Задача агрегации с использованием UDF
В последней задаче для каждого документа из таблицы Documents нужно посчитать число входящих в него ссылок из других документов из той же таблицы. Для Hadoop и Vertica HTML-документы объединяются в более крупные файлы, каждый размером в 256 и 56 мегабайт соответственно. Система HadoopDB могла хранить каждый документ по отдельности в таблице Documents с использованием типа данных TEXT. СУБД-X обрабатывала по отдельности каждый файл с HTML-документом, как описывается ниже.
Теоретически в параллельных системах баз данных следовало бы иметь возможность использования определяемой пользователями функции F для разбора содержимого каждого документа и порождения списка всех URL, обнаруживаемых в документе. Затем можно было бы поместить этот список во временную таблицу и выполнить над ней простой запрос с COUNT и GROUP BY, подсчитывающий число вхождений каждого уникального URL.
К сожалению, как было установлено в , внутри используемых параллельных систем баз данных реализовать такую UDF было затруднительно. В СУБД-X отсутствовала возможность сохранения каждого документа в базе данных в виде символьного BLOB и определения UDF, работающей прямо с такими BLOB'ами, по причине "известной ошибки в [данной] версии системы". Поэтому UDF была реализована внутри СУБД, но данные хранились в отдельных HTML-документах во внешней файловой системе, и UDF производила требуемые внешние вызовы.
В Vertica в настоящее время UDF не поддерживаются, и поэтому пришлось написать на Java простой парсер документов, работающий вне СУБД. Этот парсер параллельно выполнялся в каждом узле, разбирая файл с конкатенированными документами и записывая в файл на локальном диске обнаруживаемые URL. Затем этот файл загружался во временную таблицу с использованием средства массовой загрузки Vertica, и выполнялся второй запрос, который подсчитывался число входящих ссылок.
В Hadoop мы использовали стандартное средство TextInputFormat, которое разбирало внутри задачи Map каждый документ и выводило список обнаруженных в нем URL. Функции Combine и Reduce суммировали число экземпляров каждого уникального URL.
Что касается HadoopDB, то поскольку текстовая обработка значительно проще выражается в MapReduce, мы решили воспользоваться той возможностью, что в HadoopDB допускаются запросы либо на SQL, либо в терминах MapReduce, и применили в данном случае второй вариант. Все содержимое таблицы Documents в каждом узле PostgreSQL передавалось в Hadoop с использованием следующего оператора SQL:
SELECT url, contents FROM Documents;
После этого данные обрабатывались с использованием задания MR. На самом деле, в Hadoop и HadoopDB использовался один и тот же код MR.
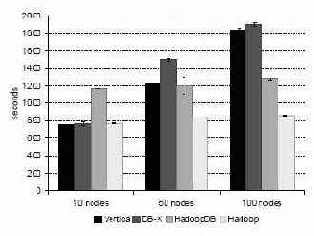
Рис. 10. Задача агрегации с применением UDF
Рис. 10 иллюстрирует преимущество использования гибридной системы, подобной HadoopDB. Уровень баз данных позволяет эффективно хранить текстовые HTML-документы, а среда MapReduce обеспечивает требуемую мощность их обработки.
Hadoop превосходит HadoopDB по производительности, если обрабатывает файлы, в которых склеено несколько HTML-документов. Однако в HadoopDB не утрачивается исходная структура данных, поскольку не требуется склейка файлов HTML-документов. Заметим, что общее время такой склейки составляет около 6000 секунд на узел. Эти накладные расходы на рис. 10 не учитываются.
Производительность СУБД-X и Vertica ниже, чем у систем, основанных на Hadoop, поскольку входные файлы хранятся вне базы данных. Кроме того, при решении этой задачи обе коммерческие СУБД не масштабируются линейным образом при увеличении числа узлов в кластере.
8 Диски EC2 медленно работают при начальной записи. Однако скорость записи не влияла на тестовые испытания производительности. Кроме того, до начала экспериментов диски инициализировались.