаще всего используется для определения информационных сервисов Internet, которые установлены на машине. Следующий пример определяет синонимы, для компьютера, на котором установлены серверы протоколов http и gopher:
$ORIGIN polyn.net.kiae.su. olga IN A 144.206.192.2 www IN CNAME olga.polyn.kiae.su. gopher IN CNAME olga.polyn.kiae.su.
Как и в предыдущих примерах команда $ORIGIN введена только для определения текущей зоны. Две записи типа CNAME позволяют организовать доступ к серверам, используя имена распределенных информационных систем Internet, в рамках технологий которых работают данные серверы. Именно такие синонимы и используются при обращении к таким системам, как Yahoo (www.yahoo.com) или Altavista (www.altavista.digital.com). Правда при обращении к серверу протокола http, который является базовым для системы World Wide Web, изменение имени машины, с которой осуществляют обслуживание, может быть вызвано многими причинами: перенаправлением запроса на другой сервер, использование виртуального сервера и т.п. (см. раздел "Администрирование баз данных World Wide Web").
При использовании записей типа CNAME следует учитывать, что запись этого типа следует использовать очень аккуратно. Некоторые администраторы рекомендуют вообще от нее отказаться и если нужно еще одно имя, то лучше вообще указать еще одну A-запись для того же самого IP-адреса. В частности запись типа MX может присоединяться только к адресной записи. Если быть более точным, то просто не все почтовые агенты способны обрабатывать записи типа CNAME, т.к. это требует дополнительного обращения к серверу доменных имен. Приведем пример правильного и неправильного использования записи CNAME:
$ORIGIN polyn.net.kiae.su. olga IN A 144.206.192.2 IN MX 0 olga IN MX 10 ns.polyn.kiae.su. www IN CNAME olga.polyn.kiae.su. gopher IN CNAME olga.polyn.kiae.su.
В данном случае записи типа CNAME указаны правильно, т.к. не мешают переадресации почты на машину olga.polyn.kiae.su. Но если их поменять местами с записями типа MX, то скорее всего почта работать не будет:
$ORIGIN polyn.net.kiae.su. olga IN A 144.206.192.2 www IN CNAME olga.polyn.kiae.su. gopher IN CNAME olga.polyn.kiae.su. IN MX 0 olga IN MX 10 ns.polyn.kiae.su.
Это будет происходить по следующей причине. Почтовый агент для получения адреса машины абонента почтового сервера в ответ на свой запрос получит запись из базы данных сервера с именем этой машины. Если бы это была запись типа A, то по ней почтовый агент определяет IP-адрес машины-получателя или машины шлюза. Получив этот адрес агент организует взаимодействие по протоколу SMTP и отправляет почтовое сообщение получателю или в очередь почтового агента шлюза. Если же он получил в результате обращения к серверу доменных имен запись типа CNAME, то никакого IP-адреса в ней нет, а следовательно и организовать SMTP-соединение нельзя.
Сами серверы доменных имен для определения IP-адреса используют несколько обращений. Когда получен ответ на запрос, сервер анализирует тип полученной записи, если это запись типа A, то IP-адрес передается системе resolver, если же это запись типа CNAME, то сервер снова запрашивает удаленный сервер на предмет получения новой записи, но уже по новому имени, которое он берет из поля host записи типа CNAME. Если в качестве resolver используется программа named, которая работает как resolver (команда slave в файле named.boot), то в этом случае resolver умеет обрабатывать записи типа CNAME, но в большинстве случаев, как в уже рассмотренном нами случае с электронной почтой, многие системы, которые работают в качестве "мудрых" resolver'ов не умеют анализировать записи типа CNAME, что и заставляет использовать вместо них записи типа A. Кроме того последние имеют еще и то преимущество, что сокращается число запросов к серверу доменных имен, т.к. IP-адрес запрашивающая сторона получает с первой попытки.
В качестве еще одного примера использования записей типа CNAME приведем трассу получения IP-адреса для доменного имени ftp.netscape.com:
ftp.netscape.com. IN CNAME anonftp6.netscape.com. anonftp6.netscape.com. IN CNAME ftp22.netscape.com. ftp22.netscape.com. IN A 204.152.166.45
Как видно из примера при поиске IP-адреса для ftp.netscape.com локальный сервер доменных имен дважды получает в ответ на свой запрос запись типа CNAME.
Записи типа "Pointer"
До сих пор мы описывали записи, которые используются главным образом в файле обслуживающем "прямую" зону, т.е. запросы на получение IP-адреса по доменному имени. Но существует, как мы выяснили ранее, и запросы другого типа, когда необходимо по IP-адресу получить доменное имя. Для реализации ответов на эти запросы сервер ведет описание "обратной" зоны, база данных которой состоит, главным образом, из записей типа "Pointer" или P-записей. Формат записи имеет следующий вид:
[name][ttl] IN PTR [host]
Поле name задает номер. Это не реальный IP-адрес машины, а имя в специальном домене in-addr.arpa или в одной из его зон. Существует специальный формат записи имен этого домена. Так, например, машина vega.-gw.vega.ru, которая имеет адрес 194.226.43.1 должна быть описана в домене in-addr.arpa как 1.43.226.194.in-addr.arpa, т.е. адрес записывается в обратном порядке. Так как речь идет о доменной адресации, то разбиение на сети (подсети в данном случае) значения не имеет. Имена обрабатываются точно также, как и обычные доменные имена. Это значит, что систему доменных имен машин этого домена можно представить в виде:

Рис. 3.12. Пример структуры части домена in-addr.arpa
Как видно из рисунка, в данном случае не играет ни какой роли тип сети или разбиение на подсети. Согласно правилам описания доменов и зон в этих доменах, разделителем в имени, которое определяет подчиненное значение зоны в домене, является только символ ".". Согласно этому правилу подсети сети класса B (144.206.0.0) и сеть класса С (194.226.43.0) находятся на одном уровне иерархии в системе домена in-addr.arpa. Поэтому не надо комплексовать перед записями типа:
$ORIGIN 194.in-addr.arpa. 1.43.226 IN PTR vega-gw.vega.ru.
Однако следует признать, что соответствие "обратных" зон сетям - это общая практика описания "обратных" зон. Ведь здесь точно также надо делегировать зоны из "обратного" домена. А делается это, как правило, на основе разбиения сети на подсети или сети.
В качестве примера для нашей учебной зоны в файле named.boot определена "обратная" зона 43.226.194.in-addr.arpa:
@ IN SOA vega-gw.vega.ru paul.kiae.su ( 101 ; serial number 86400 ; refresh within a day 3600 ; retry every hour 3888000 ; expire after 45 days 99999999 ) ; default ttl is set to maximum value IN NS vega-gw.vega.ru. IN NS ns.relarn.ru. ; 1 IN PTR vega-gw.vega.ru. 4 IN PTR dos1.vega.ru. 5 IN PTR dos2.vega.ru 2 IN PTR zone1-gw.zone1.vega.ru. 3 IN PTR zone2-gw.zone2.vega.ru.
Из этого примера видно, что для "обратной" зоны указаны те же записи описания зоны, что и для "прямой". Кроме того, "обратную" зону вовсе не обязательно разбивать в соответствии с разделением "прямой" зоны. С точки зрения домена in-addr.apra все машины принадлежат одной зоне - 43.226.194.in-addr.arpa.
Другое дело машина с IP-адресом 127.0.0.1. С точки зрения домена in-addr.arpa, она принадлежит другой ветке иерархии, отличной от той, которой принадлежат все остальные машины. Поэтому для домена 127.in-addr.arpa на любой машине есть отдельный файл "обратной" зоны, хотя машина localhost, которой соответствует этот IP-адрес, обычно описывается в "прямой" зоне домена вместе с другими машинами.
Запись типа HINFO
Описание записи этого типа приводится здесь из соображений полноты представления стандартных записей описания зоны. В записи типа HINFO указывается тип компьютера (hardware) и тип операционной системы, установленной на этом компьютере. Запись имеет следующий формат:
[host][ttl] IN HINFO [hardware] [software]
Поле host определяет имя машины. Поле ttl обычно оставляют пустым. Поле hardware определяет тип аппаратуры, например, SUN-3/60 или IBM-PC/AT. Значение поля определяется согласно RFC "Assigned Numbers". Однако, т.к. развитие средств вычислительной техники и программного обеспечения идет очень быстро, то многие администраторы пишут произвольные названия как hard- так и software. Если в названии встречается пробел, то название должно записываться в кавычках. Отказ от использования этого типа записей вызван также и соображениями безопасности.
Запись определения информационных сервисов "Well Known Services"
Данная запись определяет наличие на машине так называемых "Well Known Servisces" (буквально - "хорошо известный сервис"). В данном случае речь идет о прикладных программах, которые обслуживают запросы по портам TCP и UDP до 1024 порта. Наиболее простой способ выяснить какие сервисы реально работают на машине с операционной системой UNIX - это обратиться к файлу /etc/services. Для каждой машины можно указать только две записи типа WKS: одну для TCP и одну для UDP. Формат записи выглядит следующим образом:
[host][ttl] IN WKS [address] [protocol] [services]
Поле host определяет имя машины. Поле address - IP-адрес машины. В поле protocol указывается протокол - TCP или UDP. В поле services перечисляются информационные сервисы, которые установлены на данной машине. Так как сервисов может быть много и потребуется продолжение записи на следующих строках, список сервисов можно записать в круглых скобках. При указании сервисов можно ссылаться только на те, которые описаны в файле /etc/services.
Запись типа WKS используется редко. Во-первых, все сервисы управляются не сервером доменных имен, а поэтому лишний раз их указывать в описании зоны равносильно фразе "масло масленое", во-вторых, мало какие программы умеют работать с этим типом записей и, в-третьих, это дополнительная информация для возможных "взломщиков", т.к. именно сервисы являются инструментом несанкционированного доступа.
Команды описания зоны
Кроме записей описания ресурсов, в файлах описания зоны используют еще две команды $INCLUDE и $ORIGIN. Первая команда используется для того, чтобы в файл описания зоны можно было включить содержание другого файла. Так рекомендуется поступать при описании больших зон, разбивая из на небольшие фрагменты. При этом имя включаемого файла должно быть описано либо полностью от корня файловой системы, либо оно будет привязано к директории, указанной в файле named.boot.
$INCLUDE my_zone.dsc
В этом случае используется файл /etc/namedb/my_zone.dsc, т.к. обычно команда directory определяет именно эту директорию для хранения файлов базы данных named.
$INCLUDE /etc/my_zone
В данном случае указан полный путь и именно он будет использоваться при доступе к файлу.
Команда $ORIGIN служит для определения имени текущего домена. В отличии от предыдущей команды, которая практически не используется, по крайней мере российскими провайдерами, $ORIGIN используется и весьма интенсивно. Типичным примером использования $ORIGIN является объявление зоны для "приклеенной" записи типа A:
@ IN SOA ns.vega.ru. ...... IN NS ns.vega.ru. IN NS ns.relarn.ru. $ORIGIN relarn.ru. ns IN A 194.226.130.1 $ORIGIN vega.ru. ns IN A 194.226.43.1 ; The rest of zone description. .......
В этом примере мы вынуждены были применить команду $ORIGIN дважды. Первый раз при определении "приклеенной" записи для ns.relarn.ru, а второй раз для того, чтобы вернуться к описанию домена vega.ru. Как будет показано в примерах описания файлов, такая практика - обычное дело при использовании named.
Файлы описания зоны
Собственно записи описания ресурсов не существуют сами по себе, они составляют файлы описания зоны. Эти файлы размещаются в директории, указанной в команде directory файла настройки программы named - named.boot.
Все эти файлы можно разделить на три категории: файлы описания "прямой" зоны, файлы описания "обратной" зоны и файл описания начальной загрузки базы данных для named.
Обычно, в описании зоны имеется один файл описания "прямой" зоны и не менее двух файлов описания "обратны"х зон. Наличие не менее двух файлов объясняется тем, что существует "обратная" зона для адреса 127.0.0.1 и "обратная" зона для каждой из сетей или подсетей выделенных для данного домена.
Файл начальной загрузки - cache-файл служит для того, чтобы программа named смогла начать общаться с другими серверами сервиса доменных имен, установленными в сети. В этом файле обычно указывают адреса root-серверов.
Для знакомства с содержанием этих файлов проще всего обратиться к примерам организации сервиса доменных имен для различного сорта локальных сетей, подключенных к Internet.
Администрирование серверов World Wide Web
Распределенная информационная гипертекстовая система World Wide Web является одним из самых популярных, если не самым популярным, ресурсом Internet. Простота поддержки баз данных Web и проста использования программ доступа к ресурсам Web привели к тому, что скорость установки Web-серверов такова, что их количество удваивается каждые 62 дня. Интегрированные мультипротокольные интерфейсы World Wide Web объединяют в себе не только средство просмотра Web, но и доступ к FTP-архивам и средство работы с электронной почтой.
Практически, мультипротокольные программы типа Netscape Navigator, Internet Explorer, Arena и т.п. стали стандартным интерфейсом доступа в Сеть. Кроме этого, для разработки самих страниц Web не требуется какого-то изощренного программного обеспечения. Достаточно иметь обычный текстовый редактор и уже можно разрабатывать не только информационные страницы, но и стандартные формы ввода информации. Все это подвигло разработчиков программного обеспечения заговорить о технологии World Wide Web, как о технологии, способной удовлетворить множеству требований разнообразных задач, которые встречаются в организации информационной системы корпорации. После того, как Sun объявила о возможности использования в World Wide Web мобильных кодов Java, то последние сомнения о возможности организации корпоративного информационного сервиса на основе технологии World Wide Web отпали, и вся концепция получила название Intranet.
Разберем историю проекта, архитектуру программного обеспечения и протоколы World Wide Web более подробно.
AltaVista
Наиболее интересным с точки зрения информационно-поискового языка в AltaVista является возможность расширенного поиска. Здесь стоит сразу выделить, что в отличии от многих систем AltaVista поддерживает одноместный оператор NOT. Кроме этого есть еще и оператор NEAR, который реализует возможность контекстного поиска, когда термины должны располагаться рядом в тексте документа. AltaVista разрешает поиск по ключевым фразам, при этом она имеет довольно большой словарь этих фраз. Кроме всего прочего, при поиске в АltaVista можно задать имя поля где должно встретиться слово. Это может быть гипертекстовая ссылка, applet, название образа, заголовок и ряд других полей. К сожалению, подробно процедура ранжирования в документации по системе не описана, но сказано, что ранжирование применяется как при простом поиске, так и при расширенном запросе.
Реально эту систему можно отнести к системе с расширенным булевым поиском.
- после нормализации лексики от запроса осталось только Best. Естественно, что при этом качество поиска было отвратительным. Однако, использование поиска по фразе как по единому целому, поставило требуемый документ на первое место в списке найденных.
Архитектура построения системы
От описания основных компонентов перейдем к архитектуре взаимодействия программного обеспечения в системе World Wide Web. WWW построена по хорошо известной схеме "клиент-сервер". На рисунке 3.25 показано, как разделены функции в этой схеме.
Программа-клиент выполняет функции интерфейса пользователя и обеспечивает доступ практически ко всем информационным ресурсам Internet. В этом смысле она выходит за обычные рамки работы клиента только с сервером определенного протокола, как это происходит в telnet, например. Отчасти, довольно широко распространенное мнение, что Mosaic или Netscape, которые безусловно являются WWW-клиентами, это просто графический интерфейс в Internet, является верным. Однако, как уже было отмечено, базовые компоненты WWW-технологии (HTML и URL) играют при доступе к другим ресурсам Mosaic не последнюю роль, и поэтому мультипротокольные клиенты должны быть отнесены именно к World Wide Web, а не к другим информационным технологиям Internet. Фактически, клиент - это интерпретатор HTML. И как типичный интерпретатор, клиент в зависимости от команд (разметки) выполняет различные функции. В круг этих функций входит не только размещение текста на экране, но и обмен информацией с сервером по мере анализа полученного HTML-текста, что наиболее наглядно происходит при отображении встроенных в текст графических образов. При анализе URL-спецификации или по командам сервера клиент запускает дополнительные внешние программы для работы с документами в форматах, отличных от HTML, например GIF, JPEG, MPEG, Postscript и т.п. Вообще говоря, для запуска клиентом программ независимо от типа документа была разработана программа Luncher, но в последнее время гораздо большее распространение получил механизм согласования запускаемых программ через MIME-типы.
Другую часть программного комплекса WWW составляет сервер протокола HTTP, базы данных документов в формате HTML, управляемые сервером, и программное обеспечение, разработанное в стандарте спецификации CGI. До самого последнего времени (до образования Netscape) реально использовалось два HTTP-сервера: сервер CERN и сервер NCSA. Но в настоящее время число базовых серверов расширилось. Появился очень неплохой сервер для MS-Windows и Apachie-сервер для Unix- платформ. Существуют и другие, но два последних можно выделить из соображений доступности использования. Сервер для Windows - это shareware, но без встроенного самоликвидатора, как в Netscape. Учитывая распространенность персоналок в нашей стране, такое программное обеспечение дает возможность попробовать, что такое WWW. Второй сервер - это ответ на угрозу коммерциализации. Netscape уже не распространяет свой сервер Netsite свободно и прошел слух, что NCSA-сервер также будет распространяться на коммерческой основе. В результате был разработан Apachie, который по словам его авторов будет freeware, и реализует новые дополнения к протоколу HTTP, связанные с защитой от несанкционированного доступа, которые предложены группой по разработке этого протокола и реализуются практически во всех коммерческих серверах.
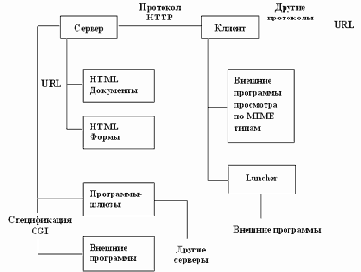
Рис. 3.25. Архитектура WWW-технологии
База данных HTML-документов - это часть файловой системы, которая содержит текстовые файлы в формате HTML и связанные с ними графику и другие ресурсы. Особое внимание хотелось бы обратить на документы, содержащие элементы экранных форм. Эти документы реально обеспечивают доступ к внешнему программному обеспечению.
Прикладное программное обеспечение, работающее с сервером, можно разделить на программы-шлюзы и прочие. Шлюзы - это программы, обеспечивающие взаимодействие сервера с серверами других протоколов, например ftp, или с распределенными на сети серверами Oracle. Прочие программы - это программы, принимающие данные от сервера и выполняющие какие-либо действия: получение текущей даты, реализацию графических ссылок, доступ к локальным базам данных или просто расчеты.
Все, что было сказано до этого момента, можно отнести к классической схеме World Wide Web. В настоящее время следует говорить об изменении общей архитектуры.
Как видно из рисунка 3.26, к середине 1996 года произошли некоторые изменения в архитектуре сервиса World Wide Web.
Произошел возврат к модульной структуре сервера World Wide Web. Этот возврат был реализован в виде спецификации API. API - это спецификация разработки прикладных модулей, которые встраиваются в сервер, точнее редактируются совместно с модулями сервера. Применение во всех серверах многопотоковой технологии выполнения подзадач делает такой способ расширения возможностей сервера более экономичным с точки зрения ресурсов вычислительной установки, чем разработка CGI-скриптов.
В дополнение к HTML активно стал применяться еще один язык разметки - VRML (Virtual Reality Modeling Language). В данном случае речь идет об описании трехмерных сен и возможности "бродить" по этим мирам. При этом в VRML также, как и в HTML предусмотрены гипертекстовые ссылки, что позволяет создавать смешанные базы данных, где информационный архив, например, можно представить в виде книг в библиотеке, среди которых может путешествовать автор, выбирая нужную ему тематику и источник, которые затем представляются в формате документа HTML.
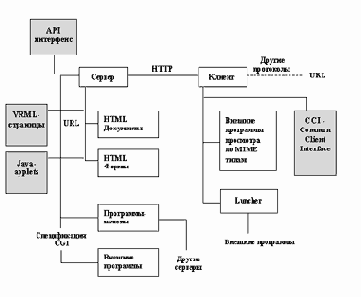
Рис. 3.26. Архитектура World Wide Web к середине 1996 года
Java-applet'ы - это мобильные коды Java, ссылки на которые вмонтированы в тело документа. При доступе к такому документу программа просмотра пользователя предварительно анализирует документ на предмет наличия в нем такого типа ссылок, и, если они существуют, то подкачивает мобильные коды в свою память. Коды могут сразу выполняться по мере размещения их на компьютере пользователя, но могут активироваться и при помощи специальных команд.
Как видно из рисунка, изменения коснулись и клиентской части технологии. В настоящее время происходит постепенный переход от простой классической архитектуры клиент-сервер к архитектуре с сервером приложений, в роли которого выступает программа-клиент. В частности, NCSA опубликовала спецификацию CCI (Common Client Interface) для разработки приложений для работы с сервисами World Wide Web через программу Mosaic.
Завершая обсуждение архитектуры World Wide Web хотелось бы еще раз подчеркнуть, что ее компоненты существуют практически для всех типов компьютерных платформ и свободно доступны в сети. Любой, кто имеет доступ в Internet, может создать свой WWW-сервер, или, по крайней мере, посмотреть информацию с других серверов.
Архитектура современных информационно-поисковых систем World Wide Web
Прежде чем описать проблемы построения информационно-поисковых систем Web и пути их решения, рассмотрим типовую схему такой системы (рисунок 3.41). В различных публикациях, посвященных конкретным системам[5,6], приводятся схемы, которые отличаются друг от друга только применением конкретных программных решений, но не принципом организации различных компонентов системы. Поэтому рассмотрим эту схему на примере представленном в [6]:
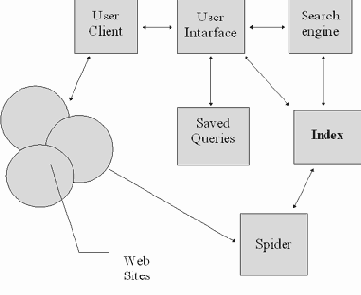
Рис. 3.41. Структура ИПС для Internet (Budi Yuwono, Dik L.Lee. Search and Ranking Algorims for Locating Resources on the World Wide Web)
На этой схеме обозначены:
База данных World Wide Web или Website
- набор страниц базы данных world Wide Web. При более подробном рассмотрении Website - это вся совокупность данных и программного обеспечения, обеспечивающая отображение страниц информационной базы данных World Wide Web.
Если страница Website представляет из себя обычный файл в стандарте HTML, то тогда говорят об элементарном или стандартном элементе хранения. В этом случае URL указывает непосредственно на этот файл и сервер просто отправляет его в ответ на запрос пользователя.
Многие страницы, как это было показано в разделе, посвященном языку HTML, содержат внутри себя контейнеры-формы, которые служат для передачи информации от программы клиента программе-серверу. В рамках данного рассмотрения эти страницы выделены в особую группу страниц World Wide Web.