Задача фильтрации
В первой задаче над структурированными данными таблица Rankings фильтруется по простому условию на атрибуте pageRank. Этому условию удовлетворяют примерно 36000 кортежей в каждом узле.
В системах Vertica, СУБД-X, HadoopDB и Hadoop (Hive) выполнялся один и тот же SQL-запрос:
SELECT pageURL, pageRank FROM Rankings WHERE pageRank > 10;
В Hadoop (с кодированием вручную) это задание выполнялось в точности так же, как в : функция Map разбирает кортежи Rankings с использованием поля-разделителя, применяет предикат на pageRank и помещает в результат pageURL и pageRank из кортежей, удовлетворяющих условию, в виде пара "ключ-значение". Функция Reduce в данном случае не требуется.
Планировщик HadoopDB SMS проталкивает разделы WHERE и SELECT в экземпляры PostgreSQL.
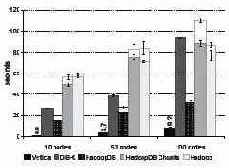
Рис. 6. Задача фильтрации
Производительность каждой системы показана на рис. 6. В Hadoop (с использованием и без использования Hive) применяется принцип грубой силы, полность сканируются все данные файла. Однако другие системы выигрывают от использования кластеризованных индексов на столбце pageRank. Поэтому в целом HadoopDB и параллельным системам баз данных удается превзойти HadoopDB по производительности.
Поскольку данные UserVisits разделяются по destinationURL, наличие связи по внешнему ключу между pageURL таблицы Rankings и destinationURL таблицы UserVisits приводит к тому, что Global Hasher и Local Hasher переразделяют Rankings по pageURL. Каждый чанк таблицы Rankings составляет всего 50 мегабайт (располагаясь совместно с соответствующим гигабайтным чанком таблицы UserVisits). Накладные расходы на планирование двадцати задач Map для обработки всего одного гигабайта данных на узел приводят к значительному снижению производительности HadoopDB.
Поэтому мы поддерживаем дополнительную, не разделенную на чанки копию таблицы Rankings, содержащую по одному гигабайту на узел. При работе с таким набором данных HadoopDB превосходит по производительности Hadoop, поскольку использование кластеризованного индекса по pageRank позволяет отказаться от последовательного сканирования всего набора данных. HadoopDB масштабируется лучше, чем СУБД-X и Vertica, в основном из-за возрастающих сетевых накладных расходов этих систем, которые выходят на первый план, когда время выполнения запроса в других отношениях является очень незначительным.