Задача Grep
Каждая запись состоит из уникального ключа в первых 10 байтах и 90-байтной строки символов. Шаблон "XYZ" ищется в 90-байтном поле, и в каждых 10000 записей содержится одна такая подстрока. В каждом узле содержится 5,6 миллионов таких 100-байтных записей, или примерно 535 мегабайт данных. Общее число записей, обрабатываемых в кластере с заданным числом услов, составляет 5600000 × (число узлов).
В системах Vertica, СУБД-X, HadoopDB и Hadoop (Hive) выполнялся один и тот же SQL-запрос:
SELECT * FROM Data WHERE field LIKE ‘%XYZ%’;
Ни у одной из сравниваемых систем не было индекса на атрибуте символьной строки. Поэтому во всех системах требовалось полное сканирование таблицы, и производительность в основном органичивалась скоростью дисков.
В Hadoop (с кодированием вручную) это задание выполнялось в точности так же, как в (одна функция Map, сравнивающая подстроки с "XYZ"). В этом случае функция Reduce не требовалась, и результаты Map напрямую записывались в HDFS.
Планировщик HadoopDB SMS проталкивал раздел WHERE в экземпляры PostgreSQL.
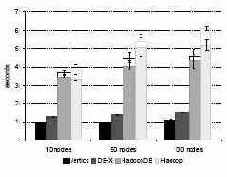
Рис. 5. Задача Grep
На рис. 5 показаны результаты (смысл столбцов с разрывом пояснялся в подразделе 6.1). Производительность HadoopDB немного выше, чем у Hadoop, поскольку наша система более эффективно производит ввод-вывод из-за отсутствия разбора данных во время выполнения. Однако обе системы проигрывают в производительности параллельным системам баз данных. Это объясняется тем, что и в Vertica, и в СУБД-X данные сжимаются, что существенно сокращает объем ввода-вывода (в отмечается, что во всех экспериментах сжатие данных приводило к ускорению СУБД-X почти на 50%).